


Deep Learning, un puissant sous-ensemble d'apprentissage automatique, permet aux ordinateurs d'apprendre des exemples, reflétant l'apprentissage humain. Imaginez enseigner un ordinateur à identifier les chats - au lieu de définir explicitement les fonctionnalités, vous lui montrez d'innombrables images de chat. L'ordinateur identifie de manière autonome des modèles communs et apprend à reconnaître les chats. C'est le principe fondamental de l'apprentissage en profondeur.
Techniquement, l'apprentissage en profondeur exploite les réseaux de neurones artificiels, inspirés de la structure du cerveau humain. Ces réseaux comprennent les nœuds interconnectés (neurones) disposés en couches, en traitement des informations séquentiellement. Plus il y a de couches, plus le réseau «plus profond», permettant l'apprentissage de modèles de plus en plus complexes et l'exécution de tâches sophistiquées.

L'architecture inspirée du cerveau des réseaux de neurones
L'apprentissage automatique, lui-même une branche de l'intelligence artificielle (IA), permet aux ordinateurs d'apprendre des données et de prendre des décisions sans programmation explicite. Il englobe diverses techniques permettant aux systèmes de reconnaître les modèles, de prédire les résultats et d'améliorer les performances au fil du temps. Le deep Learning prolonge l'apprentissage automatique en automatisant les tâches nécessitant une expertise humaine.
Le Deep Learning se distingue par l'utilisation de réseaux de neurones avec trois couches ou plus. Ces réseaux tentent d'imiter la fonctionnalité du cerveau humain, apprenant de vastes ensembles de données.
L'ingénierie des fonctionnalités implique la sélection, la transformation ou la création des variables (fonctionnalités) les plus pertinentes à partir de données brutes à utiliser dans les modèles d'apprentissage automatique. Par exemple, dans la prédiction météorologique, les données brutes peuvent inclure la température, l'humidité et la vitesse du vent. L'ingénierie des caractéristiques détermine quelles variables sont les plus prédictives et les transforment (par exemple, convertir Fahrenheit en Celsius) pour des performances optimales du modèle.
L'apprentissage automatique traditionnel nécessite souvent l'ingénierie des fonctionnalités manuelles et longues, nécessitant une expertise du domaine. Un avantage clé de l'apprentissage en profondeur est sa capacité à apprendre automatiquement les fonctionnalités pertinentes à partir de données brutes, en minimisant l'intervention manuelle.
La domination du Deep Learning découle de plusieurs avantages clés:
Ce guide se plonge sur les concepts principaux de Deep Learning, vous préparant pour une carrière dans l'IA. Pour des exercices pratiques, considérons notre cours «Introduction à l'apprentissage en profondeur en python».
Avant d'explorer les algorithmes et les applications d'apprentissage en profondeur, il est crucial de comprendre ses concepts fondamentaux. Cette section présente les éléments constitutifs: réseaux de neurones, réseaux de neurones profonds et fonctions d'activation.
Le noyau de Deep Learning est le réseau neuronal artificiel, un modèle de calcul inspiré du cerveau humain. Ces réseaux sont constitués de nœuds interconnectés ("neurones") qui traitent en collaboration des informations et prennent des décisions. Semblables aux régions spécialisées du cerveau, les réseaux de neurones ont des couches dédiées à des fonctions spécifiques.
Un réseau neuronal "profond" se distingue par ses multiples couches entre l'entrée et la sortie. Cette profondeur permet l'apprentissage de fonctionnalités très complexes et de prédictions plus précises. La profondeur est la source du nom de Deep Learning et de sa puissance de résolution de problèmes complexes.
Les fonctions d'activation agissent en tant que décideurs dans un réseau neuronal, déterminant quelles informations se déroulent à la couche suivante. Ces fonctions introduisent la complexité, permettant au réseau d'apprendre des données et de prendre des décisions nuancées.
Deep Learning utilise l'extraction des fonctionnalités pour reconnaître des fonctionnalités similaires au sein de la même étiquette et utilise les limites de décision pour classer avec précision les fonctionnalités. Dans un classificateur de chat / chien, le modèle extrait des caractéristiques comme la forme des yeux, la structure du visage et la forme du corps, puis les divise en classes distinctes.
Les modèles d'apprentissage en profondeur utilisent des réseaux de neurones profonds. Un réseau neuronal simple a une couche d'entrée, une couche cachée et une couche de sortie. Les modèles d'apprentissage en profondeur ont plusieurs couches cachées, améliorant la précision avec chaque couche supplémentaire.
 Une simple illustration de réseau neuronal
Une simple illustration de réseau neuronal
Les couches d'entrée reçoivent des données brutes, en les faisant passer aux nœuds de calque cachés. Les couches cachées classent les points de données en fonction des informations cibles, rétrécissant progressivement la portée pour produire des prédictions précises. La couche de sortie utilise des informations de calque cachées pour sélectionner l'étiquette la plus probable.
S'attaquer à une question commune: l'apprentissage en profondeur est-il une forme d'intelligence artificielle? La réponse est oui. L'apprentissage en profondeur est un sous-ensemble d'apprentissage automatique, qui à son tour est un sous-ensemble de l'IA.
 La relation entre l'IA, ML et DL
La relation entre l'IA, ML et DL
L'IA vise à créer des machines intelligentes imitant ou dépassant l'intelligence humaine. L'IA utilise l'apprentissage automatique et les méthodes d'apprentissage en profondeur pour accomplir des tâches humaines. L'apprentissage en profondeur, étant l'algorithme le plus avancé, est une composante cruciale des capacités de prise de décision de l'IA.
Deep Learning propose de nombreuses applications, des recommandations de films Netflix aux systèmes de gestion des entrepôts d'Amazon.
La vision par ordinateur (CV) est utilisée dans les voitures autonomes pour la détection d'objets et l'évitement des collisions, ainsi que la reconnaissance du visage, l'estimation de la pose, la classification de l'image et la détection des anomalies.
 Reconnaissance du visage propulsé par l'apprentissage en profondeur
Reconnaissance du visage propulsé par l'apprentissage en profondeur
ASR est omniprésent dans les smartphones, activé par des commandes vocales comme "Hé, Google" ou "Salut, Siri". Il est également utilisé pour le texte vocable, la classification audio et la détection d'activité vocale.
 Reconnaissance du modèle de la parole
Reconnaissance du modèle de la parole
L'IA générative, illustrée par la création de Cryptopunks NFTS et du modèle GPT-4 d'OpenAI (alimentation ChatGPT), génère de l'art synthétique, du texte, de la vidéo et de la musique.
 Art génératif
Art génératif
Le Deep Learning facilite la traduction du langage, la traduction photo-texte (OCR) et la traduction du texte à image.
 Traduction linguistique
Traduction linguistique
Le Deep Learning prédit les accidents de marché, les cours des actions et les conditions météorologiques, cruciaux pour les industries financières et autres.
 Prévision des séries chronologiques
Prévision des séries chronologiques
Deep Learning automatise les tâches, telles que la gestion des entrepôts et le contrôle robotique, permettant même à l'IA de surpasser les joueurs humains dans les jeux vidéo.
 Bras robotique contrôlé par l'apprentissage en profondeur
Bras robotique contrôlé par l'apprentissage en profondeur
Deep Learning traite les commentaires et les applications de chatbot des clients pour le service client transparent.
 Analyse des commentaires des clients
Analyse des commentaires des clients
Les aides d'apprentissage en profondeur dans la détection du cancer, le développement de médicaments, la détection des anomalies en imagerie médicale et l'assistance des équipements médicaux.
 Analyse des séquences d'ADN
Analyse des séquences d'ADN
Cette section explore divers modèles d'apprentissage en profondeur et leurs fonctionnalités.
L'apprentissage supervisé utilise des ensembles de données étiquetés pour former des modèles de classification ou de prédiction. L'ensemble de données comprend des fonctionnalités et des étiquettes cibles, permettant à l'algorithme d'apprendre en minimisant la différence entre les étiquettes prévues et réelles. Cela comprend les problèmes de classification et de régression.
Les algorithmes de classification catégorisent des données basées sur des fonctionnalités extraites. Les exemples incluent Resnet50 (classification d'image) et Bert (classification du texte).
 Classification
Classification
Les modèles de régression prédisent les résultats en apprenant la relation entre les variables d'entrée et de sortie. Ils sont utilisés pour l'analyse prédictive, les prévisions météorologiques et la prédiction boursière. LSTM et RNN sont des modèles de régression populaires.
 Régression linéaire
Régression linéaire
Les algorithmes d'apprentissage non supervisés identifient les modèles dans des ensembles de données non marqués et créent des clusters. Les modèles d'apprentissage en profondeur apprennent des modèles cachés sans intervention humaine, souvent utilisés dans les systèmes de recommandation. Les applications comprennent le regroupement des espèces, l'imagerie médicale et les études de marché. Le regroupement intégré profond est un modèle commun.
 Clustering de données
Clustering de données
RL implique des comportements d'apprentissage des agents d'un environnement à travers des essais et des erreurs, maximisant les récompenses. RL est utilisé dans l'automatisation, les voitures autonomes, le jeu et l'atterrissage des fusées.
 Cadre d'apprentissage du renforcement
Cadre d'apprentissage du renforcement
Gans utilise deux réseaux de neurones (générateur et discriminateur) pour produire des instances synthétiques de données d'origine. Ils sont utilisés pour générer de l'art synthétique, de la vidéo, de la musique et du texte.
 Cadre de réseau adversaire génératif
Cadre de réseau adversaire génératif
Les GNN fonctionnent directement sur des structures de graphiques, utilisées dans les grandes analyses de données, les systèmes de recommandation et la vision informatique pour la classification des nœuds, la prédiction des liens et le clustering.
 Un graphique dirigé
Un graphique dirigé
 Un réseau graphique
Un réseau graphique
La PNL utilise l'apprentissage en profondeur pour permettre aux ordinateurs de comprendre le langage humain, le traitement de la parole, du texte et des images. L'apprentissage du transfert améliore la PNL par des modèles affinés avec un minimum de données pour obtenir des performances élevées.
 Sous-catégories de PNL
Sous-catégories de PNL
Les fonctions d'activation produisent des limites de décision de sortie, améliorant les performances du modèle. Ils introduisent la non-linéarité aux réseaux. Les exemples incluent Tanh, Relu, Sigmoïde, linéaire, softmax et swish.
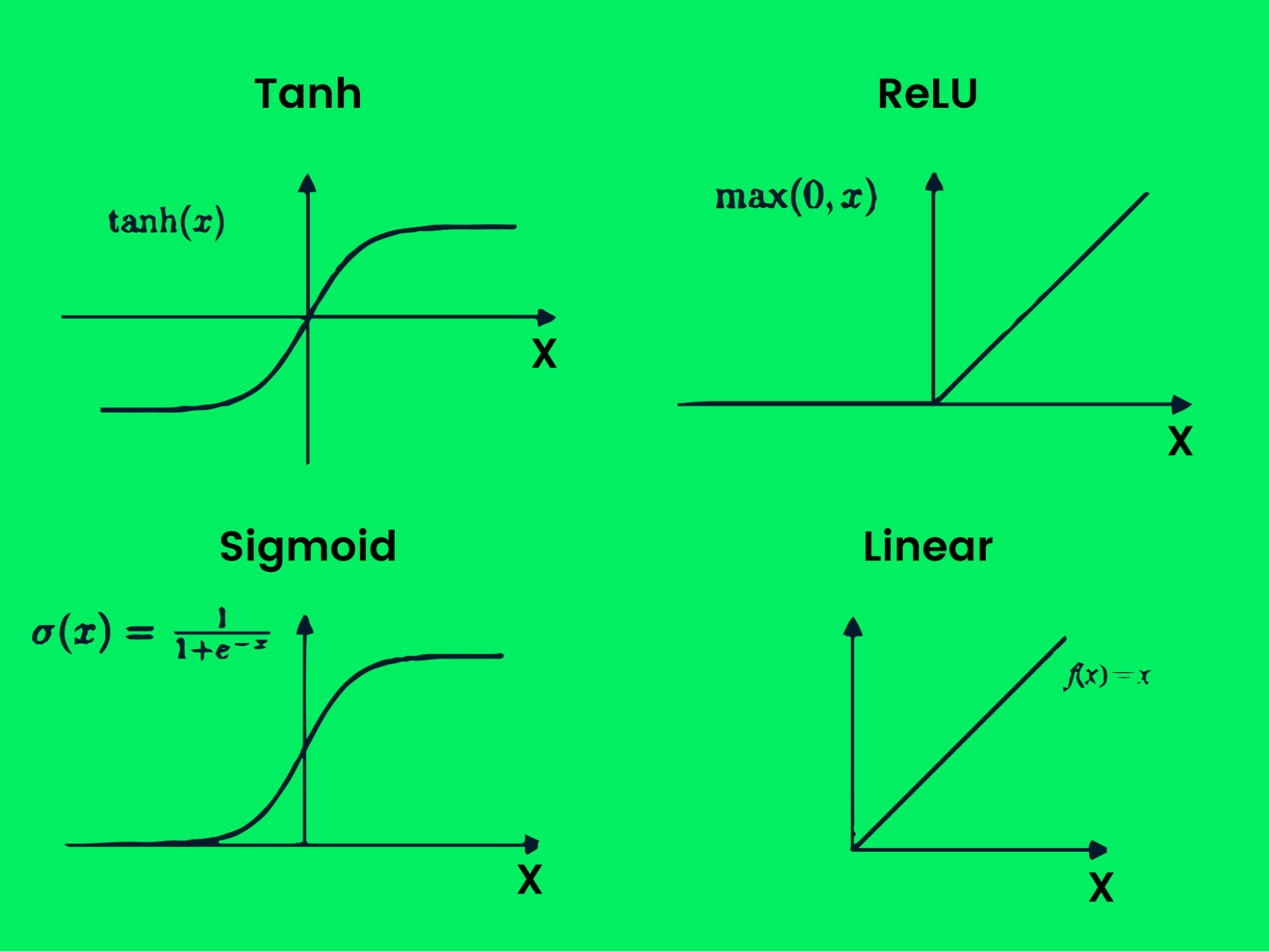 Graphique de fonction d'activation
Graphique de fonction d'activation
La fonction de perte mesure la différence entre les valeurs réelles et prédites, les performances du modèle de suivi. Les exemples incluent une entropie croisée binaire, une charnière catégorique, une erreur carrée moyenne, un Huber et une entropie croisée catégorique clairsemée.
Backpropagation ajuste les poids du réseau pour minimiser la fonction de perte, améliorant la précision du modèle.
La descente du gradient stochastique optimise la fonction de perte en ajustant de manière itérative des poids en utilisant des lots d'échantillons, en améliorant l'efficacité.
Les hyperparamètres sont des paramètres réglables affectant les performances du modèle, telles que le taux d'apprentissage, la taille du lot et le nombre d'époches.
CNNS traite efficacement les données structurées (images), en excellant à la reconnaissance des modèles.
 Architecture de réseau neuronal convolutionnel
Architecture de réseau neuronal convolutionnel
Les RNN gèrent les données séquentielles en renforçant la sortie dans l'entrée, utile pour l'analyse des séries chronologiques et la NLP.
 Architecture de réseau neuronal récurrente
Architecture de réseau neuronal récurrente
Les LSTM sont des RNN avancés qui abordent le problème du gradient de fuite, mieux conserver les dépendances à long terme dans les données séquentielles.
 Architecture LSTM
Architecture LSTM
Plusieurs cadres d'apprentissage en profondeur existent, chacun avec des forces et des faiblesses. Voici quelques-uns des plus populaires:
TensorFlow est une bibliothèque open source pour créer des applications d'apprentissage en profondeur, en prenant en charge le CPU, le GPU et le TPU. Il comprend le tensorboard pour l'analyse des expériences et intègre des keras pour un développement plus facile.
Keras est une API de réseau neuronal convivial qui fonctionne sur plusieurs backends (y compris TensorFlow), facilitant l'expérimentation rapide.
Pytorch est connu pour sa flexibilité et sa facilité d'utilisation, populaires parmi les chercheurs. Il utilise des tenseurs pour un calcul rapide et prend en charge l'accélération GPU et TPU.
Ce guide a fourni un aperçu complet de l'apprentissage en profondeur, couvrant ses concepts principaux, applications, modèles et cadres. Pour approfondir votre apprentissage, considérez notre apprentissage en profondeur en piste Python ou en profondeur avec des keras dans les cours.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Une fois l'ordinateur allumé, le moniteur n'affiche aucun signal
Une fois l'ordinateur allumé, le moniteur n'affiche aucun signal
 Quels sont les serveurs cloud ?
Quels sont les serveurs cloud ?
 Utilisation de la fonction sprintf en php
Utilisation de la fonction sprintf en php
 Qu'est-ce qu'Avalanche
Qu'est-ce qu'Avalanche
 Comment récupérer les données du disque dur mobile
Comment récupérer les données du disque dur mobile
 Outils d'évaluation des entretiens
Outils d'évaluation des entretiens
 Quelles sont les utilisations de MySQL
Quelles sont les utilisations de MySQL
 Quel logiciel est l'âme ?
Quel logiciel est l'âme ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



