


En 1946, le premier ordinateur électronique au monde est né à l'Université de Pennsylvanie aux États-Unis. ENICAC, Cet ordinateur est relativement lourd et sa vitesse de calcul n'est pas rapide, mais il représente l'arrivée de l'ère informatique et a une importance fondamentale dans le développement futur d'Internet.
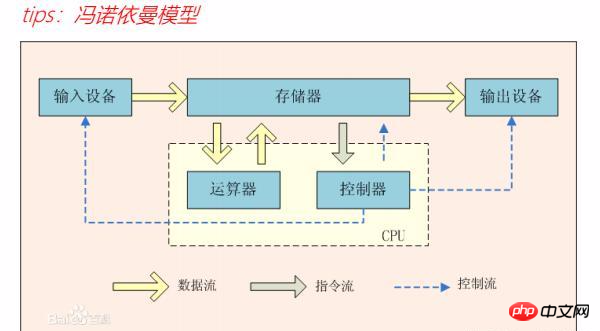
La composition d'un ordinateur est complétée en cinq parties, à savoir : le périphérique d'entrée, le périphérique de sortie, la mémoire. La mémoire contient des unités arithmétiques et des contrôleurs. Il existe un modèle de Von Neumann qui est un ordinateur objet très vivant. La composition a été décrite, mais l'ordinateur dispose également d'un flux de données, d'un flux d'instructions et d'un flux de contrôle pour effectuer des calculs et fonctionner normalement. Comme le montre l'image :
Après ENIAC, les ordinateurs électroniques entrent dans l'ère des mainframes dominés par IBM. En 1946, le premier IBM. mainframe La machine SYSTEM/360 est née, qui permet à IBM de dominer toute l'industrie des ordinateurs mainframe dans les années 1950 et 1960. À l'ère des mainframes, l'architecture informatique s'est développée dans deux directions : le CISC (jeu d'instructions de langage informatique exécuté par des microprocesseurs) et le CPU. Les architectures vont des PC personnels bon marché aux petits serveurs UNIX RISC (ordinateur à jeu d'instructions réduit) coûteux.
L'émergence des mainframes, avec leur puissance de calcul et leur puissance de traitement, leur stabilité et leur sécurité élevées, a longtemps guidé le développement du domaine informatique. Cependant, les systèmes informatiques centralisés ont posé certains problèmes et sont de moins en moins en mesure de répondre aux besoins des utilisateurs :
1. Les hébergeurs à grande échelle sont très chers et les petites entreprises ordinaires ne peuvent pas se les permettre.
2. Les mainframes sont plus complexes et le coût de la formation des talents est relativement élevé.
3. Problème ponctuel, tel qu'une panne du mainframe, l'ensemble du système sera en panne et incapable de fonctionner, entraînant d'énormes pertes pour l'entreprise.
4. Avec les progrès de la technologie, les performances des PC personnels sont de plus en plus élevées et le coût est de plus en plus bas.
Alibaba a lancé une campagne visant à éliminer « IOE » en 2009
IOE fait référence aux mini-ordinateurs d'IBM, aux bases de données d'Oracle et aux périphériques de stockage haut de gamme d'EMC. Le mouvement vers la suppression de l'IOE en 2009 s'est poursuivi jusqu'à ce que le dernier mini-ordinateur IBM d'Alipay soit hors ligne en 2003.
Pourquoi aller sur IOE
Alibaba utilisait Oracle pour sa base de données dans le passé et utilisait des mini-ordinateurs et des périphériques de stockage haut de gamme pour fournir un traitement et un stockage de données hautes performances services. À mesure que le volume d'affaires de l'entreprise augmente et que le nombre d'utilisateurs continue d'augmenter, l'architecture centralisée traditionnelle de la base de données Oracle rencontre des goulots d'étranglement lors de son expansion. Par rapport à Oracle et DB2 traditionnels, ils sont principalement centralisés. L'inconvénient est le manque d'évolutivité. L'expansion centralisée utilise principalement l'expansion vers le haut plutôt que l'expansion horizontale. Cela se produira tôt ou tard après une longue période.
Cluster
Le petit restaurant s'est avéré être un chef qui coupait et lavait les légumes, préparait les ingrédients et cuisiné tous les plats. Plus tard, quand il y avait plus de clients, un chef en cuisine était trop occupé, alors un autre chef a été embauché. Les deux chefs ont pu cuisiner les mêmes plats. La relation entre les deux chefs était un groupe.
Distribué
Afin de permettre au chef de se concentrer sur la cuisine et de réaliser le les plats sont parfaits, j'ai également embauché un chef d'accompagnement pour se charger de couper les légumes, de préparer les légumes et de préparer les ingrédients. La relation entre le chef et le chef d'accompagnement est partagée. Même un chef d'accompagnement est trop occupé. chef cuisinier pour préparer ces deux accompagnements. La relation entre enseignants et enseignants est un cluster. Par conséquent, il peut y avoir des clusters dans une architecture distribuée, mais clusters ne signifie pas distribué.
Nœud
Un nœud fait référence à un programme individuel qui peut compléter indépendamment un ensemble de logique selon un protocole distribué. Dans un projet spécifique, un nœud représente un processus sur le système d'exploitation.
Mécanisme de réplication
La réplication fait référence à la fourniture d'une redondance pour les données ou les services dans un système distribué.
La copie de données fait référence à la conservation des mêmes données sur différents nœuds. Lorsque les données sur un certain nœud sont perdues, les données peuvent être lues à partir de la copie. Les copies de données sont le seul moyen d'entraîner une perte de données dans les systèmes distribués.
La copie de service représente une solution à haute disponibilité dans laquelle plusieurs nœuds fournissent le même service et réalisent le service via la relation maître-esclave.
Middleware
Le middleware s'ajoute aux services fournis par le système d'exploitation et n'appartient pas à l'application. Il se situe entre les couches application et système pour les développeurs. Un type de logiciel qui gère facilement la communication, les entrées et les sorties, permettant aux utilisateurs de se soucier de cette partie de leur application.
Une architecture système de site Web mature à grande échelle n'est pas conçue parfaitement dès le début, et elle n'a pas non plus de hautes performances, de haute disponibilité, de sécurité et d'autres fonctionnalités dès le début , mais à mesure que le nombre d'utilisateurs augmente, l'expansion des fonctions commerciales s'améliore et évolue progressivement. Dans ce processus de développement, les modèles de développement, l'architecture technique, etc. subiront de grands changements.
Supposons que le système ait les fonctions suivantes :
Module utilisateur : enregistrement et gestion des utilisateurs
Module produit : affichage et gestion des produits
Module de transaction : Créer des transactions et règlement des paiements
Au début du système, l'application et la base de données sont placées sur un seul serveur.

À mesure que le nombre d'utilisateurs du site Web augmente, le trafic augmente, séparez le serveur d'applications et la base de données serveur Le déploiement de machines peut augmenter les performances du système, améliorer l'efficacité de l'accès et améliorer la capacité de charge et les capacités de reprise après sinistre d'une seule machine.
À mesure que le nombre de visites et le trafic augmentent, en supposant que la base de données ne rencontre pas de goulots d'étranglement, le cluster de serveurs d'applications sera utilisé pour décharger demandes et améliorer les performances du programme. Problèmes existants : qui transmettra la demande de l'utilisateur et comment gérer la session.
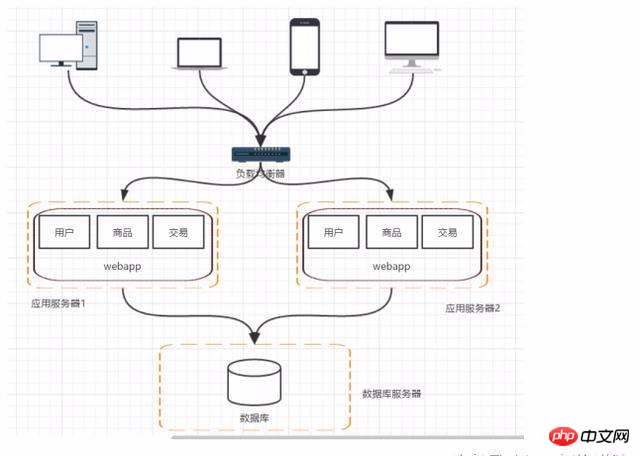
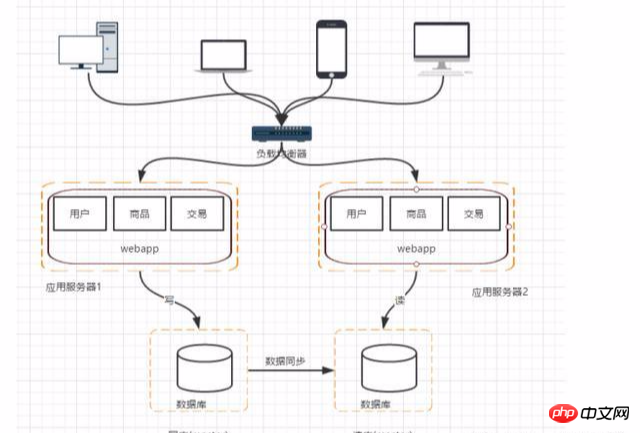
Si la lecture et l'écriture sont séparées, les requêtes et requêtes futures peuvent passer de la lecture les données de la bibliothèque et les données d'écriture peuvent être envoyées à la bibliothèque principale, mais cela entraînera plusieurs problèmes :
1. Synchronisation des données entre les bases de données maître et esclave : vous pouvez utiliser le maître-esclave fourni avec la méthode mysql. pour réaliser la réplication maître-esclave
2. Sélection de la source de données correspondante : utilisez un middleware de base de données tiers, par exemple : mycat
Lorsque les bases de données sont utilisées pour lire des bases de données, les performances des requêtes floues ne sont souvent pas très bonnes, en particulier pour les grandes sociétés Internet qui souhaitent effectuer des recherches pour les modules L'essentiel est que vous pouvez utiliser des moteurs de recherche. Bien que cela puisse améliorer considérablement la vitesse des requêtes, cela entraînera également certains problèmes tels que la construction d'index.
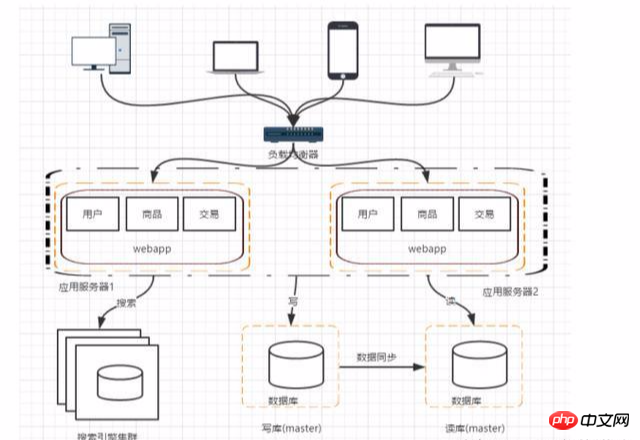
Pour certaines données chaudes, Redis et Memcache peuvent être utilisés comme cache de couche d'application ; en plus Dans certains scénarios, mongodb peut être utilisé à la place d'une base de données relationnelle pour le stockage.
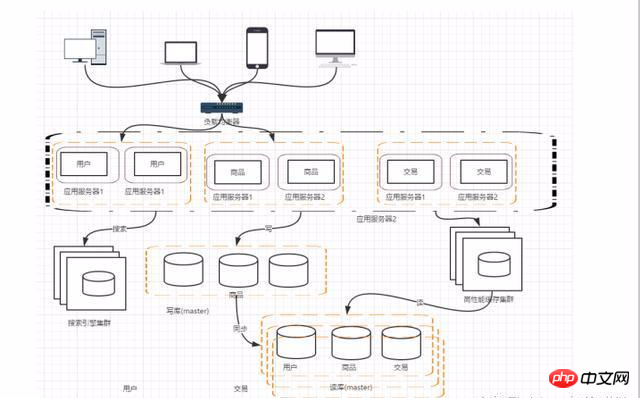
Phase 7 : Répartition horizontale/verticale de la base de données
Répartition verticale : diviser différentes données commerciales de la base de données en différentes données dans la base de données.
Répartition horizontale : divisez les données d'une même table en deux ou plusieurs bases de données. La raison de la répartition horizontale est que certaines entreprises disposant de grandes quantités de données ont atteint le goulot d'étranglement d'une seule base de données. vous pouvez diviser la table en plusieurs bases de données.

Avec le développement des affaires, il y a de plus en plus d'entreprises, et la pression sur les candidatures augmente. L'ampleur du projet devient également de plus en plus grande. À l'heure actuelle, vous pouvez envisager de diviser l'application et de diviser nos utilisateurs, produits et transactions en sous-systèmes selon le modèle de domaine.
Après la division de cette manière, il peut y avoir des codes identiques, tels que les opérations des utilisateurs et les requêtes de transactions de produits, qui conduiront tous à des requêtes d'utilisateurs et à des problèmes liés à l'accès dans chaque opération du système. Ces mêmes codes et modules doivent être abstraits. Cela facilite la maintenance et la gestion.
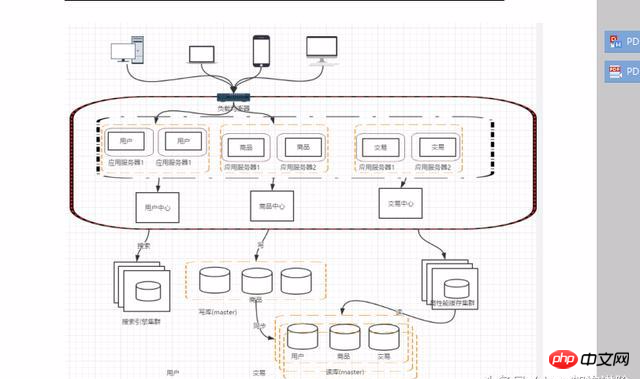
Une fois le service divisé, la communication entre les services peut se faire via la technologie RPC, les plus typiques incluent : webservice, hession, http, RMI, etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



