


Yuanxiang released the XVERSE-MoE-A4.2B large model, which adopts the industry's most cutting-edge mixed expert model architecture (Mixture of Experts) and activates parameter 4.2B, and the effect is comparable to the 13B model. This model is fully open source and unconditionally free for commercial use, allowing a large number of small and medium-sized enterprises, researchers and developers to use it on demand in Yuanxiang's high-performance "family bucket", promoting low-cost deployment.

The development of mainstream large models such as GPT3, Llama and XVERSE follows the Scaling Law. In the process of model training and inference, a single forward and reverse calculation When, all parameters are activated, which is called Dense activation (densely activated). When the model scale increases, the computing power cost will increase sharply.
As more and more researchers believe that the sparsely activated MoE model can be more effective without significantly increasing the computational cost of training and inference when increasing the model size. Methods. Because the technology is relatively new, most open source models or academic research in China are not yet popular.
In the element self-research, using the same corpus to train 2.7 quadrillion tokens, XVERSE-MoE-A4.2B actually activated 4.2B parameters, and the performance "jumped" beyond XVERSE-13B-2, only the amount of calculation , and reduce training time by 50%. Compared with multiple open source benchmarks Llama, this model significantly surpasses Llama2-13B and is close to Llama1-65B (picture below).
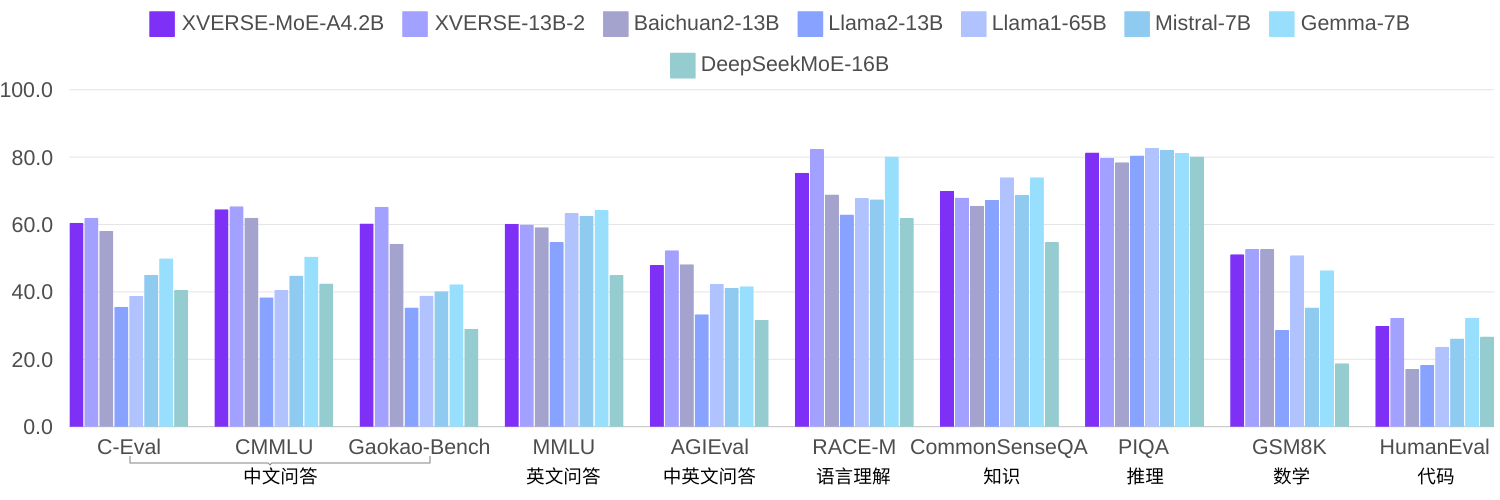
View multiple authoritative reviews
In terms of open source, the element large model "Family Bucket" continues to iterate, leading domestic open source to the world's first-class level. In terms of application, Element leverages the unique advantages of AI 3D technology and launches one-stop solutions such as large model 3D space and AIGC tools, empowering various industries such as entertainment, tourism, and finance, and provides intelligent customer service, creative experience, efficiency improvement tools, etc. Create a leading user experience in multiple scenarios.
MoETechnological self-research and innovation
The Ministry of Education (MoE) is the most cutting-edge model framework in the industry. Due to the relatively new technology, domestic Open source models or academic research are not yet widespread. MetaObject independently developed MoE's efficient training and inference framework, and innovated in three directions:
In terms of performance, a set of efficient fusion operators were developed based on the unique expert routing and weight calculation logic in the MoE architecture, which significantly This significantly improves computing efficiency; in view of the challenges of high memory usage and large communication volume in the MoE model, overlapping operations of computing, communication and memory offloading are designed to effectively improve the overall processing throughput.
In terms of architecture, unlike traditional MoE (such as Mixtral 8x7B), which equates the size of each expert to the standard FFN, Yuanxiang adopts a more fine-grained expert design, and the size of each expert is only one-quarter of the standard FFN. First, it improves model flexibility and performance; it also divides experts into two categories: Shared Experts and Non-shared Experts. Shared experts remain active during calculations, while non-shared experts are selectively activated as needed. This design is conducive to compressing general knowledge into shared expert parameters and reducing knowledge redundancy among non-shared expert parameters.
In terms of training, inspired by Switch Transformers, ST-MoE and DeepSeekMoE, Yuanxiang introduces the load balancing loss term to better balance the load among experts; the router z-loss term is used to ensure efficient and stable training.
The architecture selection was obtained through a series of comparative experiments (picture below). In Experiment 3 and Experiment 2, the total parameter amount and activation parameter amount were the same, but the fine-grained expert design of the former brought higher performance Performance. On this basis, Experiment 4 further divided experts into two types: shared and non-shared, which significantly improved the effect. Experiment 5 explores the method of introducing shared experts when the expert size is equal to the standard FFN, but the effect is not ideal.
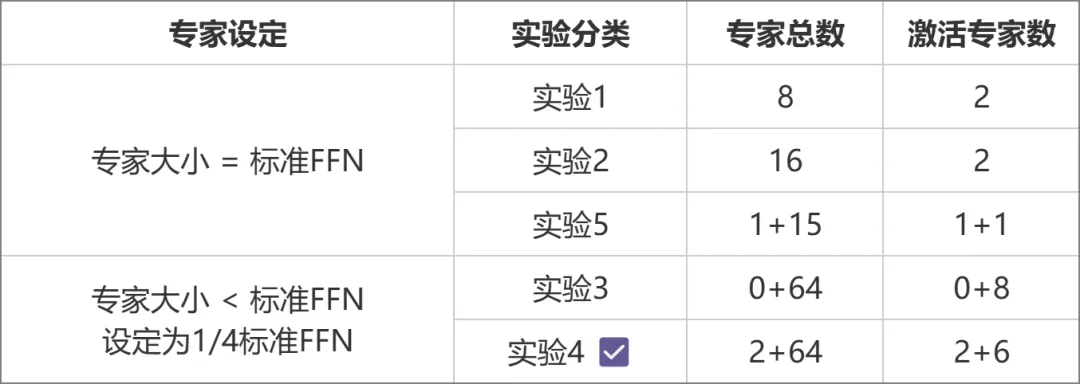
Comparing the experimental design plan
Comprehensive test results (picture below), Yuanxiang finally adopted the architecture settings corresponding to Experiment 4. Looking to the future, the newly open sourced projects such as Google Gemma and
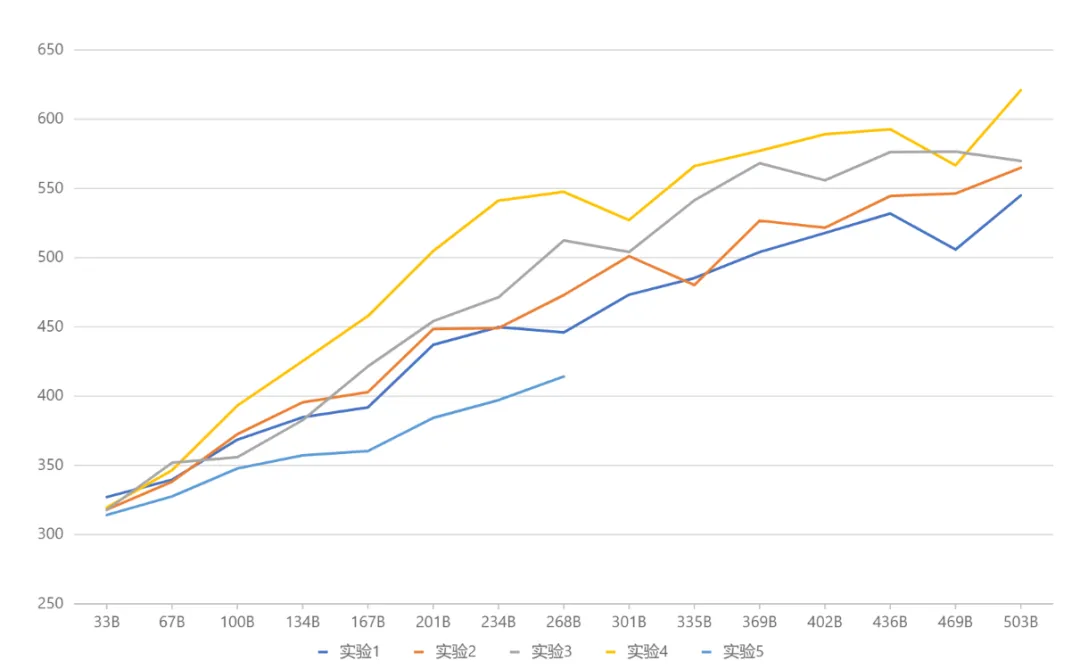
Compare experimental results
Free download of large model
The above is the detailed content of Yuanxiang's first MoE large model is open source: 4.2B activation parameters, the effect is comparable to the 13B model. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



