



La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
L'auteur de cet article, le Dr Pan Liang, est actuellement chercheur scientifique au Laboratoire d'intelligence artificielle de Shanghai. Auparavant, de 2020 à 2023, il a été chercheur au S-Lab de l'Université technologique de Nanyang à Singapour, et son conseiller était le professeur Liu Ziwei. Ses recherches portent sur la vision par ordinateur, les nuages de points 3D et les humains virtuels, et il a publié plusieurs articles dans les meilleures conférences et revues, avec plus de 2 700 citations Google Scholar. En outre, il a été réviseur pour les meilleures conférences et revues dans les domaines de la vision par ordinateur et de l'apprentissage automatique.
Récemment, le S-Lab du Centre commun de recherche sur l'IA de l'Université technologique SenseTime-Nanyang, le Laboratoire d'intelligence artificielle de Shanghai, l'Université de Pékin et l'Université du Michigan ont proposé conjointement DreamGaussian4D (DG4D), qui combine la modélisation explicite de la transformation spatiale avec des éclaboussures gaussiennes 3D statiques ( GS) permet une génération efficace de contenu en quatre dimensions.
La génération de contenu en quatre dimensions a fait des progrès significatifs récemment, mais les méthodes existantes présentent des problèmes tels qu'un long temps d'optimisation, de mauvaises capacités de contrôle de mouvement et une faible qualité des détails. DG4D propose un cadre global contenant deux modules principaux : 1) Image vers 4D GS - nous utilisons d'abord DreamGaussianHD pour générer du GS 3D statique, puis générons une génération dynamique basée sur la déformation gaussienne basée sur HexPlane 2) Affinement de texture vidéo vers vidéo - nous La carte de texture spatiale UV résultante est affinée et sa cohérence temporelle est améliorée grâce à l'utilisation d'un modèle de diffusion image-vidéo pré-entraîné.
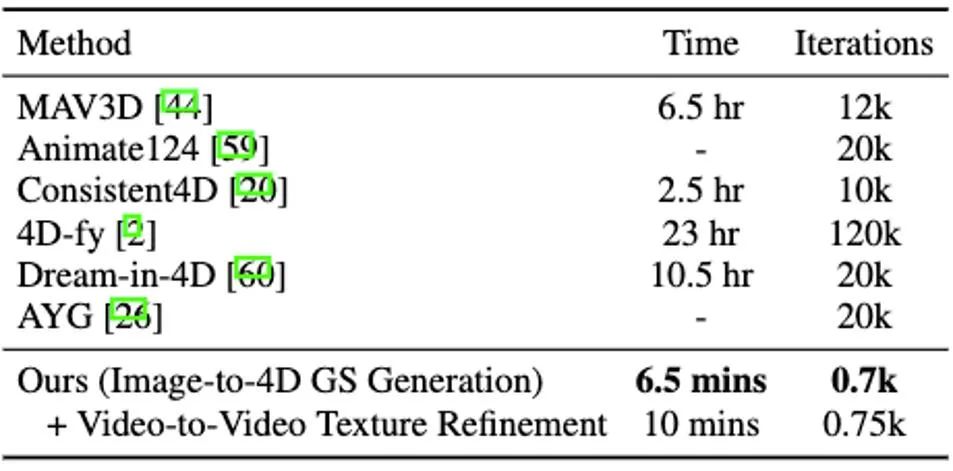
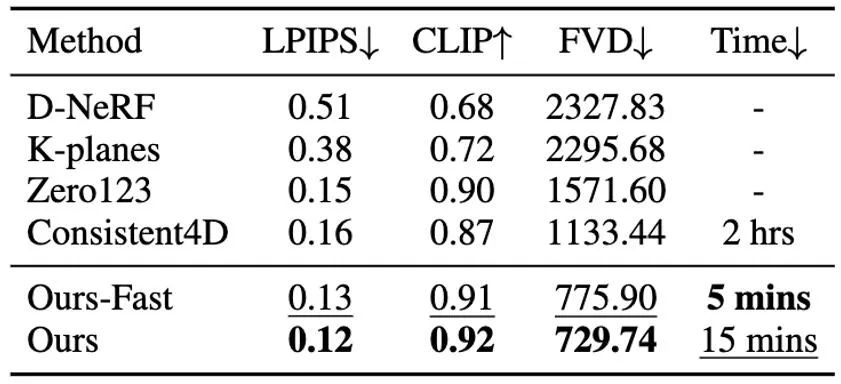
Il convient de noter que DG4D réduit le temps d'optimisation de la génération de contenu tridimensionnel de quelques heures à quelques minutes (comme le montre la figure 1), permet un contrôle visuel du mouvement tridimensionnel généré et prend en charge la génération d'images qui peuvent être rendu réaliste dans un moteur de maillage animé en trois dimensions.

Nom du papier : DreamGaussian4D : Generative 4D Gaussian Splatting
Adresse de la page d'accueil : https://jiawei-ren.github.io/projects/dreamgaussian4d/
Adresse du papier : https:// arxiv.org/abs/2312.17142
Adresse de démonstration : https://huggingface.co/spaces/jiawei011/dreamgaussian4d

demi-minutes Optimisation de la convergence de base
Problèmes et défis
Les modèles génératifs peuvent grandement simplifier la production et la production de divers contenus numériques tels que des images 2D, des vidéos et des scènes 3D, et ont fait des progrès significatifs ces dernières années. Le contenu en quatre dimensions est une forme de contenu importante pour de nombreuses tâches en aval telles que les jeux, les films et la télévision. Le contenu généré en quatre dimensions doit également prendre en charge l'importation de logiciels de moteur de rendu graphique traditionnels (tels que Blender ou Unreal Engine) pour se connecter au pipeline de production de contenu graphique existant (voir Figure 2).
Bien qu'il existe certaines études consacrées à la génération dynamique en trois dimensions (c'est-à-dire en quatre dimensions), il existe encore des défis dans la génération efficace et de haute qualité de scènes en quatre dimensions. Ces dernières années, de plus en plus de méthodes de recherche ont été utilisées pour générer du contenu en quatre dimensions en combinant des modèles de génération vidéo et tridimensionnelle pour limiter la cohérence de l'apparence du contenu et des actions sous n'importe quel angle de vue.

NeRF) a déclaré. Par exemple, MAV3D [1] réalise la génération de contenu texte en quatre dimensions en affinant le modèle de diffusion texte vers vidéo sur HexPlane [2]. Consistent4D [3] introduit un cadre vidéo vers 4D pour optimiser le DyNeRF en cascade afin de générer des scènes 4D à partir de vidéos capturées statiquement. Avec plusieurs modèles de diffusion antérieurs, Animate124 [4] est capable d'animer une seule image 2D non traitée en une vidéo dynamique 3D via une description textuelle du mouvement. Basé sur la technologie hybride SDS [5], 4D-fy [6] permet la génération de texte attrayant en contenu quadridimensionnel à l'aide de plusieurs modèles de diffusion pré-entraînés. Cependant, toutes les méthodes existantes mentionnées ci-dessus [1,3,4,6] nécessitent plusieurs heures pour générer un seul NeRF 4D, ce qui limite grandement leur potentiel d'application. De plus, ils ont tous des difficultés à contrôler ou à sélectionner efficacement le mouvement final généré. Les défauts ci-dessus proviennent principalement des facteurs suivants : premièrement, la représentation quadridimensionnelle implicite sous-jacente de la méthode susmentionnée n'est pas assez efficace, et il existe des problèmes tels qu'une vitesse de rendu lente et une mauvaise régularité des mouvements ; deuxièmement, la nature aléatoire du SDS vidéo ; augmente la difficulté de convergence et, dans les résultats finaux, introduit une instabilité et de multiples artefacts. Introduction à la méthode Différent des méthodes qui optimisent directement 4D NeRF, DG4D construit une représentation efficace et puissante pour la génération de contenu 4D en combinant la technologie d'éclaboussure gaussienne statique et la modélisation de transformation spatiale explicite. De plus, les méthodes de génération vidéo ont le potentiel de fournir des a priori spatio-temporels précieux qui améliorent la génération 4D de haute qualité. Plus précisément, nous proposons un cadre global composé de deux étapes principales : 1) la génération d'images vers 4D GS ; 2) le raffinement de cartes de texture basées sur un grand modèle vidéo. D1. La génération de l'image en 4D GS
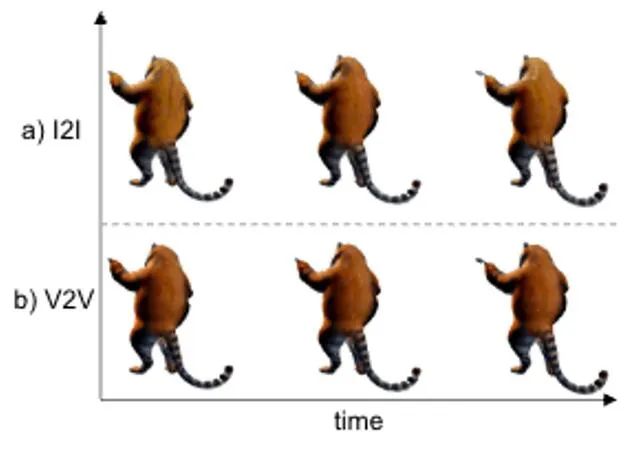
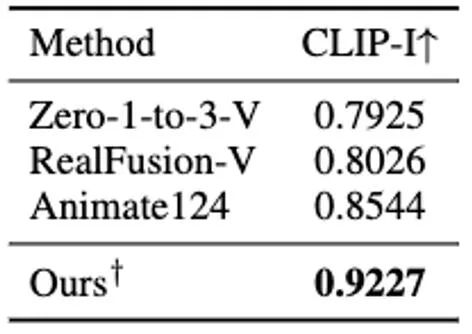
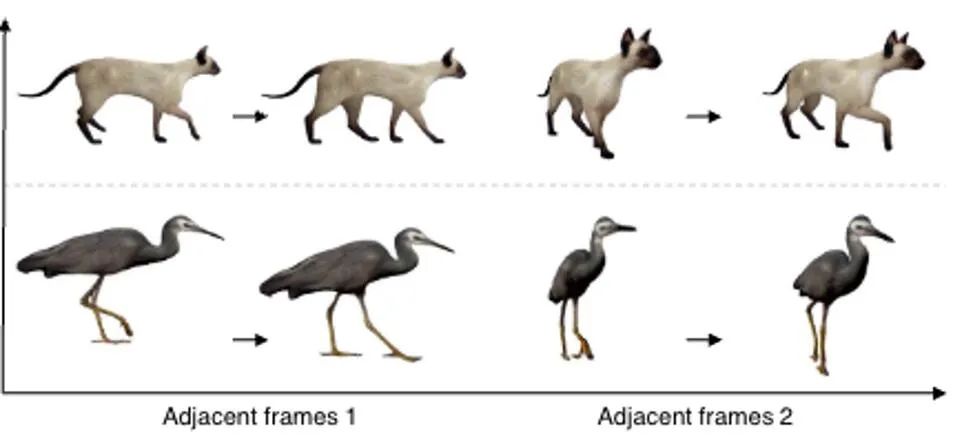
Dans cette étape, nous utilisons la 3D GS statique et sa déformation spatiale pour indiquer la dynamique dynamique quatre- scène dimensionnelle. Sur la base d'une image 2D donnée, nous générons des GS 3D statiques en utilisant la méthode améliorée DreamGaussianHD. Par la suite, en optimisant le champ de déformation dépendant du temps sur la fonction GS 3D statique, la déformation gaussienne à chaque horodatage est estimée, dans le but de rendre la forme et la texture de chaque image déformée cohérente avec l'image correspondante dans la vidéo de conduite. A la fin de cette étape, une séquence dynamique de modèle de maillage tridimensionnel sera générée. Sur la base de la récente méthode graphique d'objet 3D DreamGaussian [7] utilisant 3D GS, nous avons apporté d'autres améliorations et compilé un ensemble de meilleures Méthodes de génération et d'initialisation de GS 3D. Les principales opérations améliorées incluent 1) l'adoption d'une méthode d'optimisation multi-vues ; 2) le réglage de l'arrière-plan de l'image rendue pendant le processus d'optimisation sur un arrière-plan noir plus adapté à la génération. Nous appelons la version améliorée DreamGaussianHD, et les rendus d'amélioration spécifiques sont visibles dans la figure 4. Figure 5 HexPlane représente le champ de déformation dynamique Sur la base du modèle GS 3D statique généré, nous générons des vidéos qui répondent aux attentes en prédisant la déformation du noyau gaussien dans chaque image du modèle GS 4D dynamique. En termes de caractérisation des effets dynamiques, nous choisissons HexPlane (illustré à la figure 5) pour prédire le déplacement, la rotation et l'échelle du noyau gaussien à chaque horodatage, pilotant ainsi la génération d'un modèle dynamique pour chaque image. En outre, nous avons également ajusté le réseau de conception de manière ciblée, en particulier la conception de connexion résiduelle et d'initialisation nulle pour les dernières couches du réseau d'opérations linéaires, afin que le champ dynamique puisse être initialisé en douceur et entièrement sur la base du modèle GS 3D statique ( l'effet est comme indiqué sur la figure) montrée en 6).始 Figure 6 L'impact de l'initialisation de la formation dynamique sur la génération finale du champ dynamique Figure 7 Optimisation de la texture vidéo en vidéo Diagramme de trame Semblable à DreamGaussian, après la première étape de génération de modèle dynamique à quatre dimensions basée sur 4D GS, la séquence de modèle de maillage à quatre dimensions peut être extraite. De plus, nous pouvons également optimiser davantage la texture dans l'espace UV du modèle de maillage, similaire à ce que fait DreamGaussian. Contrairement à DreamGaussian, qui utilise uniquement des modèles de génération d'images pour optimiser les textures des modèles de maillage 3D individuels, nous devons optimiser l'intégralité de la séquence de maillage 3D. De plus, nous avons constaté que si nous suivons l'approche de DreamGaussian, c'est-à-dire effectuons une optimisation de texture indépendante pour chaque séquence de maillage 3D, la texture du maillage 3D sera générée de manière incohérente à différents horodatages, et il y aura souvent un scintillement, etc. . Des artefacts défectueux apparaissent. Compte tenu de cela, nous nous différencions de DreamGaussian et proposons une méthode d’optimisation de texture vidéo à vidéo dans l’espace UV basée sur un grand modèle de génération vidéo. Plus précisément, nous avons généré de manière aléatoire une série de trajectoires de caméra au cours du processus d'optimisation, rendu plusieurs vidéos sur cette base et effectué l'ajout et le débruitage correspondants sur les vidéos rendues pour obtenir la génération de séquences d'amélioration de la texture du modèle de maillage. La comparaison des effets d'optimisation de texture liés à la génération d'un grand modèle basé sur des images et à la génération d'un grand modèle basé sur des vidéos est présentée dans la figure 8. Résultats expérimentaux Par rapport à la méthode précédente d'optimisation globale de 4D NeRF, DG4D a considérablement réduit le temps nécessaire pour générer du contenu en quatre dimensions. La comparaison temporelle spécifique peut être vue dans le tableau 1. Rapport de cohérence dans le tableau 2. Pour le paramètre de génération de contenu en quatre dimensions basé sur la vidéo, la comparaison des résultats numériques de la méthode de génération de contenu en quatre dimensions à partir de la vidéo peut être vue dans le tableau 3.生 Tableau 3 Sur la base des résultats numériques du contenu quadridimensionnel généré par la vidéo, résultats de comparaison De plus, nous échantillonnons également les échantillons d'utilisateurs de chaque méthode de l'image unique qui correspond le plus à notre test, les résultats des tests sont rapportés dans le tableau 4.生 Tableau 4 Test utilisateur basé sur le contenu quadridimensionnel généré par une seule image DG4D et le graphe SOTA open source existant génère l'effet de la méthode de contenu quadridimensionnel et de la vidéo générant des méthodes de contenu quadridimensionnel, qui sont affichés respectivement sur la figure 9 et sur la figure 10 .内容 Figure 9 Figure 9 Figure Comparaison des effets de contenu en 4 dimensions Figure 10 Comparaison des effets de contenu en quatre dimensions de Video Sheng Figure Darüber hinaus haben wir auch statische 3D-Inhalte basierend auf der aktuellen direkten Feedforward-Methode zur Generierung von 3D-GS aus einem einzelnen Bild generiert (d. h. ohne Verwendung der SDS-Optimierungsmethode) und die Generierung dynamischer 4D-GS auf dieser Grundlage initialisiert. Durch die direkte Feedforward-Generierung von 3D-GS können qualitativ hochwertigere und vielfältigere 3D-Inhalte schneller erzeugt werden als auf SDS-Optimierung basierende Methoden. Der daraus resultierende vierdimensionale Inhalt ist in Abbildung 11 dargestellt.生 Abbildung 11 Der vierdimensionale dynamische Inhalt, der basierend auf der Methode zur Generierung von 3D-GS generiert wurde Fazit
Basierend auf 4D GS schlagen wir DreamGaussian4D (DG4D) vor, ein effizientes Framework zur Bild-zu-4D-Generierung. Im Vergleich zu bestehenden vierdimensionalen Content-Generierungs-Frameworks reduziert DG4D die Optimierungszeit erheblich von Stunden auf Minuten. Darüber hinaus demonstrieren wir die Verwendung generierter Videos zur angetriebenen Bewegungsgenerierung, wodurch eine visuell kontrollierbare 3D-Bewegungsgenerierung erreicht wird.
Referenzen [1] Tagungsband der 40. Internationalen Konferenz über maschinelles Lernen. 2] Cao et al. „Hexplane: Eine schnelle Darstellung für dynamische Szenen.“ [3] Jiang et al 360° dynamische Objektgenerierung aus monokularem Video.“ Die zwölfte internationale Konferenz zum Thema Lernen von Repräsentationen. 2023 (2023). [5] „DreamFusion: Text-to-3D using 2D Diffusion.“ Die elfte internationale Konferenz über Lerndarstellungen , Sherwin, et al. „4d-fy: Text-to-4d-Generierung mit Hybrid-Score-Destillation“ arXiv:2311.17984 (2023). [7] Tang et al Gaußsches Splatting für die effiziente Erstellung von 3D-Inhalten.“ Die zwölfte internationale Konferenz zum Thema Lernen von Repräsentationen. 2023.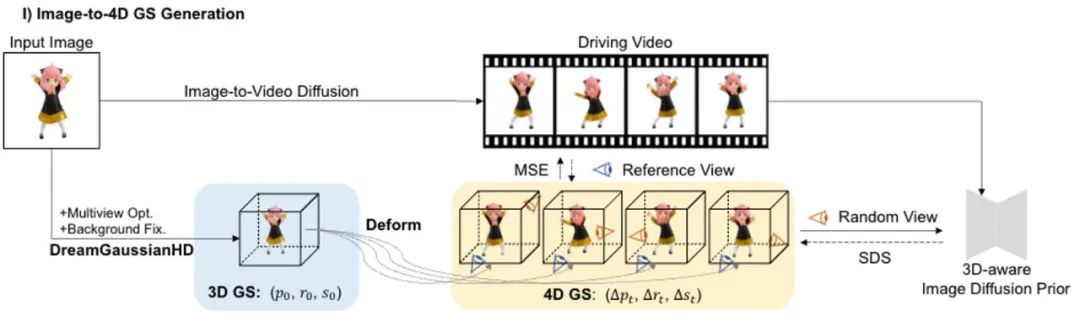

2. Optimisation de l'eau de vidéo en vidéo


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Vérifier l'occupation du port sous Linux
Vérifier l'occupation du port sous Linux
 Comment ouvrir le format TIF sous Windows
Comment ouvrir le format TIF sous Windows
 Quels sont les logiciels de dessin ?
Quels sont les logiciels de dessin ?
 Quelles sont les méthodes de stockage des données ?
Quelles sont les méthodes de stockage des données ?
 Comment utiliser l'instruction insert dans MySQL
Comment utiliser l'instruction insert dans MySQL
 Temps de panne du service Windows 10
Temps de panne du service Windows 10
 Collection de touches de raccourci informatique
Collection de touches de raccourci informatique
 Comment résoudre le problème de steam_api.dll manquant
Comment résoudre le problème de steam_api.dll manquant








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



