


Static object detection (SOD), including traffic lights, guide signs and traffic cones, most algorithms are data-driven deep neural networks and require a large amount of training data. Current practice typically involves manual annotation of large numbers of training samples on LiDAR-scanned point cloud data to fix long-tail cases.

Manual annotation is difficult to capture the variability and complexity of real scenes, and often fails to take into account occlusions, different lighting conditions and diverse viewing angles (yellow arrow in Figure 1) . The whole process has long links, is extremely time-consuming, error-prone, and costly (Figure 2). So currently companies are looking for automatic labeling solutions, especially based on pure vision. After all, not every car has lidar.
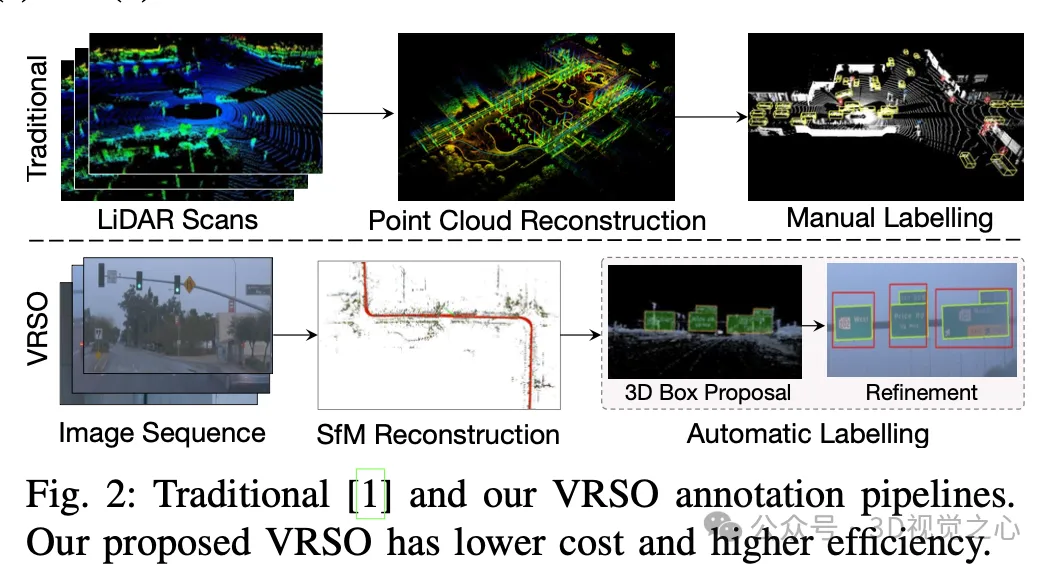
VRSO is a vision-based annotation system for static object annotation. It mainly uses information from SFM, 2D object detection and instance segmentation results. Overall effect: The average projection error of
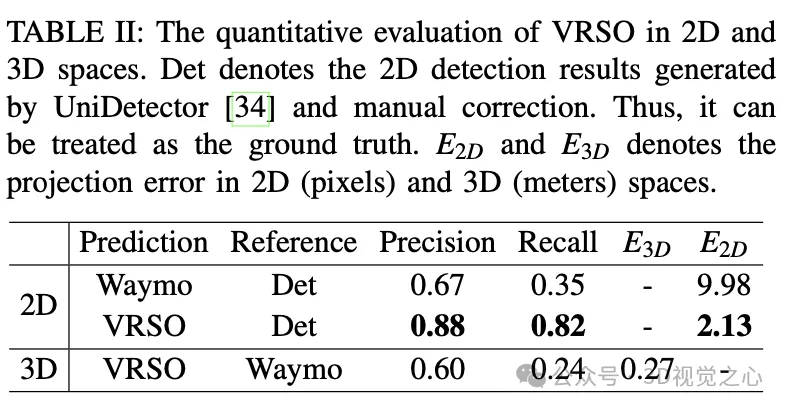
For static objects, VRSO solves the challenge of integrating and deduplicating static objects from different viewing angles through instance segmentation and contour extraction of key points, as well as the difficulty of insufficient observation due to occlusion issues , thus improving the accuracy of labeling. From Figure 1, compared with the manual annotation results of the Waymo Open dataset, VRSO demonstrates higher robustness and geometric accuracy.
(You’ve all seen this, why not slide your thumb up and click on the top card to follow me. The whole operation will only take you 1.328 seconds, and then take away all the useful information in the future. What if it works~)
The VRSO system is mainly divided into two parts: Scene reconstruction and Static objects are marked .
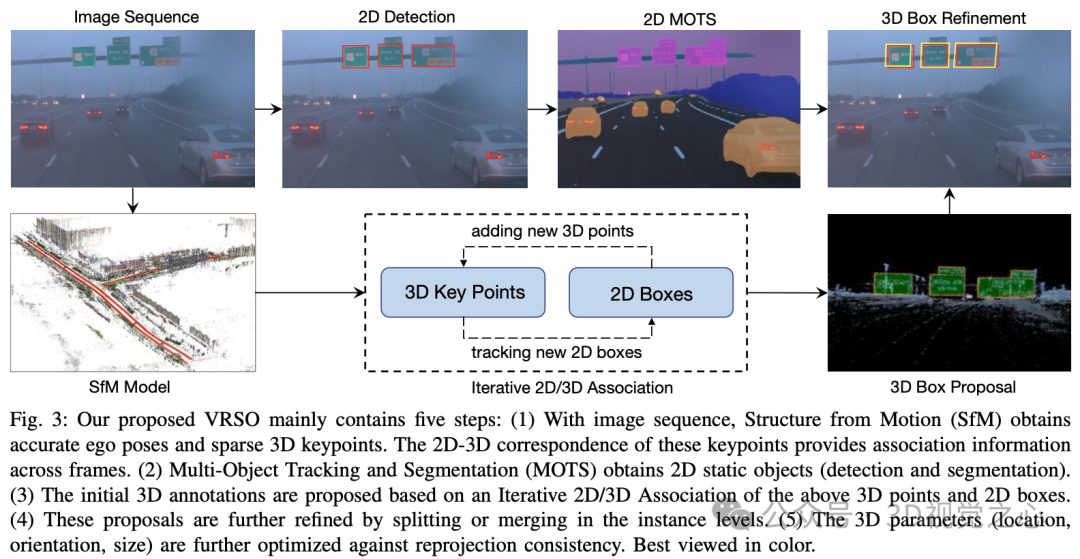
#The reconstruction part is not the focus, it is based on the SFM algorithm to restore the image pose and sparse 3D key points.
Static object annotation algorithm, combined with pseudo code, the general process is (the following will be detailed step by step):

Initialize the 3D frame parameters (position, direction, size) of the static object for the entire video clip. Each key point of SFM has an accurate 3D position and corresponding 2D image. For each 2D instance, feature points within the 2D instance mask are extracted. Then, a set of corresponding 3D keypoints can be considered as candidates for 3D bounding boxes.
Street signs are represented as rectangles with directions in space, which have 6 degrees of freedom, including translation (,,), direction (θ) and size (width and height). Given its depth, a traffic light has 7 degrees of freedom. Traffic cones are represented similarly to traffic lights.
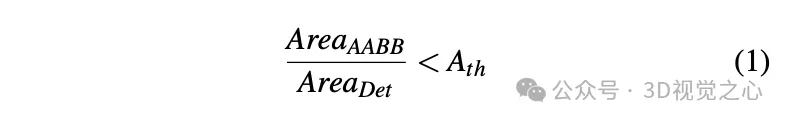
Obtain the initial vertex value of the static object under 3D conditions through triangulation.
By checking the number of keypoints in the 3D bounding boxes obtained by SFM and instance segmentation during scene reconstruction, only instances with the number of keypoints exceeding the threshold are considered stable and valid observations. For these instances, the corresponding 2D bounding box is considered a valid observation. Through 2D observation of multiple images, the vertices of the 2D bounding box are triangulated to obtain the coordinates of the bounding box.
For circular signs that do not distinguish the "lower left, upper left, upper right, upper right, and lower right" vertices on the mask, these circular signs need to be identified. 2D detection results are used as observations of circular objects, and 2D instance segmentation masks are used for contour extraction. The center point and radius are calculated through a least squares fitting algorithm. The parameters of the circular sign include the center point (,,), direction (θ) and radius ().
Tracking feature point matching based on SFM. Determine whether to merge these separated instances based on the Euclidean distance of the 3D bounding box vertices and the 2D bounding box projection IoU. Once merging is complete, 3D feature points within an instance can be clustered to associate more 2D feature points. Iterative 2D-3D association is performed until no 2D feature points can be added.
Taking the rectangular sign as an example, the parameters that can be optimized include position (,,) and direction (θ) and size (,), for a total of six degrees of freedom. The main steps include:


There are also some challenging long-tail cases, such as extremely low resolution and insufficient lighting.

The VRSO framework achieves high-precision and consistent 3D annotation of static objects, tightly integrating detection, segmentation and The SFM algorithm eliminates manual intervention in intelligent driving annotation and provides results comparable to LiDAR-based manual annotation. Qualitative and quantitative evaluations were conducted with the widely recognized Waymo Open Dataset: compared with manual annotation, the speed is increased by about 16 times, while maintaining the best consistency and accuracy.
The above is the detailed content of Efficiency increased by 16 times! VRSO: 3D annotation of purely visual static objects, opening up the data closed loop!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



