


Dans cet article, j'expliquerai en détail l'article "Pourquoi les modèles basés sur des arbres surpassent-ils toujours l'apprentissage profond sur les données tabulaires" Cet article explique un phénomène qui a été observé par les praticiens de l'apprentissage automatique du monde entier dans divers domaines - Phénomène. Les modèles basés sur les réseaux sont bien meilleurs pour analyser les données tabulaires que les réseaux d'apprentissage profond/neuraux.
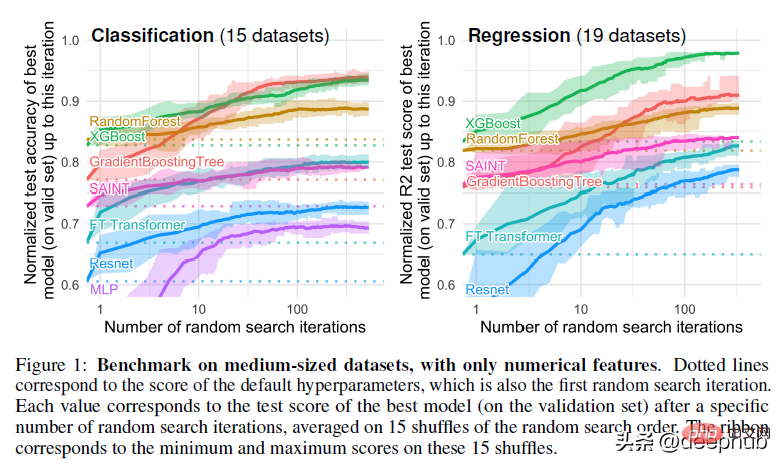
Ce papier a subi de nombreux prétraitements. Par exemple, des éléments tels que la suppression des données manquantes peuvent nuire aux performances de l'arborescence, mais les forêts aléatoires sont idéales pour les situations de données manquantes si vos données sont très désordonnées : elles contiennent de nombreuses fonctionnalités et dimensions. La robustesse et les avantages de la RF la rendent supérieure aux solutions plus « avancées », sujettes à des problèmes.

La majeure partie du reste du travail est assez standard. Personnellement, je n'aime pas appliquer trop de techniques de prétraitement, car cela peut entraîner la perte de nombreuses nuances de l'ensemble de données, mais les étapes suivies dans le document produisent essentiellement le même ensemble de données. Il est toutefois important de noter que la même méthode de traitement est utilisée lors de l’évaluation des résultats finaux.
L'article utilise également la recherche aléatoire pour le réglage des hyperparamètres. Il s'agit également de la norme de l'industrie, mais d'après mon expérience, la recherche bayésienne est mieux adaptée à la recherche dans un espace de recherche plus large.
En comprenant cela, nous pouvons approfondir notre question principale : pourquoi les méthodes basées sur les arbres surpassent l'apprentissage profond ?
C'est l'auteur qui partage que les réseaux de neurones d'apprentissage profond ne peuvent pas rivaliser avec l'aléatoire. Première cause de concurrence forestière. En bref, les réseaux de neurones ont du mal à créer la meilleure adéquation lorsqu’il s’agit de fonctions/limites de décision non fluides. Les forêts aléatoires réussissent mieux dans des modèles étranges/irréguliers/irréguliers.

Si je devais deviner la raison, il se pourrait que les dégradés soient utilisés dans les réseaux de neurones et que les dégradés reposent sur des espaces de recherche différentiables, qui par définition sont lisses, de sorte que les points pointus et certaines fonctions aléatoires ne peuvent pas être distingués. Je recommande donc d'apprendre des concepts d'IA tels que les algorithmes évolutifs, la recherche traditionnelle et des concepts plus basiques, car ces concepts peuvent conduire à d'excellents résultats dans diverses situations où NN échoue.
Pour un exemple plus concret de la différence dans les limites de décision entre les méthodes basées sur les arbres (RandomForests) et les apprenants profonds, jetez un œil à la figure ci-dessous -
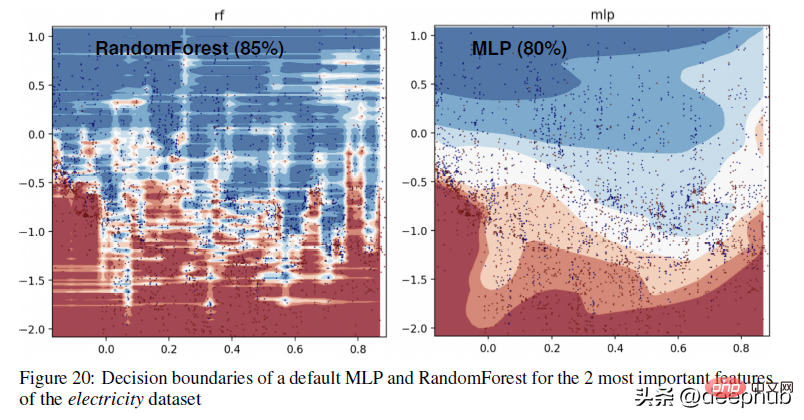
En annexe, l'auteur explique la visualisation ci-dessus ci-dessous :
Dans cette partie, nous pouvons voir que RandomForest est capable d'apprendre des motifs irréguliers sur l'axe des x (correspondant aux caractéristiques de date) que MLP ne peut pas apprendre. Nous montrons cette différence dans les hyperparamètres par défaut, qui est un comportement typique des réseaux de neurones, mais en pratique, il est difficile (mais pas impossible) de trouver des hyperparamètres qui apprennent avec succès ces modèles.
Un autre facteur important, en particulier pour les grands ensembles de données qui codent plusieurs relations simultanément. Si vous fournissez des fonctionnalités non pertinentes à un réseau de neurones, les résultats seront terribles (et vous gaspillerez plus de ressources pour entraîner votre modèle). C'est pourquoi il est si important de consacrer beaucoup de temps à l'exploration EDA/domaine. Cela aidera à comprendre les fonctionnalités et à garantir que tout se passe bien.
Les auteurs de l'article ont testé les performances du modèle lors de l'ajout de fonctionnalités aléatoires et de la suppression de fonctionnalités inutiles. Sur la base de leurs résultats, 2 résultats très intéressants ont été trouvés
La suppression d'un grand nombre de fonctionnalités réduit l'écart de performances entre les modèles. Cela montre clairement que l’un des avantages des modèles arborescents est leur capacité à juger si les fonctionnalités sont utiles et à éviter l’influence des fonctionnalités inutiles.
L'ajout de fonctionnalités aléatoires à l'ensemble de données montre que les réseaux de neurones se dégradent beaucoup plus gravement que les méthodes arborescentes. ResNet souffre particulièrement de ces propriétés inutiles. L'amélioration du transformateur peut être due au fait que le mécanisme d'attention qu'il contient sera utile dans une certaine mesure.
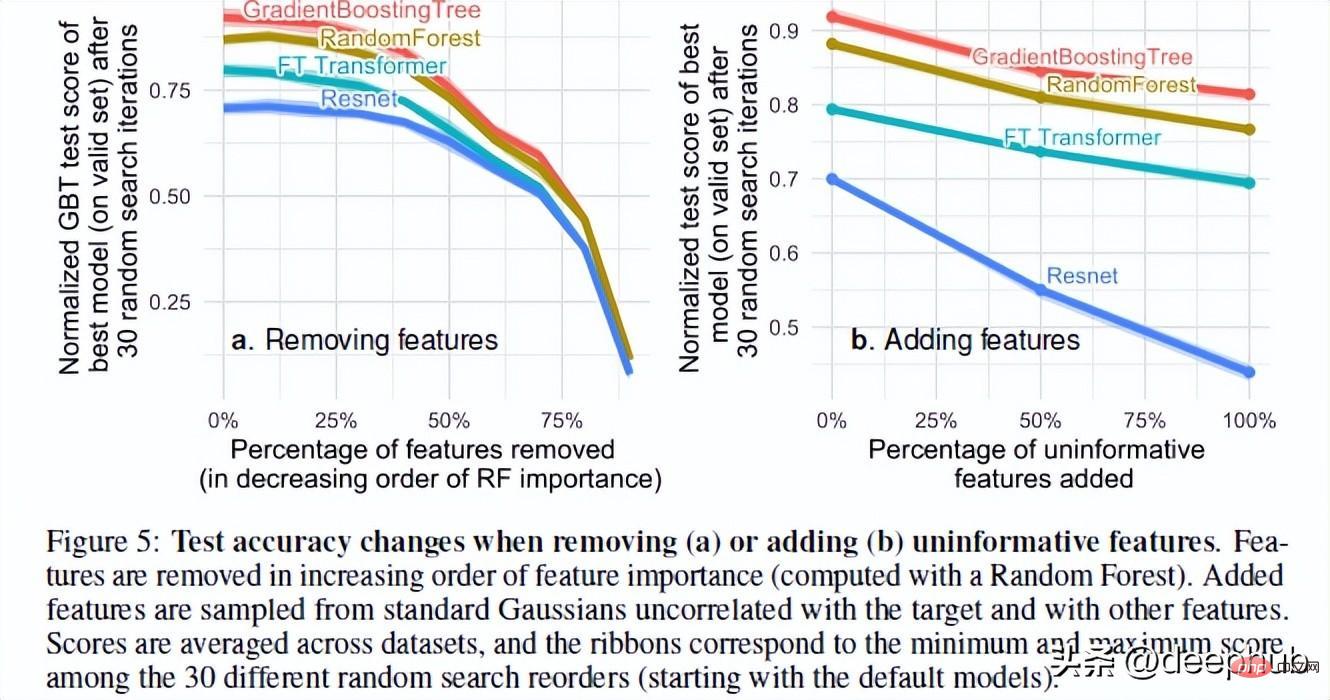
Une explication possible de ce phénomène est la façon dont les arbres de décision sont conçus. Quiconque a suivi un cours d'IA connaîtra les concepts de gain d'information et d'entropie dans les arbres de décision. Cela permet à l'arbre de décision de choisir le meilleur chemin en comparant les fonctionnalités restantes.
Retour au sujet, il y a une dernière chose qui rend RF plus performant que NN en ce qui concerne les données tabulaires. C'est l'invariance rotationnelle.
Les réseaux de neurones sont invariants par rotation. Cela signifie que si vous effectuez une opération de rotation sur vos ensembles de données, cela ne modifiera pas leurs performances. Après la rotation de l'ensemble de données, les performances et le classement des différents modèles ont considérablement changé. Bien que ResNets ait toujours été le pire, il a conservé ses performances d'origine après la rotation, tandis que tous les autres modèles ont considérablement changé.
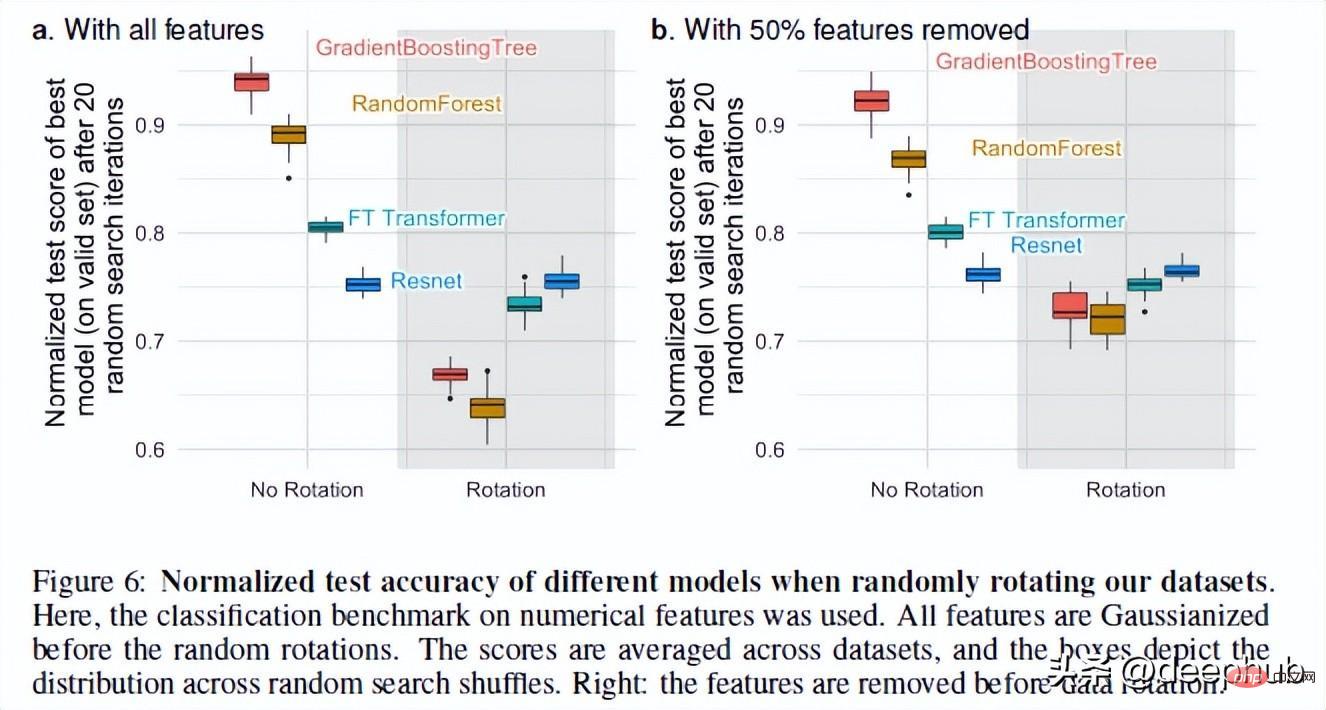
C'est un phénomène très intéressant : que signifie exactement la rotation d'un ensemble de données ? Il n'y a pas d'explications détaillées dans l'ensemble de l'article (j'ai contacté l'auteur et je suivrai ce phénomène). Si vous avez des idées, partagez-les également dans les commentaires.
Mais cette opération nous permet de voir pourquoi la variance de rotation est importante. Selon les auteurs, prendre des combinaisons linéaires de fonctionnalités (ce qui rend les ResNets invariants) peut en fait déformer les fonctionnalités et leurs relations.
L'obtention de biais de données optimaux en codant les données originales, qui peuvent mélanger des caractéristiques avec des propriétés statistiques très différentes et ne peuvent pas être récupérées par un modèle invariant par rotation, offrira de meilleures performances au modèle.
C'est un article très intéressant Bien que l'apprentissage profond ait fait de grands progrès sur les ensembles de données texte et image, il n'a fondamentalement aucun avantage sur les données tabulaires. L'article utilise 45 ensembles de données provenant de différents domaines pour les tests, et les résultats montrent que même sans tenir compte de leur vitesse supérieure, les modèles arborescents restent à la pointe de la technologie sur des données modérées (~ 10 000 échantillons).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



