A total of 5 outstanding paper awards and 11 honorable mentions were selected this year.
ICLR stands for International Conference on Learning Representations. This year is the 12th conference, held in Vienna, Austria, from May 7th to 11th.
In the machine learning community, ICLR is a relatively "young" top academic conference. It is hosted by deep learning giants and Turing Award winners Yoshua Bengio and Yann LeCun. It just held its first session in 2013. However, ICLR quickly gained wide recognition from academic researchers and is considered the top academic conference on deep learning.
This conference received a total of 7262 submitted papers and accepted 2260 papers. The overall acceptance rate was about 31%, which was the same as last year (31.8%). In addition, the proportion of Spotlights papers is 5% and the proportion of Oral papers is 1.2%.


Compared with previous years, whether it is the number of participants or the number of paper submissions, the popularity of ICLR can be said to have greatly improved. .
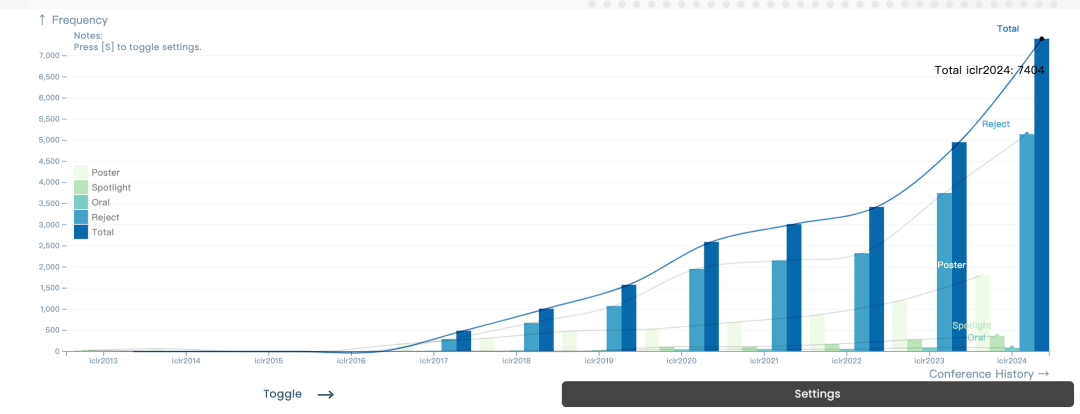
## Previous ICLR paper data chart
Among the award-winning papers announced recently, the conference selected 5 Outstanding Paper Awards and 11 Honorable Mention Awards.
5 Outstanding Paper Awards
Outstanding Paper winners
Paper: Generalization in diffusion models arises from geometry -adaptive harmonic representations

- Paper address: https://openreview.net/pdf?id=ANvmVS2Yr0
- Institution: New York University, Collège de France
- Author: Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane Mallat
This article provides an important in-depth analysis of the generalization and memory aspects of the image diffusion model. The authors empirically study when an image generation model switches from memory input to generalization mode, and connect it with the idea of harmonic analysis through geometrically adaptive harmonic representation, further explaining this phenomenon from the perspective of architectural induction bias. This article covers a key missing piece in our understanding of generative models of vision and has great implications for future research.
Thesis: Learning Interactive Real-World Simulators

- Thesis address: https://openreview. net/forum?id=sFyTZEqmUY
- Institutions: UC Berkeley, Google DeepMind, MIT, University of Alberta
- Author: Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
Aggregating data across multiple sources to train base models for robots is a long-term goal. Since different robots have different sensorimotor interfaces, this poses significant challenges to training across large-scale datasets.
UniSim is an important step in this direction and an engineering feat that leverages a unified interface based on textual descriptions of visual perception and control to aggregate data and Train robot simulators by leveraging recent developments in vision and language.
In summary, this article explores UniSim, a general-purpose simulator that learns real-world interactions through generative models, and takes the first step in building a general-purpose simulator. For example, UniSim can simulate how humans and agents interact with the world by simulating high-level instructions such as "open a drawer" and the visual results of low-level instructions.
This paper combines large amounts of data (including Internet text-image pairs, rich data from navigation, human activities, robot actions, etc., and data from simulations and renderings) into a conditional video generation framework. Then by carefully orchestrating rich data along different axes, this paper shows that UniSim can successfully merge experience from different axes of data and generalize beyond the data to enable rich interactions through fine-grained motion control of static scenes and objects.
As shown in Figure 3 below, UniSim can simulate a series of rich actions, such as washing hands, taking bowls, cutting carrots, and drying hands in a kitchen scene; the upper right of Figure 3 shows pressing different switches; the bottom of Figure 3 are two navigation scenarios.

## to correspond to the navigation scene in the lower right corner of Figure 3

## The navigation scenario below 3 right
Thesis: Never Train from Scratch: Fair Comparison of Long-sequence Models Requires Data-Driven Priors

- Paper address: https://openreview.net/forum?id=PdaPky8MUn
- Institution: Tel Aviv University, IBM
- Authors: Ido Amos, Jonathan Berant, Ankit Gupta
This paper delves into a recently proposed State space models and transformer architectures have the ability to model long-term sequence dependencies.
Surprisingly, the authors found that training a transformer model from scratch results in its performance being underestimated, and that significant performance gains can be achieved with pre-training and fine-tuning settings. The paper excels in its focus on simplicity and systematic insights.
Paper: Protein Discovery with Discrete Walk-Jump Sampling

- Paper address: https:// openreview.net/forum?id=zMPHKOmQNb
- Institution: Genentech, New York University
- Author: Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi
This paper solves Solving the problem of sequence-based antibody design, this is a timely and important application of protein sequence generation models.
To this end, the author introduces an innovative and effective new modeling method specifically targeted at the problem of processing discrete protein sequence data. In addition to validating the method in silico, the authors performed extensive wet laboratory experiments to measure in vitro antibody binding affinities, demonstrating the effectiveness of their generated method.
Paper: Vision Transformers Need Registers

##Paper address: https://openreview.net/ forum?id=2dnO3LLiJ1
The authors propose key assumptions for why this phenomenon occurs and provide a simple yet elegant solution using additional register tokens to account for these traces, thereby enhancing the model's performance on a variety of tasks. Insights gained from this work could also impact other application areas.
This paper is well written and provides a good example of conducting research: "Identify the problem, understand why it occurs, and then propose a solution."
11 Honorable Mentions
In addition to 5 outstanding papers, ICLR 2024 also selected 11 honorable mentions.
Paper: Amortizing intractable inference in large language models
Institution: University of Montreal, University of Oxford
Paper: Approximating Nash Equilibria in Normal-Form Games via Stochastic Optimization
##Institution: DeepMind
-
Authors: Ian Gemp, Luke Marris, Georgios Piliouras
-
Paper address: https://openreview.net/forum?id=cc8h3I3V4E
-
This is a very clearly written paper that contributes significantly to solving the important problem of developing efficient and scalable Nash solvers.
Paper: Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
- ##Institution: Peking University, Beijing Zhiyuan Artificial Intelligence Research Institute
- Author: Zhang Bohang Gai Jingchu Du Yiheng Ye Qiwei Hedi Wang Liwei
## Paper address: https://openreview.net/forum?id=HSKaGOi7Ar
Paper: Flow Matching on General Geometries
Institution: Meta
Paper: Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
Institution: University of Central Florida, Google DeepMind, University of Amsterdam, etc.
Thesis: Meta Continual Learning Revisited: Implicitly Enhancing Online Hessian Approximation via Variance Reduction
Institutions: City University of Hong Kong, Tencent AI Laboratory, Xi'an Jiaotong University, etc.
Paper: Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
##Institution: University of Illinois at Urbana-Champaign, Microsoft
-
Authors: Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao
-
Paper address: https:/ /openreview.net/forum?id=uNrFpDPMyo
-
This article aims at the KV cache compression problem (this problem has a great impact on Transformer-based LLM) and uses a simple idea to reduce memory. And it can be deployed without extensive resource-intensive fine-tuning or retraining. This method is very simple and has proven to be very effective.
Paper: Proving Test Set Contamination in Black-Box Language Models
##Institution: Stanford University, Columbia University
Authors: Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, Tatsunori Hashimoto
Paper address: https://openreview.net/forum?id= KS8mIvetg2
This paper uses a simple and elegant method for testing whether a supervised learning dataset has been included in the training of a large language model.
Paper: Robust agents learn causal world models
Institution: Google DeepMind
Author: Jonathan Richens, Tom Everitt
Paper address: https://openreview.net/forum?id=pOoKI3ouv1
This paper was laid down Considerable progress has been made in the theoretical foundations for understanding the role of causal reasoning in an agent's ability to generalize to new domains, with implications for a range of related fields.
Paper: The mechanistic basis of data dependence and abrupt learning in an in-context classification task
Institution: Princeton University, Harvard University, etc.
Author: Gautam Reddy
Paper address: https://openreview.net/forum?id=aN4Jf6Cx69
This is a timely and extremely systematic study that explores the mechanisms between in-context learning and in-weight learning as we begin to understand these phenomena.
Thesis: Towards a statistical theory of data selection under weak supervision
Institution: Granica Computing
Authors: Germain Kolossov, Andrea Montanari, Pulkit Tandon
Paper address: https://openreview.net/forum?id=HhfcNgQn6p
This paper establishes a statistical foundation for data subset selection and identifies the shortcomings of popular data selection methods.
Reference link: https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/
The above is the detailed content of 7262 papers were submitted, ICLR 2024 became a hit, and two domestic papers were nominated for outstanding papers.. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



