La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Cet article a été complété par HMI Lab. HMI LabS'appuyant sur les deux principales plates-formes du Centre national de recherche en ingénierie pour les technologies vidéo et visuelles de l'Université de Pékin et du Laboratoire national clé de traitement de l'information multimédia, il est engagé depuis longtemps dans la recherche dans le sens de l'apprentissage automatique et de l'apprentissage multimodal. et l'intelligence incarnée. Le premier auteur de ces travaux est le Dr Liu Jiaming, dont la direction de recherche porte sur les grands modèles incarnés multimodaux et la technologie d'apprentissage continu pour le monde ouvert. Le deuxième auteur de ce travail est Liu Mengzhen, dont la direction de recherche est le modèle de base de la vision et la manipulation du robot. L'instructeur est Chen Shanghang, chercheur à l'École d'informatique de l'Université de Pékin, directeur de doctorat et jeune universitaire libéral. Engagé dans la recherche sur les grands modèles multimodaux et l'intelligence incorporée, il a obtenu une série de résultats de recherche importants. Il a publié plus de 80 articles dans les principales revues et conférences sur l'intelligence artificielle et a été cité par Google plus de 9 700 fois. A remporté le prix du meilleur article de l'AAAI, la plus grande conférence mondiale sur l'intelligence artificielle, et s'est classé premier dans Trending Research, le plus grand référentiel de codes sources universitaires au monde. Afin de donner au robot des capacités de raisonnement et de manipulation de bout en bout, cet article intègre de manière innovante l'encodeur visuel avec un modèle de langage d'espace d'état efficace pour construire un nouveau grand modèle multimodal RoboMamba, le rendant capable d'un langage visuel commun. détecter les tâches et les capacités de raisonnement des robots sur des tâches connexes et avoir atteint des performances avancées. Dans le même temps, cet article révèle que lorsque RoboMamba possède de fortes capacités de raisonnement, nous pouvons permettre à RoboMamba de maîtriser de multiples capacités de prédiction de posture de manipulation grâce à des coûts de formation extrêmement faibles.

Article : RoboMamba : Modèle spatial d'état multimodal pour un raisonnement et une manipulation efficaces des robots
Lien de l'article : https://arxiv.org/abs/2406.04339
Page d'accueil du projet : https:// sites.google.com/view/robomamba-web
Github : https://github.com/lmzpai/roboMamba

Figure 1. Capacités liées au robot de RoboMamba, y compris la planification des tâches , planification de mission rapide, planification de mission à longue portée, jugement de maniabilité, génération de maniabilité, prédiction future et passée, prédiction de pose d'effecteur final, etc. Un objectif fondamental de la manipulation du robot est de permettre au modèle de comprendre la scène visuelle et d'effectuer des actions. Bien que les grands modèles multimodaux de robots (MLLM) existants puissent gérer une série de tâches de base, ils sont toujours confrontés à des défis sous deux aspects : 1) une capacité de raisonnement insuffisante pour gérer des tâches complexes ; 2) le coût de calcul du réglage fin et de l'inférence du MLLM est relativement élevé ; haut. Un modèle d'espace d'états (SSM) récemment proposé, à savoir Mamba, possède une complexité d'inférence linéaire tout en démontrant des capacités prometteuses en matière de modélisation de séquences. Inspirés par cela, nous avons lancé un robot MLLM de bout en bout, RoboMamba, qui utilise le modèle Mamba pour fournir des capacités de raisonnement et d'action au robot tout en conservant des capacités de réglage et de raisonnement efficaces. Plus précisément, nous intégrons d'abord l'encodeur visuel avec Mamba pour aligner les données visuelles avec les intégrations de langage grâce à une formation conjointe, donnant à notre modèle du bon sens visuel et des capacités de raisonnement liées au robot. Pour améliorer encore les capacités de prédiction de pose de manipulation de RoboMamba, nous explorons une stratégie de réglage efficace utilisant uniquement un simple responsable de politique. Nous avons constaté qu'une fois que RoboMamba dispose de capacités de raisonnement suffisantes, il peut maîtriser plusieurs compétences opérationnelles avec très peu de paramètres de réglage fin (0,1 % du modèle) et de temps de réglage fin (20 minutes). Lors d'expériences, RoboMamba a démontré d'excellentes capacités de raisonnement sur des critères d'évaluation généraux et robotiques, comme le montre la figure 2. Dans le même temps, notre modèle démontre des capacités impressionnantes de prédiction des poses de manipulation dans les simulations et les expériences du monde réel, avec des vitesses d'inférence jusqu'à 7 fois plus rapides que les MLLM robotiques existants. 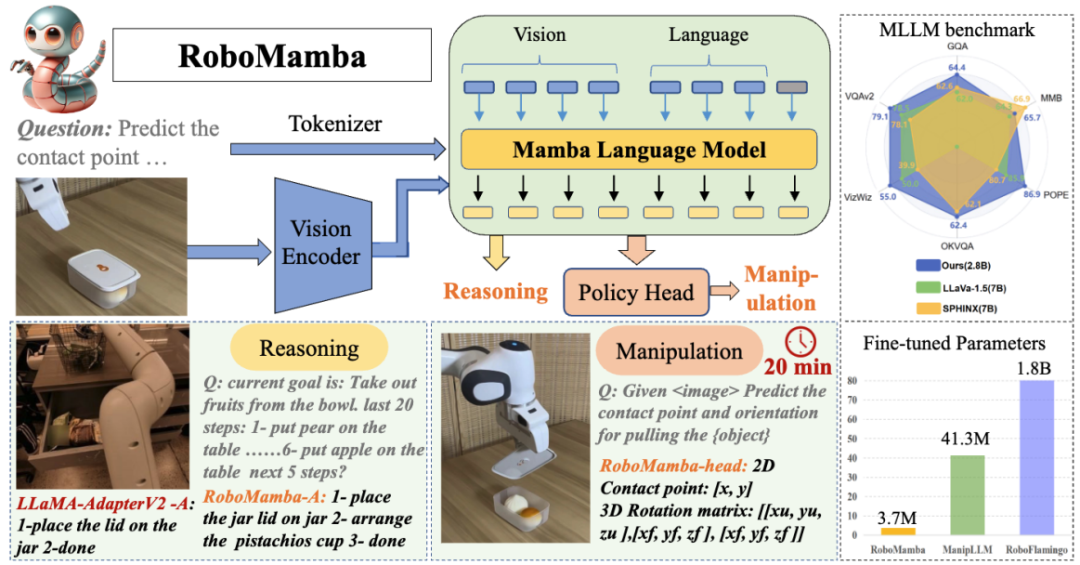
Figure 2. Présentation : Robomamba est un grand modèle de robots multimodal efficace doté de puissantes capacités de raisonnement et d'opération. RoboMamba-2.8B atteint des performances d'inférence compétitives avec d'autres MLLM 7B sur des benchmarks MLLM à usage général tout en démontrant des capacités d'inférence à longue portée dans les tâches robotiques. Par la suite, nous avons introduit une stratégie de réglage fin extrêmement efficace pour donner à RoboMamba la capacité de prédire les poses de manipulation, et cela ne prend que 20 minutes pour affiner une tête de stratégie simple. Les principales contributions de cet article sont résumées comme suit :
- Nous intégrons de manière innovante l'encodeur visuel avec le modèle de langage Mamba efficace pour construire un nouveau grand multimodal de bout en bout modèle de robot, RoboMamba, qui possède un bon sens visuel et des capacités de raisonnement complètes liées aux robots.
- Afin d'équiper RoboMamba de capacités de prédiction de pose de manipulation d'effecteur final, nous avons exploré une stratégie de réglage fin efficace à l'aide d'un simple responsable de politique. Nous avons constaté qu'une fois que RoboMamba atteint des capacités de raisonnement suffisantes, il peut maîtriser les compétences de prédiction de pose de manipulation à un coût très faible.
- Dans nos expériences approfondies, RoboMamba fonctionne bien sur les références d'évaluation d'inférence générale et robotique, et démontre des résultats de prédiction de pose impressionnants dans des simulateurs et des expériences du monde réel.
La mise à l'échelle des données a considérablement favorisé le développement de la recherche sur de grands modèles de langage (LLM), démontrant d'importantes capacités de raisonnement et de généralisation dans les progrès du traitement du langage naturel (NLP). Afin de comprendre les informations multimodales, des modèles multimodaux de langage étendu (MLLM) ont émergé, donnant aux LLM la capacité de suivre des instructions visuelles et de comprendre des scènes. Inspirées par les puissantes capacités des MLLM dans les environnements à usage général, des recherches récentes visent à appliquer les MLLM au domaine du fonctionnement des robots. Certains efforts de recherche permettent aux robots de comprendre le langage naturel et les scènes visuelles et de générer automatiquement des plans de mission. D'autres travaux de recherche exploitent les capacités inhérentes aux MLLM pour leur permettre de prédire les poses opératoires. Le fonctionnement du robot implique d'interagir avec des objets dans un environnement dynamique, nécessitant des capacités de raisonnement de type humain pour comprendre les informations sémantiques de la scène, ainsi que de puissantes capacités de prédiction de pose de manipulation. Bien que les MLLM basés sur des robots existants puissent gérer une gamme de tâches de base, ils sont toujours confrontés à des défis sous deux aspects. 1) Premièrement, la capacité de raisonnement des MLLM pré-entraînés dans des scénarios robotiques s'est avérée insuffisante. Comme le montre la figure 2, cette lacune crée des défis lorsque les MLLM robotiques affinés sont confrontés à des tâches de raisonnement complexes. 2) Deuxièmement, en raison de la grande complexité informatique des mécanismes d'attention MLLM existants, le réglage fin des MLLM et leur utilisation pour générer des actions de fonctionnement des robots entraîneront des coûts de calcul plus élevés. Afin d'équilibrer capacité de raisonnement et efficacité, plusieurs études ont vu le jour dans le domaine de la PNL. En particulier, Mamba introduit le modèle innovant d'espace à états sélectif (SSM), qui facilite le raisonnement contextuel tout en conservant une complexité linéaire. Inspirés par cela, nous avons posé une question : "Pouvons-nous développer un MLLM robotique efficace qui possède non seulement de fortes capacités de raisonnement, mais qui acquiert également des compétences d'exploitation robotique de manière très économique ?" méthodeÉnoncé du problème
-
Pour le raisonnement visuel du robot, notre Robo Mamba génère un langage basé sur des images
et des questions linguistiques
La réponse est
, exprimé par
.Les réponses de raisonnement contiennent souvent des sous-tâches distinctes  pour une question
pour une question  . Par exemple, face à un problème de planification tel que « Comment débarrasser la table ? », les réponses incluent généralement des étapes telles que « Étape 1 : ramasser l'objet » et « Étape 2 : mettre l'objet dans la boîte ». Pour la prédiction des actions, nous utilisons un chef de politique efficace et simple π pour prédire les actions
. Par exemple, face à un problème de planification tel que « Comment débarrasser la table ? », les réponses incluent généralement des étapes telles que « Étape 1 : ramasser l'objet » et « Étape 2 : mettre l'objet dans la boîte ». Pour la prédiction des actions, nous utilisons un chef de politique efficace et simple π pour prédire les actions  . Suite à des travaux antérieurs, nous utilisons 6-DoF pour exprimer la pose de l'effecteur final du bras robotique Franka Emika Panda. Les 6 degrés de liberté incluent la position de l'effecteur final
. Suite à des travaux antérieurs, nous utilisons 6-DoF pour exprimer la pose de l'effecteur final du bras robotique Franka Emika Panda. Les 6 degrés de liberté incluent la position de l'effecteur final 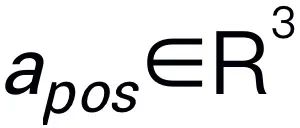 représentant les coordonnées tridimensionnelles et la direction
représentant les coordonnées tridimensionnelles et la direction  représentant la matrice de rotation. Lors d'un entraînement sur une tâche de préhension, nous ajoutons l'état de la pince à la prédiction de pose, permettant le contrôle 7-DoF.
Cet article choisit Mamba comme grand modèle de langage. Mamba est composé de nombreux blocs Mamba, le composant le plus critique étant SSM. SSM est conçu sur la base d'un système continu qui projette une séquence d'entrée 1D
représentant la matrice de rotation. Lors d'un entraînement sur une tâche de préhension, nous ajoutons l'état de la pince à la prédiction de pose, permettant le contrôle 7-DoF.
Cet article choisit Mamba comme grand modèle de langage. Mamba est composé de nombreux blocs Mamba, le composant le plus critique étant SSM. SSM est conçu sur la base d'un système continu qui projette une séquence d'entrée 1D 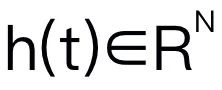 vers une séquence de sortie 1D
vers une séquence de sortie 1D 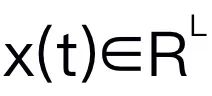 via des états cachés
via des états cachés  . SSM se compose de trois paramètres clés : la matrice d'état
. SSM se compose de trois paramètres clés : la matrice d'état  , la matrice d'entrée
, la matrice d'entrée  et la matrice de sortie
et la matrice de sortie  . Le SSM peut être exprimé comme suit :
. Le SSM peut être exprimé comme suit : 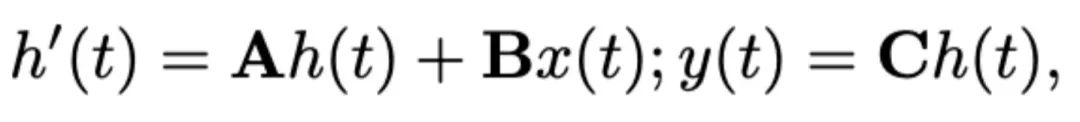
Les SSM récents (par exemple, Mamba) sont construits comme des systèmes continus discrets en utilisant un paramètre d'échelle de temps Δ. Ce paramètre convertit les paramètres continus A et B en paramètres discrets  et
et  . La discrétisation adopte la méthode de préservation d'ordre zéro, qui est définie comme suit :
. La discrétisation adopte la méthode de préservation d'ordre zéro, qui est définie comme suit : 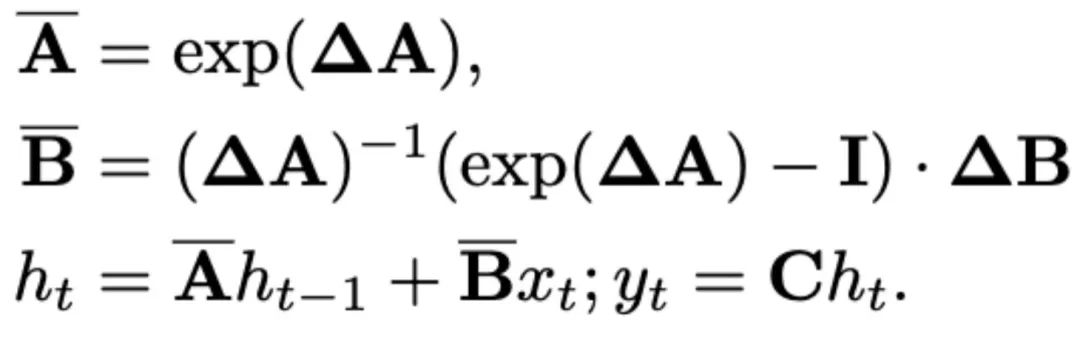
Mamba introduit un mécanisme d'analyse sélective (S6) pour former son opération SSM dans chaque bloc Mamba. Paramètres SSM mis à jour vers  pour une meilleure inférence tenant compte du contenu. Les détails du bloc Mamba sont présentés dans la figure 3 ci-dessous. 2. Structure du modèle RoboMamba
pour une meilleure inférence tenant compte du contenu. Les détails du bloc Mamba sont présentés dans la figure 3 ci-dessous. 2. Structure du modèle RoboMamba 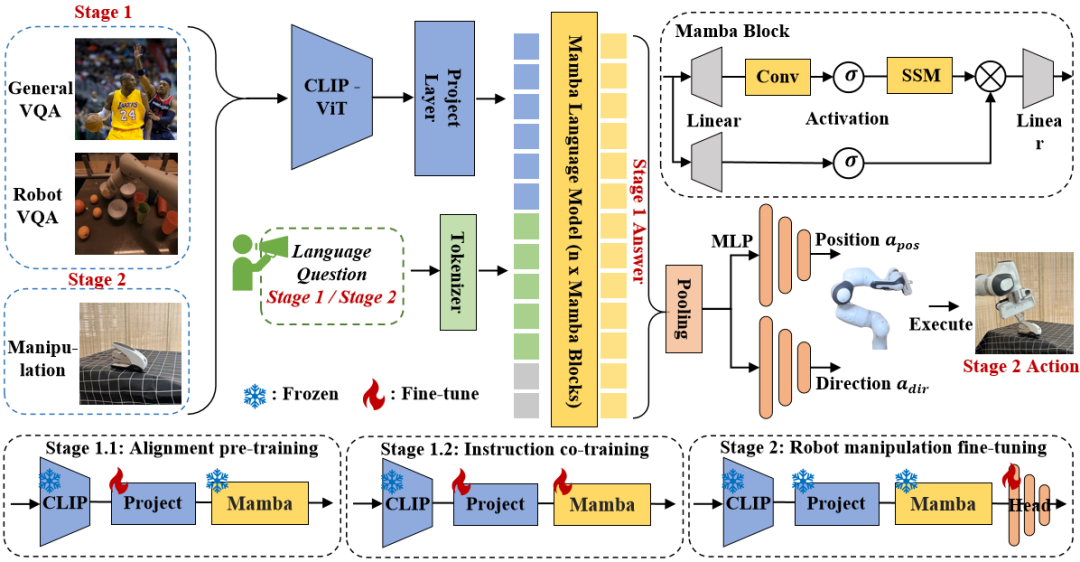
Figure 3. Cadre global de Robomamba. RoboMamba projette des images dans l'espace d'intégration du langage Mamba via des encodeurs visuels et des couches de projection, qui sont ensuite concaténées avec des jetons de texte et introduites dans le modèle Mamba. Pour prédire la position et l'orientation de l'effecteur final, nous introduisons un simple chef de politique MLP et utilisons une opération de pooling pour générer des jetons globaux à partir des jetons de sortie du langage en entrée. La stratégie de formation de RoboMamba. Pour la formation des modèles, nous divisons le processus de formation en deux étapes. Au cours de l'étape 1, nous introduisons une pré-formation alignée (étape 1.1) et une co-formation aux instructions (étape 1.2) pour doter RoboMamba d'un raisonnement de bon sens et de capacités de raisonnement liées aux robots. Au cours de l'étape 2, nous proposons un réglage fin du fonctionnement du robot pour doter efficacement RoboMamba de compétences opérationnelles de bas niveau. Pour doter RoboMamba de capacités de raisonnement visuel et d'exploitation, nous avons construit une architecture MLLM efficace à partir de grands modèles de langage (LLM) et de modèles de vision pré-entraînés. Comme le montre la figure 3 ci-dessus, nous utilisons l'encodeur visuel CLIP pour extraire les caractéristiques visuelles 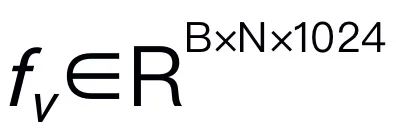 de l'image d'entrée I, où B et N représentent respectivement la taille du lot et le nombre de jetons. Contrairement aux MLLM récents, nous n'utilisons pas de techniques d'ensemble d'encodeurs visuels, qui utilisent plusieurs réseaux fédérateurs (c'est-à-dire DINOv2, CLIP-ConvNeXt, CLIP-ViT) pour l'extraction de caractéristiques d'image. L'intégration introduit des coûts de calcul supplémentaires, affectant gravement la praticité du MLLM robotique dans le monde réel. Par conséquent, nous démontrons que la conception de modèles simples et directs peut également permettre d’obtenir de puissantes capacités d’inférence lorsque des données de haute qualité et des stratégies de formation appropriées sont combinées. Pour que le LLM comprenne les caractéristiques visuelles, nous utilisons un perceptron multicouche (MLP) pour connecter l'encodeur visuel au LLM. Avec ce simple connecteur multimodal, RoboMamba peut transformer des informations visuelles en un espace d'intégration de langage
de l'image d'entrée I, où B et N représentent respectivement la taille du lot et le nombre de jetons. Contrairement aux MLLM récents, nous n'utilisons pas de techniques d'ensemble d'encodeurs visuels, qui utilisent plusieurs réseaux fédérateurs (c'est-à-dire DINOv2, CLIP-ConvNeXt, CLIP-ViT) pour l'extraction de caractéristiques d'image. L'intégration introduit des coûts de calcul supplémentaires, affectant gravement la praticité du MLLM robotique dans le monde réel. Par conséquent, nous démontrons que la conception de modèles simples et directs peut également permettre d’obtenir de puissantes capacités d’inférence lorsque des données de haute qualité et des stratégies de formation appropriées sont combinées. Pour que le LLM comprenne les caractéristiques visuelles, nous utilisons un perceptron multicouche (MLP) pour connecter l'encodeur visuel au LLM. Avec ce simple connecteur multimodal, RoboMamba peut transformer des informations visuelles en un espace d'intégration de langage 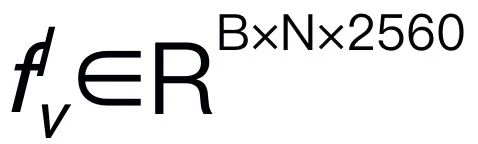 . Veuillez noter que l'efficacité des modèles est cruciale dans le domaine de la robotique, car les robots doivent répondre rapidement aux instructions humaines. Par conséquent, nous choisissons Mamba comme grand modèle de langage en raison de ses capacités de raisonnement contextuel et de sa complexité de calcul linéaire. Les invites textuelles sont codées dans un espace d'intégration
. Veuillez noter que l'efficacité des modèles est cruciale dans le domaine de la robotique, car les robots doivent répondre rapidement aux instructions humaines. Par conséquent, nous choisissons Mamba comme grand modèle de langage en raison de ses capacités de raisonnement contextuel et de sa complexité de calcul linéaire. Les invites textuelles sont codées dans un espace d'intégration 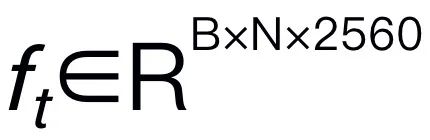 à l'aide d'un tokenizer pré-entraîné, puis concaténées (cat) avec des jetons visuels et introduites dans Mamba. Nous exploitons la puissante modélisation de séquences de Mamba pour comprendre les informations multimodales et utilisons des stratégies de formation efficaces pour développer des capacités de raisonnement visuel (comme décrit dans la section suivante). Le jeton de sortie (
à l'aide d'un tokenizer pré-entraîné, puis concaténées (cat) avec des jetons visuels et introduites dans Mamba. Nous exploitons la puissante modélisation de séquences de Mamba pour comprendre les informations multimodales et utilisons des stratégies de formation efficaces pour développer des capacités de raisonnement visuel (comme décrit dans la section suivante). Le jeton de sortie ( ) est ensuite décodé (det) pour générer une réponse en langage naturel
) est ensuite décodé (det) pour générer une réponse en langage naturel 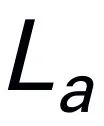 . Le processus avancé du modèle peut être exprimé comme suit :
. Le processus avancé du modèle peut être exprimé comme suit : 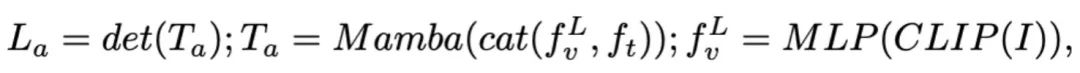
3.RoboMamba vision générale et formation à la capacité de raisonnement du robotAprès avoir construit l'architecture RoboMamba, l'objectif suivant est d'entraîner notre modèle à apprendre le raisonnement visuel général et les capacités de raisonnement liées au robot. Comme le montre la figure 3, nous divisons la formation de l'étape 1 en deux sous-étapes : la pré-formation à l'alignement (étape 1.1) et la co-formation à l'instruction (étape 1.2). Plus précisément, contrairement aux méthodes de formation MLLM précédentes, nous visons à permettre à RoboMamba de comprendre les scénarios généraux de vision et de robotique. Étant donné que le domaine de la robotique implique de nombreuses tâches complexes et nouvelles, RoboMamba nécessite des capacités de généralisation plus fortes. Par conséquent, nous avons adopté une stratégie de co-formation à l'étape 1.2 pour combiner des données de haut niveau sur le robot (par exemple, la planification de mission) avec des données d'instructions générales. Nous constatons que la co-formation aboutit non seulement à des politiques robotiques plus généralisables, mais également à des capacités de raisonnement de scénarios généraux améliorées grâce à des tâches de raisonnement complexes dans les données du robot. Les détails de la formation sont les suivants : - Étape 1.1 : Pré-formation Alignement.
Nous adoptons l'ensemble de données couplées image-texte filtré 558k LLaVA pour l'alignement multimodal. Comme le montre la figure 3, nous gelons les paramètres de l'encodeur CLIP et du modèle de langage Mamba et mettons à jour uniquement la couche de projection. De cette façon, nous pouvons aligner les caractéristiques de l'image avec des intégrations de mots Mamba pré-entraînées. - Étape 1.2 : Commande de s'entraîner ensemble.
Dans cette étape, nous suivons d'abord les travaux précédents du MLLM pour la collecte de données d'instruction visuelle générale. Nous utilisons l’ensemble de données d’instructions hybrides LLaVA 655 000 et l’ensemble de données LRV-Instruct 400 000 pour apprendre les instructions visuelles en suivant et en atténuant les hallucinations, respectivement. Il est important de noter que l’atténuation des hallucinations joue un rôle important dans les scénarios robotiques, car le MLLM robotique doit générer des plans de mission basés sur des scénarios réels plutôt que sur des scénarios imaginaires. Par exemple, les MLLM existants peuvent répondre sous forme de formule « Ouvrez le micro-ondes » en disant « Étape 1 : Trouvez la poignée », mais de nombreux fours à micro-ondes n'ont pas de poignées. Ensuite, nous combinons l'ensemble de données 800K RoboVQA pour acquérir des compétences robotiques de haut niveau telles que la planification de missions à longue portée, le jugement de maniabilité, la génération de maniabilité, les prévisions futures et passées, etc. Au cours de la co-formation, comme le montre la figure 3, nous gelons les paramètres de l'encodeur CLIP et affinons la couche de projection et Mamba sur l'ensemble de données fusionné de 1,8 m. Toutes les sorties du modèle de langage Mamba sont supervisées à l'aide d'une perte d'entropie croisée. 4. Formation de réglage précis des capacités de manipulation du RoboMamba Sur la base des puissantes capacités de raisonnement du RoboMamba, nous présentons notre stratégie de réglage précis du fonctionnement du robot dans cette section, appelée étape de formation 2 dans la figure 3. . Les méthodes d'exploitation de robot existantes basées sur MLLM nécessitent la mise à jour de la couche de projection et de l'ensemble du LLM pendant la phase de réglage fin de l'opération. Bien que ce paradigme puisse donner au modèle des capacités de prédiction de pose d'action, il détruit également les capacités inhérentes du MLLM et nécessite une grande quantité de ressources de formation. Pour relever ces défis, nous proposons une stratégie de réglage fin efficace, comme le montre la figure 3. Nous gelons tous les paramètres de RoboMamba et introduisons un simple chef de politique pour modéliser le jeton de sortie de Mamba. Le chef de politique contient deux MLP qui apprennent respectivement la position et la direction de l'effecteur final, occupant un total de 0,1 % de l'ensemble des paramètres du modèle. D'après le travail précédent Where2act, la formule de perte de position et de direction est la suivante : 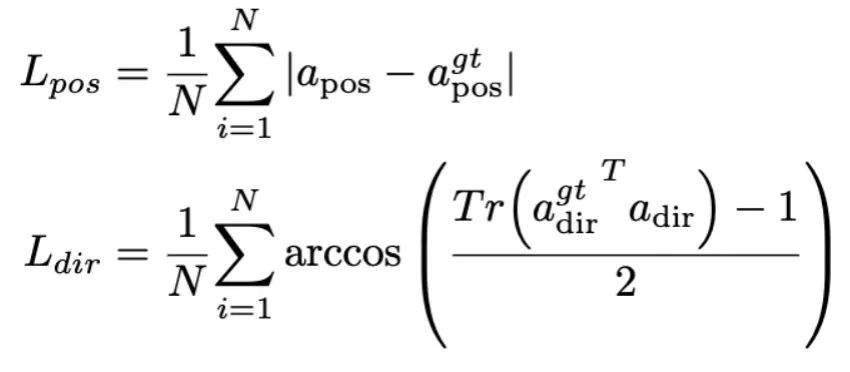 où, N représente le nombre d'échantillons d'apprentissage, et Tr (A) représente la trace de la matrice A. RoboMamba prédit uniquement la position 2D (x, y) du pixel de contact dans l'image, puis utilise les informations de profondeur pour la convertir en espace 3D. Pour évaluer cette stratégie de réglage fin, nous avons généré un ensemble de données de 10 000 prédictions de pose d'effecteurs finaux à l'aide de simulations SAPIEN. Après un réglage opérationnel, nous avons constaté qu'une fois que RoboMamba dispose de capacités de raisonnement suffisantes, il peut acquérir des compétences de prédiction de pose grâce à un réglage extrêmement efficace. Grâce au nombre minimal de paramètres de réglage fin (7 Mo) et à la conception efficace du modèle, nous pouvons acquérir de nouvelles compétences opérationnelles en seulement 20 minutes. Cette découverte met en évidence l’importance de la capacité de raisonnement dans l’apprentissage des compétences opérationnelles et propose une nouvelle perspective : nous pouvons efficacement doter les MLLM de capacités opérationnelles sans affecter leurs capacités de raisonnement inhérentes. Enfin, RoboMamba peut utiliser des réponses linguistiques pour le bon sens et le raisonnement lié aux robots, ainsi qu'un responsable politique pour la prédiction de pose d'action. 1. Évaluation générale de la capacité de raisonnement (MLLM Benchmarks) Pour évaluer la capacité de raisonnement, nous avons utilisé plusieurs critères de référence populaires, notamment VQAv2, OKVQA, GQA, OCRVQA , VizWiz, POPE, MME, MMBench et MM-Vet.En outre, nous avons également évalué directement les capacités de raisonnement liées aux robots de RoboMamba sur l'ensemble de données de vérification de 18 000 RoboVQA, couvrant les tâches du robot telles que la planification des tâches, la planification des tâches guidées, la planification des tâches à longue portée, le jugement de maniabilité et la maniabilité. prédiction future, etc. Om Tableau 1. Comparaison de Robomamba et du MLLMS existant sur plusieurs benchmarks.
où, N représente le nombre d'échantillons d'apprentissage, et Tr (A) représente la trace de la matrice A. RoboMamba prédit uniquement la position 2D (x, y) du pixel de contact dans l'image, puis utilise les informations de profondeur pour la convertir en espace 3D. Pour évaluer cette stratégie de réglage fin, nous avons généré un ensemble de données de 10 000 prédictions de pose d'effecteurs finaux à l'aide de simulations SAPIEN. Après un réglage opérationnel, nous avons constaté qu'une fois que RoboMamba dispose de capacités de raisonnement suffisantes, il peut acquérir des compétences de prédiction de pose grâce à un réglage extrêmement efficace. Grâce au nombre minimal de paramètres de réglage fin (7 Mo) et à la conception efficace du modèle, nous pouvons acquérir de nouvelles compétences opérationnelles en seulement 20 minutes. Cette découverte met en évidence l’importance de la capacité de raisonnement dans l’apprentissage des compétences opérationnelles et propose une nouvelle perspective : nous pouvons efficacement doter les MLLM de capacités opérationnelles sans affecter leurs capacités de raisonnement inhérentes. Enfin, RoboMamba peut utiliser des réponses linguistiques pour le bon sens et le raisonnement lié aux robots, ainsi qu'un responsable politique pour la prédiction de pose d'action. 1. Évaluation générale de la capacité de raisonnement (MLLM Benchmarks) Pour évaluer la capacité de raisonnement, nous avons utilisé plusieurs critères de référence populaires, notamment VQAv2, OKVQA, GQA, OCRVQA , VizWiz, POPE, MME, MMBench et MM-Vet.En outre, nous avons également évalué directement les capacités de raisonnement liées aux robots de RoboMamba sur l'ensemble de données de vérification de 18 000 RoboVQA, couvrant les tâches du robot telles que la planification des tâches, la planification des tâches guidées, la planification des tâches à longue portée, le jugement de maniabilité et la maniabilité. prédiction future, etc. Om Tableau 1. Comparaison de Robomamba et du MLLMS existant sur plusieurs benchmarks. 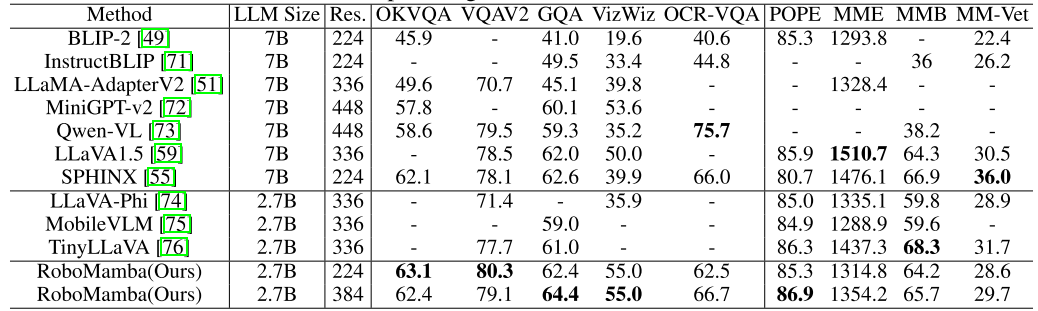 Comme le montre le tableau 1, nous comparons RoboMamba avec le précédent MLLM de pointe (SOTA) sur le VQA commun et les benchmarks MLLM récents. Premièrement, nous constatons que RoboMamba obtient des résultats satisfaisants sur tous les benchmarks VQA en utilisant seulement 2,7 milliards de modèles de langage. Les résultats montrent que la conception structurelle simple est efficace. La pré-formation alignée et la co-formation pédagogique améliorent considérablement les capacités d'inférence du MLLM. Par exemple, les performances de reconnaissance spatiale de RoboMamba sur le benchmark GQA sont améliorées grâce à l'introduction de grandes quantités de données robot dans la phase de formation collaborative. Pendant ce temps, nous avons également testé notre RoboMamba sur le benchmark MLLM récemment proposé. Par rapport aux MLLM précédents, nous observons que notre modèle obtient des résultats compétitifs sur tous les benchmarks. Bien que certaines performances de RoboMamba soient encore inférieures à celles du MLLM 7B de pointe (par exemple, LLaVA1.5 et SPHINX), nous donnons la priorité au Mamba-2.7B, plus petit et plus rapide, pour équilibrer l'efficacité du modèle de robot. À l'avenir, nous prévoyons de développer RoboMamba-7B pour des scénarios sans contraintes de ressources.
Comme le montre le tableau 1, nous comparons RoboMamba avec le précédent MLLM de pointe (SOTA) sur le VQA commun et les benchmarks MLLM récents. Premièrement, nous constatons que RoboMamba obtient des résultats satisfaisants sur tous les benchmarks VQA en utilisant seulement 2,7 milliards de modèles de langage. Les résultats montrent que la conception structurelle simple est efficace. La pré-formation alignée et la co-formation pédagogique améliorent considérablement les capacités d'inférence du MLLM. Par exemple, les performances de reconnaissance spatiale de RoboMamba sur le benchmark GQA sont améliorées grâce à l'introduction de grandes quantités de données robot dans la phase de formation collaborative. Pendant ce temps, nous avons également testé notre RoboMamba sur le benchmark MLLM récemment proposé. Par rapport aux MLLM précédents, nous observons que notre modèle obtient des résultats compétitifs sur tous les benchmarks. Bien que certaines performances de RoboMamba soient encore inférieures à celles du MLLM 7B de pointe (par exemple, LLaVA1.5 et SPHINX), nous donnons la priorité au Mamba-2.7B, plus petit et plus rapide, pour équilibrer l'efficacité du modèle de robot. À l'avenir, nous prévoyons de développer RoboMamba-7B pour des scénarios sans contraintes de ressources. 2. Évaluation de la capacité de raisonnement du robot (RoboVQA Benchmark)
De plus, afin de comparer de manière exhaustive les capacités de raisonnement liées au robot de RoboMamba, nous l'avons comparé avec LLaMA-AdapterV2 sur l'ensemble de validation RoboVQA. Nous choisissons LLaMA-AdapterV2 comme référence car il s'agit du modèle de base du MLLM robotique SOTA actuel (ManipLLM). Pour une comparaison équitable, nous avons chargé les paramètres pré-entraînés LLaMA-AdapterV2 et les avons affiné sur l'ensemble de formation RoboVQA pendant deux époques en utilisant sa méthode de réglage fin des instructions officielles. Comme le montre la figure 4 a), RoboMamba atteint des performances supérieures entre BLEU-1 et BLEU-4. Les résultats démontrent que notre modèle possède des capacités de raisonnement avancées liées à la robotique et confirment l’efficacité de notre stratégie de formation. En plus d'une plus grande précision, notre modèle atteint des vitesses d'inférence jusqu'à 7 fois plus rapides que LLaMA-AdapterV2 et ManipLLM, ce qui peut être attribué aux capacités d'inférence sensibles au contenu et à l'efficacité du modèle de langage Mamba. Figure 4. Comparaison du raisonnement lié aux robots sur RoboVQA.  3. Évaluation de la capacité de manipulation du robot (SAPIEN)
3. Évaluation de la capacité de manipulation du robot (SAPIEN)
Pour évaluer la capacité de manipulation de RoboMamba, nous avons comparé notre modèle avec quatre lignes de base : UMPNet, Flowbot3D, RoboFlamingo et ManipLLM. Avant la comparaison, nous reproduisons toutes les lignes de base et les formons sur l'ensemble de données que nous avons collecté. Pour UMPNet, nous effectuons des opérations sur des points de contact prédits, orientés perpendiculairement à la surface de l'objet. Flowbot3D prédit la direction du mouvement sur le nuage de points, sélectionne le flux le plus important comme point d'interaction et utilise la direction du flux pour représenter la direction de l'effecteur final. RoboFlamingo et ManipLLM chargent respectivement les paramètres de pré-entraînement OpenFlamingo et LLaMA-AdapterV2 et suivent leurs stratégies respectives de réglage fin et de mise à jour du modèle. Comme le montre le tableau 2, par rapport au SOTA ManipLLM précédent, notre RoboMamba atteint une amélioration de 7,0 % sur la catégorie visible et de 2,0 % sur la catégorie invisible. En termes d'efficacité, RoboFlamingo met à jour 35,5 % (1,8 B) des paramètres du modèle, ManipLLM met à jour les adaptateurs dans LLM (41,3 M) contenant 0,5 % des paramètres du modèle, tandis que notre responsable politique affiné (3,7 M) ne prend en compte que 0,1 paramètres du modèle. %. RoboMamba met à jour 10 fois moins de paramètres que les méthodes précédentes basées sur MLLM tout en déduisant 7 fois plus rapidement. Les résultats montrent que notre RoboMamba possède non seulement de fortes capacités de raisonnement, mais peut également obtenir des capacités de manipulation à faible coût. Tableau 2. Comparaison des taux de réussite entre Robomamba et d'autres références 
Comme le montre la figure 4, nous visualisons les résultats d'inférence de RoboMamba dans diverses tâches robotiques en aval. En termes de planification des tâches, par rapport à LLaMA-AdapterV2, RoboMamba a démontré des capacités de planification plus précises et à plus long terme grâce à ses puissantes capacités de raisonnement. Pour une comparaison équitable, nous affinons également la ligne de base LLaMA-AdapterV2 sur l'ensemble de données RoboVQA. Pour la prédiction des poses de manipulation, nous avons utilisé un bras robotique Franka Emika pour interagir avec divers objets ménagers. Nous projetons la pose 3D prédite par RoboMamba sur une image 2D, en utilisant des points rouges pour représenter les points de contact et des effecteurs terminaux pour représenter les directions, comme indiqué dans le coin inférieur droit de la figure.



🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 . Par exemple, face à un problème de planification tel que « Comment débarrasser la table ? », les réponses incluent généralement des étapes telles que « Étape 1 : ramasser l'objet » et « Étape 2 : mettre l'objet dans la boîte ». Pour la prédiction des actions, nous utilisons un chef de politique efficace et simple π pour prédire les actions
. Par exemple, face à un problème de planification tel que « Comment débarrasser la table ? », les réponses incluent généralement des étapes telles que « Étape 1 : ramasser l'objet » et « Étape 2 : mettre l'objet dans la boîte ». Pour la prédiction des actions, nous utilisons un chef de politique efficace et simple π pour prédire les actions  Comment acheter et vendre du Bitcoin sur Binance
Comment acheter et vendre du Bitcoin sur Binance
 Comment changer la couleur de la police dans Dreamweaver
Comment changer la couleur de la police dans Dreamweaver
 analyses statistiques
analyses statistiques
 La différence entre les services distribués et les microservices
La différence entre les services distribués et les microservices
 Pilote d'appareil photo numérique
Pilote d'appareil photo numérique
 Le rôle du pilote de la carte graphique
Le rôle du pilote de la carte graphique
 css désactiver l'événement de clic
css désactiver l'événement de clic
 csv en vcf
csv en vcf








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



