


Cet article vous apporte des connaissances pertinentes sur les tableaux de données. Il partage principalement avec vous une méthode d'auto-équilibrage pour résoudre l'asymétrie des données. J'espère que cela sera utile à tout le monde.
Cet article décrit principalement la table de données d'application du système de jetons côté B pour résoudre le problème de l'augmentation du volume de données commerciales et de l'asymétrie des données existantes. Le scénario principal est le problème d'asymétrie des données un à plusieurs.
Décrivons brièvement le contexte commercial de B Token. Le système B Token est utilisé dans des scénarios marketing pour lier de nombreux utilisateurs à un jeton, puis le jeton se lie à une promotion pour parvenir à une différenciation. et un marketing précis. Généralement, le cycle de vie d'un token équivaut à cette promotion.
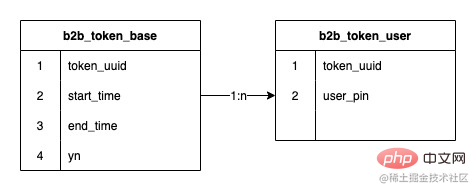
La relation entre les jetons et les utilisateurs de jetons est une relation un-à-plusieurs. Le premier système de jetons utilisait la sous-bibliothèque Jed, 2 fragments et une extension a été effectuée. au milieu A atteint 8 fragments et le nombre de lignes de données stockées a atteint 120 millions
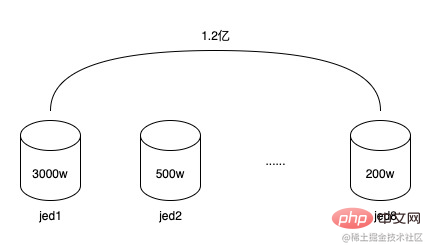
120 millions de données, réparties dans 8 sous-bases de données, chaque sous-base de données Le nombre moyen est de 15 millions, mais comme le champ de la sous-base de données utilise l'ID de jeton (token_uuid), certains utilisateurs de jetons sont peu nombreux, seulement quelques milliers à dix mille, et certains ont de nombreux utilisateurs de jetons, allant de 1 million à 1,5 million. Le nombre total de jetons n'est pas grand, seulement environ 20 000, donc les données sont faussées. Certaines sous-bases de données contiennent plus de 30 millions de données, et certaines n'en contiennent que quelques millions. Cela a commencé à conduire à un déclin. dans les performances de lecture et d'écriture de la base de données. Et comme la structure des données de la table de relation utilisateur-jeton est très simple, bien qu'il existe de nombreuses lignes de données, elle ne prend pas beaucoup de place. L'espace total occupé des 8 sous-bases de données est inférieur à 20G. Dans le même temps, le cycle de vie des jetons est fondamentalement le même que celui des promotions. Une fois qu'un jeton a servi une ou plusieurs promotions, il expirera lentement et sera supprimé, et de nouveaux jetons continueront à être créés à l'avenir. Ainsi, ces jetons expirés peuvent être archivés.
Dans le même temps, en raison du développement des activités côté B, il y a plus de demandes commerciales. Grâce à la communication avec l'entreprise, j'ai appris qu'un système de sélection automatique serait lancé à l'avenir. Le système créera automatiquement des jetons et. sélectionnez les personnes susceptibles d'être promues. Données pour chaque mois à l'avenir L'incrément est d'environ 30 millions. S'il dure un an, il augmentera de 360 millions. D'ici là, le volume moyen de données d'une seule table atteindra 60 millions. L’architecture de conception actuelle ne peut plus répondre aux besoins des entreprises.
Dans le même temps, il existe également une fonction permettant d'interroger les utilisateurs sous le jeton dans les pages en fonction de l'ID du jeton, mais elle ne concerne que les opérations côté gestion et n'est pas fréquemment utilisée.
Face à la baisse des performances de lecture et d'écriture de la base de données et aux besoins de croissance de l'entreprise, nous sommes actuellement confrontés aux problèmes suivants :
Comment résoudre le problème du trop grand nombre de lignes de données dans une seule table
La solution actuelle de sous-base de données présente de sérieuses distorsions de données
Si nous traitons de la croissance future des données
De manière générale, pour résoudre le premier problème, il s'agit généralement de partitionner des bases de données et des tables de partitionnement, mais nous avons maintenant 8 sous-bases de données, et 8 sous-bases de données n'occupent que moins de 20G d'espace, ce qui représente un gaspillage de ressources dans une seule base de données. C'est sérieux, donc je n'envisagerai pas du tout de continuer à ajouter des sous-bases de données, donc les sous-tables sont la solution.
Il existe généralement deux façons de diviser les données en tableaux : les tableaux verticaux et les tableaux horizontaux.
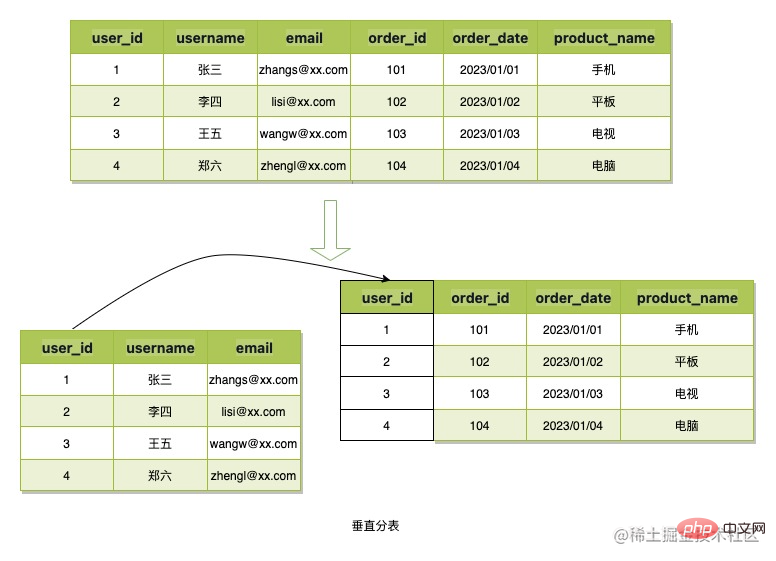
La division verticale des tables fait référence au fractionnement des colonnes de données, puis à l'application de clés primaires ou d'autres champs métier à associer, réduisant ainsi l'espace occupé par les données d'une table unique, ou réduisant le stockage redondant, structure de données du scénario de jeton B. simple et les données prennent peu de place, cette méthode de fractionnement de table ne sera donc pas utilisée.
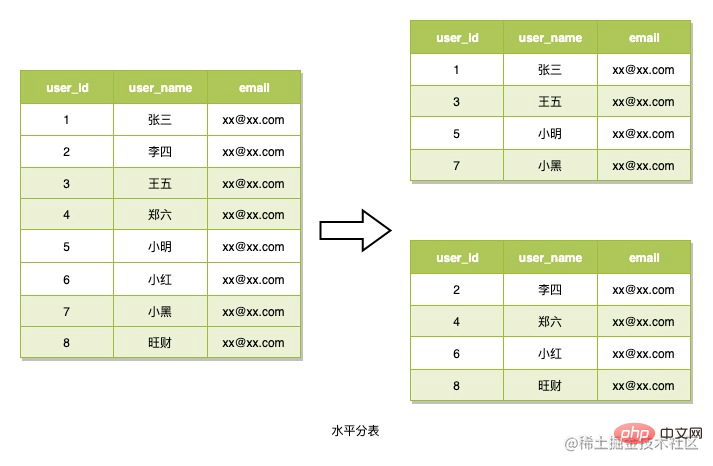
Le partitionnement de table horizontal fait référence à la division des lignes de données en plusieurs tables à l'aide d'un algorithme de routage. Les données sont également lues sur la base de cet algorithme de routage lors de la lecture. Cette stratégie de partitionnement de table est généralement utilisée pour traiter des scénarios de données dans lesquels la structure est. pas complexe mais il y a beaucoup de lignes de données. C'est ce que nous allons utiliser. Ce qu'il faut considérer lors de l'utilisation de cette méthode, c'est comment concevoir l'algorithme de routage. Cette méthode est également utilisée ici pour diviser les tables.
Il existe de nombreuses façons d'utiliser les algorithmes de routage de table de données dans l'industrie. La première consiste à utiliser lehachage de cohérencepour sélectionner le champ de partitionnement de table approprié, et la valeur après hachage de la valeur du champ est fixe. . Utilisez cette valeur pour obtenir un numéro de séquence fixe via une opération modulo ou bit à bit afin de déterminer dans quelle table les données sont stockées.
La plupart des applications les plus courantes telles que les sous-bases de données utilisent un hachage cohérent. En calculant instantanément la valeur du champ de la sous-base de données, il est déterminé à quelle sous-base de données appartiennent les données, puis décide à quelle sous-base de données stocker les données. dans ou lire les données. Si le champ de sous-base de données n'est pas spécifié lors de la requête, les requêtes de requête doivent être envoyées à toutes les sous-bases de données en même temps, et enfin les résultats sont résumés.
De plus, la structure de données HashMap comme le code Java est en fait une stratégie de partitionnement de table d'un algorithme de hachage cohérent, en hachant la clé, il est décidé quel numéro de série les données seront stockées dans le tableau n'utilise pas le modulo. méthode pour obtenir le numéro de série. , mais utilise des opérations au niveau du bit. Cette méthode détermine également que l'expansion de HashMap est basée sur la taille de 2 à la puissance x. J'introduireai ce principe lorsque j'en aurai l'occasion dans le futur.
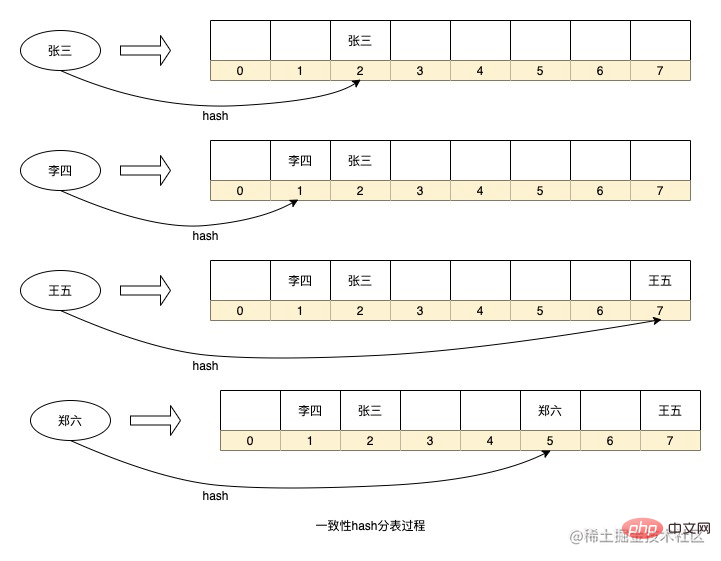
Ce qui précède est un processus simplifié de stockage de hachage de données dans HashMap. Bien sûr, j'ai omis certains détails. Par exemple, chaque nœud dans HashMap est une liste chaînée (trop de conflits se transformeront en un arbre rouge-noir). . Lorsqu'il est appliqué dans notre scénario, chaque numéro de série peut être considéré comme un tableau de données.
L'avantage de l'algorithme de routage ci-dessus est que la stratégie de routage est simple et qu'il n'est pas nécessaire d'ajouter de l'espace de stockage supplémentaire pour le calcul en temps réel. Cependant, il y a aussi un problème si vous souhaitez augmenter la capacité. Il est nécessaire de re-hacher les données historiques pour la migration. Par exemple, si la sous-base de données est ajoutée, la bibliothèque doit recalculer toutes les données dans des bibliothèques distinctes. L'expansion de HashMap effectuera également un rehachage pour recalculer le numéro de séquence de la clé dans le tableau. . Si la quantité de données est trop importante, ce processus de calcul prendra beaucoup de temps. Dans le même temps, s’il y a trop peu de tables de données ou si les champs choisis pour le partitionnement ont une faible discrétion, cela entraînera une distorsion des données.
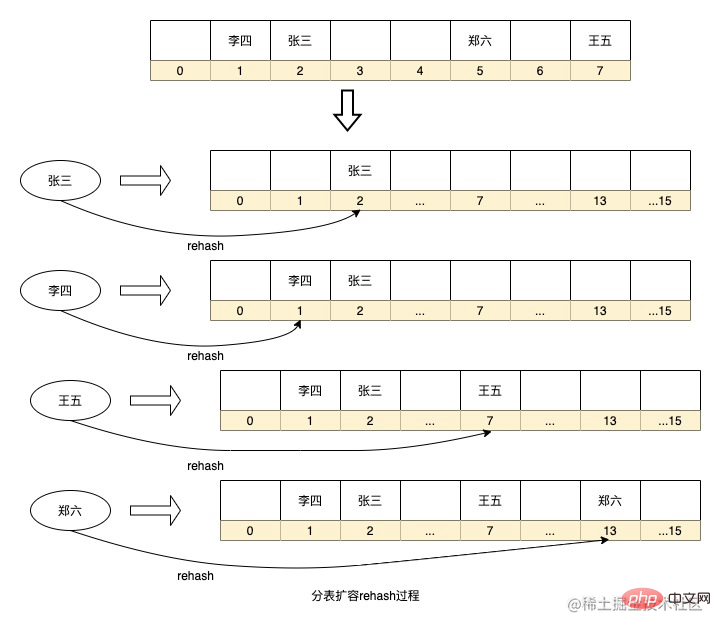
Il existe également un algorithme de fractionnement de table qui optimise ce processus de rehachage. Il s'agit de l'anneau de hachage cohérent. Cette méthode extrait de nombreux nœuds virtuels entre les nœuds d'entité, puis utilise l'algorithme de hachage cohérent pour rehacher les données. nœuds, et chaque nœud d'entité est en fait responsable des données des nœuds virtuels adjacents à l'autre nœud d'entité dans le sens inverse des aiguilles d'une montre du nœud d'entité. L'avantage de cette méthode est que si vous devez augmenter la capacité et ajouter des nœuds, le nœud ajouté sera placé n'importe où sur l'anneau et n'affectera qu'une partie des données des nœuds adjacents dans le sens des aiguilles d'une montre. les données du nœud doivent être migrées vers. Installez-les simplement sur ce nouveau nœud, ce qui réduit considérablement le processus de répétition. Dans le même temps, en raison du grand nombre de nœuds virtuels, les données peuvent également être réparties plus uniformément sur l'anneau. Tant que les nœuds physiques sont placés à l'emplacement approprié, le problème de distorsion des données peut être résolu dans la plus grande mesure possible. .
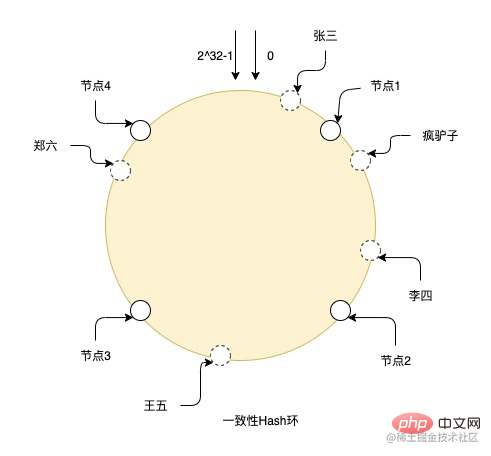
Par exemple, l'image montre le processus de hachage d'un anneau de hachage cohérent. Il y a des nœuds de 0 à 2 ^ 32-1 dans tout l'anneau. Les lignes pleines sont des nœuds réels et les autres sont des nœuds virtuels. Zhang San Après le hachage, il tombe sur le nœud virtuel sur l'anneau, puis recherche le nœud réel dans le sens des aiguilles d'une montre à partir de la position du nœud virtuel. Les données finales sont stockées sur le nœud réel, donc Crazy Donkey et Li Si sont stockés dessus. sur le nœud 2, et Wang Wu est sur le nœud 3. Sur, Zheng Liu est sur le nœud 4.
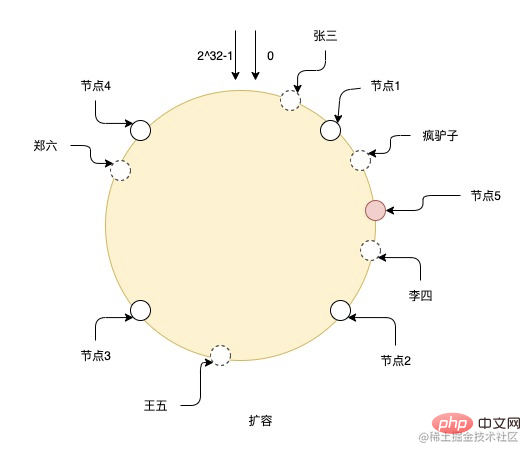
Après avoir développé un nœud n°5, les données entre le nœud 1 et le nœud 5 doivent être migrées vers le nœud 5, et les données des autres nœuds n'ont pas besoin d'être modifiées. Mais comme vous pouvez le voir sur la figure, l'ajout d'un seul nœud peut facilement conduire à des données inégales responsables de chaque nœud. Par exemple, le nœud 2 et le nœud 5 sont responsables de beaucoup moins de données que les autres nœuds, il est donc préférable d'étendre le nombre de nœuds. Il est préférable d’augmenter la capacité de manière exponentielle afin que les données puissent continuer à rester uniformes.
Retour au scénario commercial du jeton B, nous devons être en mesure de remplir les exigences suivantes
Tout d'abord, nous devons utiliser des sous-tableaux horizontaux pour résoudre le problème d'un volume de données excessif dans une seule table
Nécessite de prendre en charge les requêtes de pagination des utilisateurs basées sur des jetons
Étant donné que l'augmentation actuelle des données commerciales est de 30 millions, la possibilité d'une croissance continue de l'entreprise à l'avenir n'est pas exclue , le nombre de sous-tables doit pouvoir prendre en charge l'expansion future
Le nombre de lignes de données Il est trop élevé Il faut s'assurer qu'aucune migration de données n'est requise ou que le coût de migration des données est faible lors de l'expansion dans le. futur
Le problème de l'asymétrie des données doit être résolu pour garantir que les performances globales ne sont pas réduites en raison d'un volume de données excessif dans une seule table
Sur la base de l'appel ci-dessus, regardez tout d'abord la question b. Si vous souhaitez prendre en charge les requêtes de pagination des utilisateurs basées sur des jetons, vous devez vous assurer que tous les utilisateurs sous le jeton se trouvent sur la même table pour simplement prendre en charge les requêtes de pagination. Sinon, l'utilisation de certains algorithmes de résumé et de fusion sera trop complexe et trop nombreuse. les tables réduiront les performances des requêtes. Bien que la fonction de requête puisse également être fournie en utilisant des données hétérogènes, ce n'est que pour un petit nombre de requêtes de requête côté gestion que l'hétérogénéité des données est effectuée. Le coût est quelque peu élevé, mais les avantages ne sont pas évidents et c'est également un gaspillage. de ressources. Par conséquent, le champ de la sous-table ne peut être déterminé qu’à l’aide de l’ID du jeton.
Comme mentionné ci-dessus, le nombre d'identifiants de jetons n'est pas important et le nombre d'utilisateurs sous les jetons varie de 10 000 à 1 million. Le simple fait d'utiliser un hachage cohérent et l'utilisation des identifiants de jetons comme stratégie de partitionnement entraînera une distorsion des données sérieuse et. le coût de la migration des données sera très élevé lors de l’expansion future.
Cependant, l'utilisation d'un anneau de hachage cohérent conduira à la meilleure expansion future par un multiple de 2. Sinon, certains nœuds seront responsables de plus de nœuds virtuels, et certains nœuds seront responsables de moins de nœuds virtuels, ce qui entraînera des inégalités. données. Cependant, lors de la communication avec des collègues de base de données, le nombre de tables de données dans une base de données ne doit pas être trop élevé, sinon cela exercerait une forte pression sur la base de données. La méthode des anneaux de hachage cohérents pourrait augmenter la capacité de deux ou trois fois, ce qui entraînerait une augmentation de la capacité. nombre de sous-tables pour en atteindre une. Valeur très élevée.
Sur la base des problèmes ci-dessus, après avoir décidé d'utiliser l'ID de jeton comme sous-tableau, nous devons nous concentrer sur la façon deprendre en charge l'expansion dynamique et résoudre le problème de l'asymétrie des données.
Les champs de la sous-table ont été déterminés pour utiliser des identifiants de jeton, et comme mentionné précédemment. , notre structure de données est Cartes et les utilisateurs sont des données relationnelles un-à-plusieurs, donc le numéro de série de la sous-table haché lors de la création du jeton est stocké, et le routage ultérieur est basé sur le numéro de série de la sous-table stocké, ce qui peut garantir que l'expansion future n'affectera pas le routage des données existantes, aucune migration de données n'est requise.
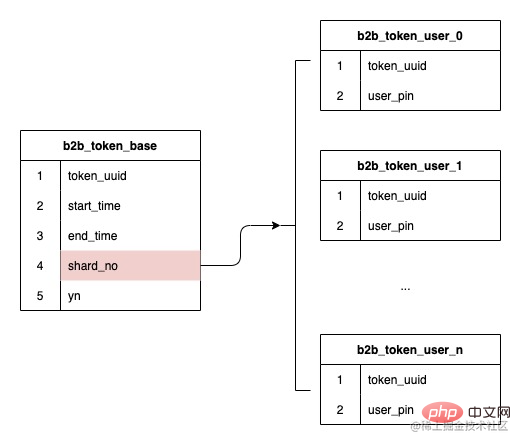
Étant donné que l'ID du jeton est sélectionné comme champ de sous-table et que la taille des données de chaque jeton est différente, l'asymétrie des données sera un gros problème. Nous essayons donc ici d’introduire le concept de niveau d’eau inférieur au mètre.

Lorsque l'utilisateur demande d'enregistrer ou de supprimer le nombre d'utilisateurs associés, une augmentation ou une diminution du nombre actuel de tables de partitions est effectuée en fonction du numéro de série de la table de partitions lorsque la quantité de données dans une certaine partition. Si la table fragmentée est à un niveau élevé, le nombre d'utilisateurs associés sera compté. La table fragmentée est éliminée de l'algorithme de partitionnement afin qu'elle ne continue pas à générer de nouvelles données.
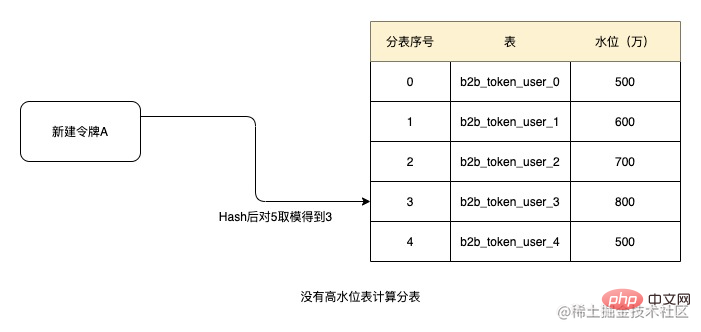
Par exemple, lors de la définition du seuil de 10 millions comme niveau d'eau élevé, puisqu'aucune des cinq tables ci-dessus n'a atteint le niveau d'eau élevé, lors de la création du jeton, hachez en fonction de l'ID du jeton, puis prenez le modulo pour obtenir 3, et obtenir les tables dans l'ordre, puis le numéro de sous-table actuel du jeton est b2b_token_user_3. Les données relationnelles ultérieures sont obtenues à partir de ce tableau.
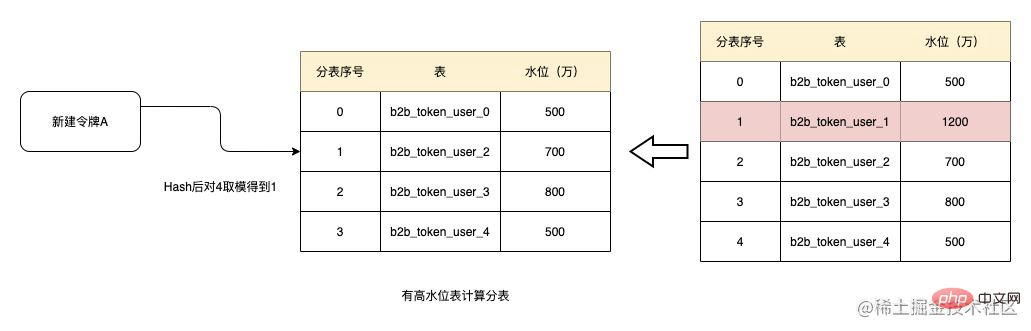
Après avoir fonctionné pendant un certain temps, le volume de données de la table b2b_token_user_1 a augmenté à 12 millions, dépassant le niveau d'eau de 10 millions. À ce moment, lors de la création du jeton, la table sera supprimée et la table sera supprimée. modulo sera 1 après Hash. Ensuite, la table actuellement attribuée est b2b_token_user_2. Et si le niveau d'eau de b2b_token_user_1 ne peut pas être abaissé, la table ne participera plus aux sous-tables à l'avenir et la quantité de données dans la table n'augmentera pas.
Bien sûr, il est possible que toutes les montres soient entrées dans le niveau d'eau élevé. Afin d'en être sûr, la fonction de niveau d'eau sera désactivée à ce moment et toutes les montres seront ajoutées au sous-tableau.
Si la quantité de données dans la table ne fait qu'augmenter plutôt que diminuer, alors tôt ou tard toutes les tables atteindront le niveau d'eau élevé, ce qui n'obtiendra pas d'effet dynamique. Comme mentionné dans le contexte ci-dessus, le jeton est créé pour servir un certain lot de promotions. Une fois la promotion terminée, le jeton perdra son effet. En même temps, le jeton a également une date d'expiration et les jetons qui dépassent cette date. la date d’expiration perdra également son effet. Par conséquent, l'archivage régulier des données peut permettre aux tables avec des niveaux d'eau élevés de baisser lentement leurs niveaux d'eau et de rejoindre les sous-tables.
Et le jeton actuel existe déjà dans une table b2b_token_user, contenant 120 millions de données. Vous pouvez utiliser cette table comme table 0 sur le diagramme, de sorte que lorsque vous vous connectez pour la première fois, il vous suffit de diviser tous les historiques. jetons. Enregistrez simplement le numéro de série de la table comme 0, et les données existantes n'ont pas besoin d'être migrées. Si le volume de données de cette table est élevé, elle ne participera pas à la sous-table. Couplé à un archivage régulier des données, le niveau d’eau de la table descendra petit à petit.
Bien que l'archivage régulier des données puisse abaisser le niveau d'eau de la table, avec le développement des affaires, la plupart des tables peuvent entrer dans le niveau d'eau élevé et toutes ont des données valides. À ce stade, le système se développera automatiquement, tout comme HashMap, lorsqu'il estime que la capacité atteint 75 %. Nous ne pouvons pas créer automatiquement de tables, mais lorsque 75 % des tables entrent dans le niveau d'eau élevé, une alarme sera émise. l'alarme et intervenir manuellement. L'observation nécessite un réglage. Si le niveau d'eau est élevé, il est préférable d'élargir la table.
•Seuil de niveau d'eau et surveillance de l'expansion
Actuellement, le seuil de niveau d'eau est toujours réglé manuellement. Sa taille est assez émotionnelle. Vous ne pouvez en définir qu'un et l'ajuster de manière appropriée après l'alarme. Cependant, en fait, le système peut surveiller automatiquement les fluctuations des performances de lecture et d'écriture de l'interface. On constate que lorsque la plupart des expressions atteignent un niveau élevé, les performances de lecture et d'écriture de l'interface ne changent pas de manière significative. augmentez automatiquement le seuil pour former un seuil intelligent.
Lorsqu'il y a un changement significatif dans les performances de lecture et d'écriture de l'interface et qu'il s'avère que la plupart des tables ont atteint le seuil, une alarme sera émise indiquant qu'une extension de capacité doit être envisagée.
Il n'y a jamais de solution miracle pour résoudre les problèmes. Nous devons utiliser les moyens techniques et les outils disponibles pour les combiner et les adapter à notre activité et à nos scénarios actuels. seulement Convient ou non.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Prix de la pièce U aujourd'hui
Prix de la pièce U aujourd'hui Dernières cotations Bitcoin
Dernières cotations Bitcoin Le système Hongmeng est-il facile à utiliser ?
Le système Hongmeng est-il facile à utiliser ? fichier_get_contents
fichier_get_contents Qu'est-ce qu'un portefeuille Bitcoin
Qu'est-ce qu'un portefeuille Bitcoin Avantages de pycharm
Avantages de pycharm À quel point Dimensity 9000 équivaut-il à Snapdragon ?
À quel point Dimensity 9000 équivaut-il à Snapdragon ? Quelles sont les technologies de base nécessaires au développement Java ?
Quelles sont les technologies de base nécessaires au développement Java ?























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



