Les experts hybrides ont également des spécialisations dans le domaine de la chirurgie.
Pour le modèle de base actuel à modalités mixtes, la conception architecturale courante consiste à fusionner l'encodeur ou le décodeur d'une modalité spécifique, mais cette méthode a des limites : elle ne peut pas intégrer les informations provenant de différentes modalités, et il est difficile à afficher. Contient du contenu dans plusieurs modalités. Afin de surmonter cette limitation, l'équipe Chameleon de Meta FAIR a proposé une nouvelle architecture Transformer unique dans l'article récent « Chameleon : Mixed-modal early-fusion Foundation models », qui peut être basée sur le jeton suivant. L'objectif de la prédiction est de modéliser des séquences multimodales composées d'images discrètes et de jetons de texte, permettant une inférence et une génération transparentes entre différentes modalités. 
Après avoir suivi une pré-formation sur environ 10 000 milliards de jetons multimodaux, Chameleon a démontré un large éventail de capacités visuelles et linguistiques et peut bien gérer une variété de tâches différentes en aval. Les performances de Chameleon sont particulièrement impressionnantes dans la tâche de génération de réponses longues mixtes. Il bat même les modèles commerciaux tels que Gemini 1.0 Pro et GPT-4V. Cependant, pour un modèle comme Chameleon, où diverses modalités sont mélangées dès les premières étapes de la formation du modèle, étendre ses capacités nécessite d'investir beaucoup de puissance de calcul. Sur la base des problèmes ci-dessus, l'équipe Meta FAIR a mené des recherches et des explorations sur l'architecture clairsemée routée et a proposé MoMa : une architecture hybride experte prenant en compte les modalités.
- Titre de l'article : MoMa : Pré-formation efficace à la fusion précoce avec un mélange d'experts conscients des modalités
- Adresse de l'article : https://arxiv.org/pdf/2407.21770
Recherche précédente a montré que ce type d'architecture peut étendre efficacement les capacités des modèles de base monomodaux et améliorer les performances des modèles d'apprentissage contrastif multimodaux. Cependant, son utilisation pour la formation précoce de modèles intégrant diverses modalités reste un sujet comportant à la fois des opportunités et des défis, et peu de personnes l’ont étudié. Les recherches de l’équipe sont basées sur l’idée que les différentes modalités sont intrinsèquement hétérogènes – les jetons texte et image ont des densités d’informations et des modèles de redondance différents. Tout en intégrant ces jetons dans une architecture de fusion unifiée, l'équipe a également proposé d'optimiser davantage le framework en intégrant des modules pour des modalités spécifiques. L'équipe appelle ce concept de parcimonie consciente des modalités, ou MaS en abrégé ; il permet au modèle de mieux capturer les caractéristiques de chaque modalité tout en utilisant également des mécanismes de partage partiel de paramètres et d'attention. Des recherches antérieures telles que VLMo, BEiT-3 et VL-MoE ont adopté la méthode des experts en modalités mixtes (MoME/mixture-of-modality-experts) pour former l'encodeur de langage visuel et le modèle de construction de langage masqué, l’équipe de recherche de FAIR a poussé encore plus loin la portée utilisable du MoE. Architecture du modèle Transformateur Une série de jetons discrets. À la base, Chameleon est un modèle basé sur Transformer qui applique un mécanisme d’auto-attention à une séquence combinée de jetons d’image et de texte. Cela permet au modèle de capturer des corrélations complexes au sein et entre les modalités. Le modèle est entraîné dans le but de prédire le prochain jeton, en générant des jetons de texte et d'image de manière autorégressive. Dans Chameleon, le schéma de tokenisation d'image utilise un tokenizer d'image d'apprentissage, qui encodera une image 512 × 512 en 1024 jetons discrets basés sur un livre de codes de taille 8192. Pour la segmentation de texte, un tokenizer BPE avec une taille de vocabulaire de 65 536 sera utilisé, qui contient des jetons d'image. Cette méthode de segmentation de mots unifiée permet au modèle de gérer de manière transparente n'importe quelle séquence de jetons d'image et de texte entrelacés.
Avec cette méthode, le nouveau modèle hérite des avantages d'une représentation unifiée, d'une bonne flexibilité, d'une grande évolutivité et d'une prise en charge de l'apprentissage de bout en bout. Sur cette base (Figure 1a), afin d'améliorer encore l'efficacité et les performances du premier modèle de fusion, l'équipe a également introduit une technologie de parcimonie prenant en compte les modalités.
Mise à l'échelle de la largeur : experts hybrides sensibles aux modalités
L'équipe propose une méthode de mise à l'échelle de la largeur : intégrer la parcimonie des modules sensibles aux modalités dans les modules avancés, mettant ainsi à l'échelle l'architecture Standard Hybrid Expert (MoE) . Cette méthode est basée sur l'idée que les jetons dans différents modes ont des caractéristiques et des densités d'informations différentes. 
En construisant différents groupes d'experts pour chaque modalité, le modèle peut développer des chemins de traitement spécialisés tout en conservant des capacités d'intégration d'informations multimodales. La figure 1b illustre les composants clés de ce mélange d'experts sensibles aux modalités (MoMa). Pour faire simple, les experts de chaque modalité spécifique sont d'abord regroupés, puis le routage hiérarchique est mis en œuvre (divisé en routage sensible aux modalités et routage intra-modal), et enfin les experts sont sélectionnés. Veuillez vous référer au document original pour le processus détaillé.
En général, pour un jeton d'entrée x, la définition formelle du module MoMa est :
Après le calcul MoMa, l'équipe a en outre utilisé la connexion résiduelle et la normalisation Swin Transformer. Mélange de profondeurs (MoD) Des chercheurs précédents ont également exploré l'introduction de la parcimonie dans la dimension de profondeur. Leur approche consistait soit à supprimer au hasard certaines couches, soit à utiliser le routeur d'apprentissage disponible. . Plus précisément, comme le montre la figure ci-dessous, l'approche de l'équipe consiste à intégrer le MoD dans chaque couche MoD avant le routage expert hybride (MoE), garantissant ainsi que l'ensemble du lot de données peut utiliser le MoD. Dans la phase d'inférence, nous ne pouvons pas utiliser directement le routage de sélection expert du MoE ou le routage de sélection de couche du MoD car les top-k (sélectionner le top k) sont effectués dans un lot de données ) la sélection détruit la causalité. Afin d'assurer la relation causale du raisonnement, inspiré de l'article du MoD mentionné ci-dessus, l'équipe de recherche a introduit un routeur auxiliaire (auxiliary router), dont le rôle est de prédire que le jeton sera sélectionné par un certain expert ou couche basé uniquement sur la représentation cachée de la possibilité de jeton. Il existe une difficulté unique pour une architecture MoE formée de toutes pièces en termes d'optimisation de l'espace de représentation et du mécanisme de routage. L’équipe a découvert que le routeur MoE est responsable de la division de l’espace de représentation pour chaque expert. Cependant, dans les premières étapes de la formation du modèle, cet espace de représentation n'est pas optimal, ce qui conduira à une fonction de routage obtenue par la formation sous-optimale. Afin de surmonter cette limitation, ils ont proposé une méthode de mise à niveau basée sur l'article « Sparse upcycling : Training mélange d'experts à partir de points de contrôle denses » de Komatsuzaki et al. 
Plus précisément, formez d'abord une architecture avec un expert FFN par modalité. Après quelques étapes prédéfinies, le modèle est mis à niveau et transformé. La méthode spécifique est la suivante : convertir le FFN de chaque modalité spécifique en un module MoE sélectionné par des experts et initialiser chaque expert à la première étape de formation des experts. Cela réinitialisera le planificateur de taux d'apprentissage tout en conservant l'état du chargeur de données de l'étape précédente pour garantir que les données actualisées puissent être utilisées dans la deuxième étape de la formation. Pour encourager les experts à être plus spécialisés, l'équipe a également utilisé le bruit de Gumbel pour améliorer la fonction de routage MoE, permettant au nouveau routeur d'échantillonner les experts de manière différenciable. Cette méthode de mise à niveau couplée à la technologie Gumbel-Sigmoïde peut surmonter les limitations des routeurs appris, améliorant ainsi les performances de la nouvelle architecture clairsemée sensible aux modalités proposée. Optimisation de l'efficacitéPour promouvoir la formation distribuée du MoMa, l'équipe a adopté Fully Sharded Data Parallel (FSDP/Fully Sharded Data Parallel). Cependant, par rapport au MoE conventionnel, cette méthode présente des défis d'efficacité uniques, notamment des problèmes d'équilibrage de charge et des problèmes d'efficacité d'exécution experte. Pour le problème d'équilibrage de charge, l'équipe a développé une méthode de mélange de données équilibrée qui maintient le rapport données texte/image sur chaque GPU cohérent avec le rapport expert. Concernant l'efficacité de l'exécution des experts, l'équipe a exploré quelques stratégies qui peuvent contribuer à améliorer l'efficacité de l'exécution des experts dans différentes modalités :
- Limiter les experts de chaque modalité à être des experts homogènes, et interdire acheminer les jetons de texte vers des experts en images et vice versa ;
- Utilisez la parcimonie des blocs pour améliorer l'efficacité de l'exécution
- Lorsque le nombre de modalités est limité, exécutez différentes modalités dans des experts en séquence ;
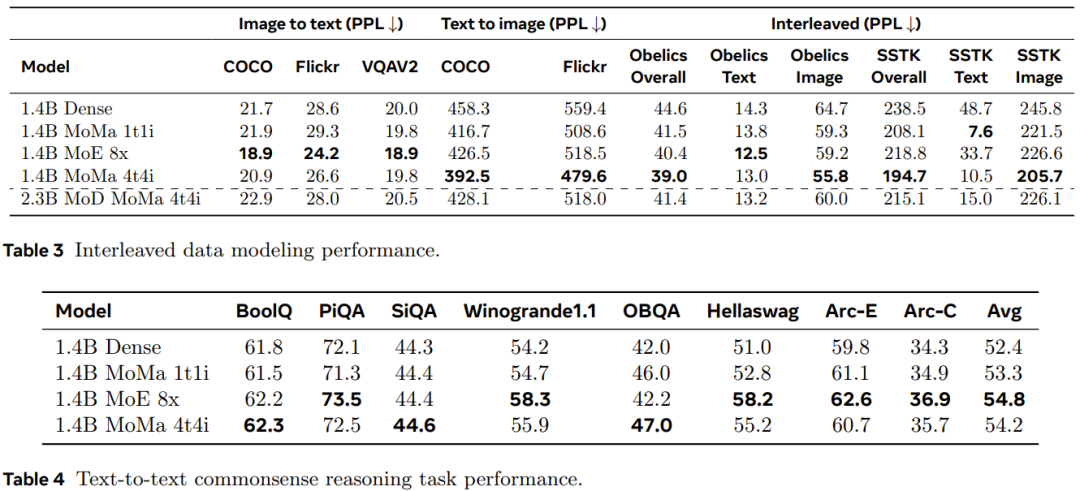
Étant donné que chaque GPU de l'expérience a traité suffisamment de jetons, l'utilisation du matériel n'est pas un gros problème même si plusieurs multiplications matricielles par lots sont utilisées. Par conséquent, l’équipe estime que la méthode d’exécution séquentielle constitue un meilleur choix pour l’échelle actuelle de l’environnement expérimental. Afin d'améliorer encore le débit, l'équipe a également adopté d'autres techniques d'optimisation. Cela inclut des opérations d'optimisation générales telles que la réduction du volume de communication par gradient et la fusion automatisée du cœur du GPU. L'équipe de recherche a également mis en œuvre l'optimisation des graphiques via torch.compile. De plus, ils ont développé des techniques d'optimisation pour MoMa, notamment la réutilisation d'index de jetons modaux sur différentes couches pour synchroniser plus efficacement les appareils entre CPU et GPU. L'ensemble de données de pré-entraînement et le processus de pré-traitement utilisés dans l'expérience sont les mêmes que ceux de Chameleon. Pour évaluer les performances de mise à l'échelle, ils ont formé le modèle en utilisant plus de 1 000 milliards de jetons. Le Tableau 1 donne la configuration détaillée des modèles denses et clairsemés. Mise à l'échelle des performances à différents niveaux de calculL'équipe a analysé les performances de mise à l'échelle de différents modèles à différents niveaux de calcul. Ces niveaux de calcul (FLOP) sont équivalents à trois tailles de modèles denses : 90M, 435M. et 1.4B. Les résultats expérimentaux montrent qu'un modèle clairsemé peut correspondre à la perte pré-entraînement d'un modèle dense avec des FLOP équivalents en utilisant seulement 1/η du total des FLOP (η représente le facteur d'accélération pré-entraînement). L'introduction d'un regroupement d'experts spécifiques à une modalité peut améliorer l'efficacité de pré-entraînement de modèles de différentes tailles, ce qui est particulièrement bénéfique pour les modalités d'image. Comme le montre la figure 3, la configuration moe_1t1i utilisant 1 expert en image et 1 expert en texte surpasse considérablement le modèle dense correspondant. L'augmentation du nombre d'experts dans chaque groupe modal peut améliorer encore les performances du modèle. Profondeur hybride avec des experts L'équipe a observé que la vitesse de convergence de la perte d'entraînement est améliorée lors de l'utilisation de MoE et MoD et de leur forme combinée. Comme le montre la figure 4, l'ajout de MoD (mod_moe_1t1i) à l'architecture moe_1t1i améliore considérablement les performances du modèle dans différentes tailles de modèle. De plus, mod_moe_1t1i peut égaler ou même dépasser moe_4t4i dans différentes tailles et modes de modèle, ce qui montre que l'introduction de parcimonie dans la dimension de profondeur peut également améliorer efficacement l'efficacité de l'entraînement. D'un autre côté, vous pouvez également constater que les avantages de l'empilement du MoD et du MoE diminueront progressivement. Augmentation du nombre d'expertsPour étudier l'impact de l'augmentation du nombre d'experts, l'équipe a mené d'autres expériences d'ablation. Ils ont exploré deux scénarios : attribuer un nombre égal d'experts à chaque modalité (équilibré) et attribuer un nombre différent d'experts à chaque modalité (déséquilibré). Les résultats sont présentés dans la figure 5. Pour le cadre équilibré, il ressort de la figure 5a qu'à mesure que le nombre d'experts augmente, la perte d'entraînement diminuera considérablement. Mais les pertes de texte et d’image présentent des modèles d’échelle différents. Cela suggère que les caractéristiques inhérentes à chaque modalité conduisent à des comportements de modélisation clairsemés différents. Pour le réglage déséquilibré, la figure 5b compare trois configurations différentes avec un nombre total équivalent d'experts (8). On peut constater que plus il y a d’experts dans une modalité, meilleures sont les performances du modèle sur cette modalité. Mise à niveau et transformationL'équipe a naturellement vérifié l'effet de la mise à niveau et de la transformation susmentionnée. La figure 6 compare les courbes d'entraînement de différentes variantes de modèle. Les résultats montrent que la mise à niveau peut en effet améliorer encore davantage la formation du modèle : lorsque la première étape comporte 10 000 étapes, la mise à niveau peut apporter 1,2 fois le bénéfice des FLOP et lorsque le nombre d'étapes est de 20 000, il y en a également 1,16x ; Les FLOP reviennent. De plus, on peut observer qu'à mesure que la formation progresse, l'écart de performances entre le modèle amélioré et le modèle formé à partir de zéro continuera d'augmenter. Les modèles clairsemés n'apportent souvent pas de gains de performances immédiats, car les modèles clairsemés augmentent la dynamique et les problèmes d'équilibrage des données associés. Pour quantifier l'impact de la méthode nouvellement proposée sur l'efficacité de la formation, l'équipe a comparé le débit de formation de différentes architectures dans le cadre d'expériences avec des variables généralement contrôlées. Les résultats sont présentés dans le tableau 2. On peut constater que par rapport au modèle dense, les performances clairsemées basées sur le modal permettent d'obtenir un meilleur compromis qualité-débit et peuvent montrer une évolutivité raisonnable à mesure que le nombre d'experts augmente. D’un autre côté, bien que les variantes du MoD obtiennent les meilleures pertes absolues, elles ont également tendance à être plus coûteuses en calcul en raison de dynamiques et de déséquilibres supplémentaires. Performance du temps d'inférenceL'équipe a également évalué les performances du modèle sur les données de modélisation de langage conservées et les tâches en aval. Les résultats sont présentés dans les tableaux 3 et 4. Comme le montre le tableau 3, en utilisant plusieurs experts en images, le modèle 1,4B MoMa 1t1i surpasse le modèle dense correspondant dans la plupart des métriques, à l'exception de la métrique de perplexité conditionnelle image-texte sur l'exception COCO et Flickr. L'augmentation du nombre d'experts améliore également les performances, avec 1,4 milliard de MoE 8x permettant d'obtenir les meilleures performances image-texte. De plus, comme le montre le tableau 4, le modèle 1,4B MoE 8x est également très efficace pour les tâches texte-texte. 1,4 B MoMa 4t4i fonctionne mieux sur toutes les mesures de perplexité d'image conditionnelle, tandis que sa perplexité de texte sur la plupart des benchmarks est également très proche de 1,4 B MoE 8x. En général, le modèle 1.4B MoMa 4t4i a les meilleurs résultats de modélisation sur des modalités mixtes de texte et d'image. Pour plus de détails, veuillez lire l'article original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!











 À quel point Snapdragon 8gen2 est-il équivalent à Apple ?
À quel point Snapdragon 8gen2 est-il équivalent à Apple ?
 Comment résoudre l'erreur d'application WerFault.exe
Comment résoudre l'erreur d'application WerFault.exe
 disposition absolue
disposition absolue
 Mongodb et MySQL sont faciles à utiliser et recommandés
Mongodb et MySQL sont faciles à utiliser et recommandés
 utilisation du format_numéro
utilisation du format_numéro
 conversion RVB en hexadécimal
conversion RVB en hexadécimal
 Comment créer des graphiques et des graphiques d'analyse de données en PPT
Comment créer des graphiques et des graphiques d'analyse de données en PPT
 Quelles sont les bibliothèques tierces couramment utilisées en PHP ?
Quelles sont les bibliothèques tierces couramment utilisées en PHP ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



