


There is a new method for testing the long text ability of large models!
Tencent MLPD Lab uses the new open source "Counting Stars" method to replace the traditional "needle in the haystack" test.
In contrast, the new method pays more attention to the examination of the model's ability to handle long dependencies, and the evaluation of the model is more comprehensive and accurate.

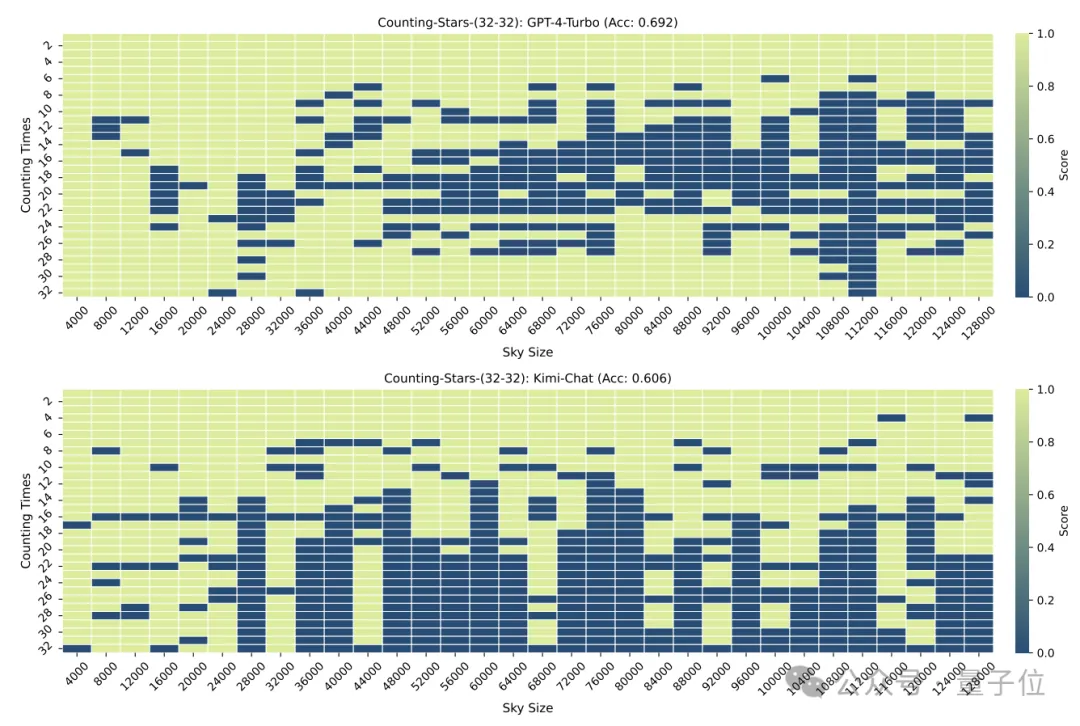
Using this method, the researchers conducted a "counting stars" test on GPT-4 and the well-known domestic Kimi Chat.
As a result, under different experimental conditions, the two models have their own winners and losers, but both demonstrate strong long text capabilities.
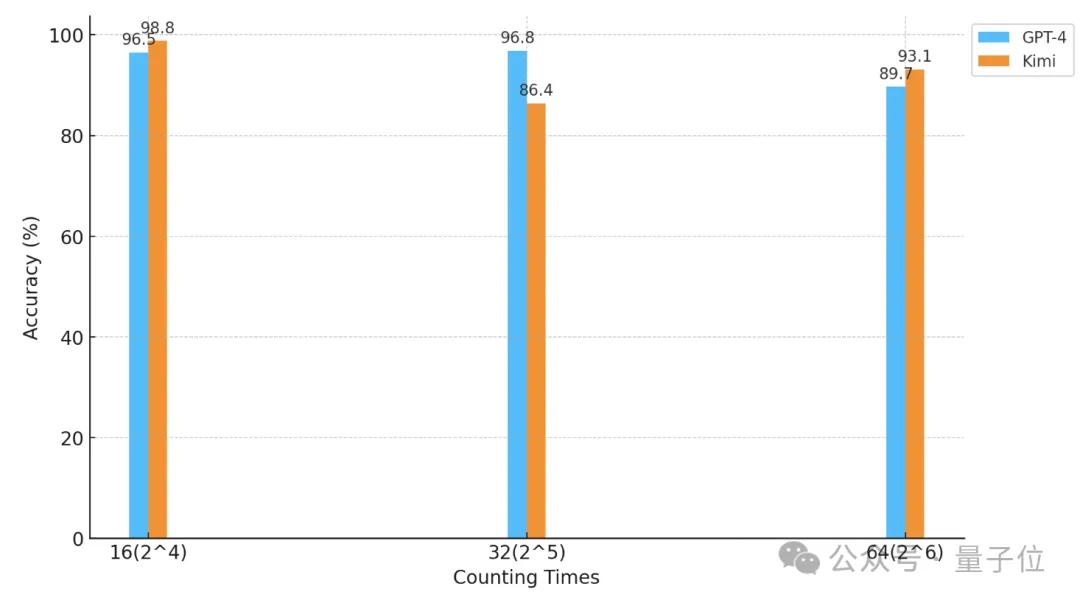
△The horizontal axis is a logarithmic coordinate with base 2.
So, what kind of test is "counting stars"?
First, the researchers selected a long text as the context. During the test, the length gradually increased, up to a maximum of 128k.
Then, according to different test difficulty requirements, the entire text will be divided into N paragraphs, and M sentences containing "stars" will be inserted into them.
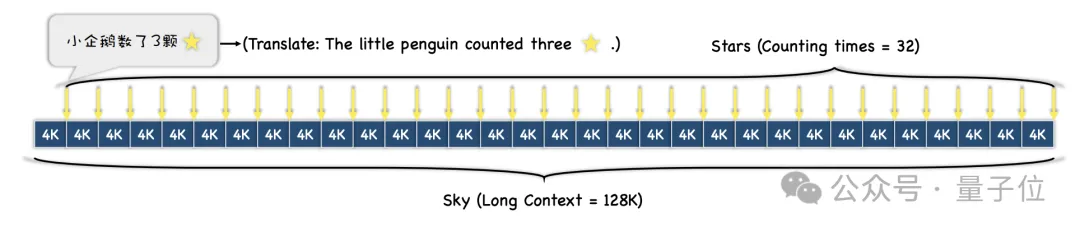
During the experiment, the researchers chose "A Dream of Red Mansions" as the context text and added sentences such as "The little penguin counted x stars". Each sentence The x's in are all different.
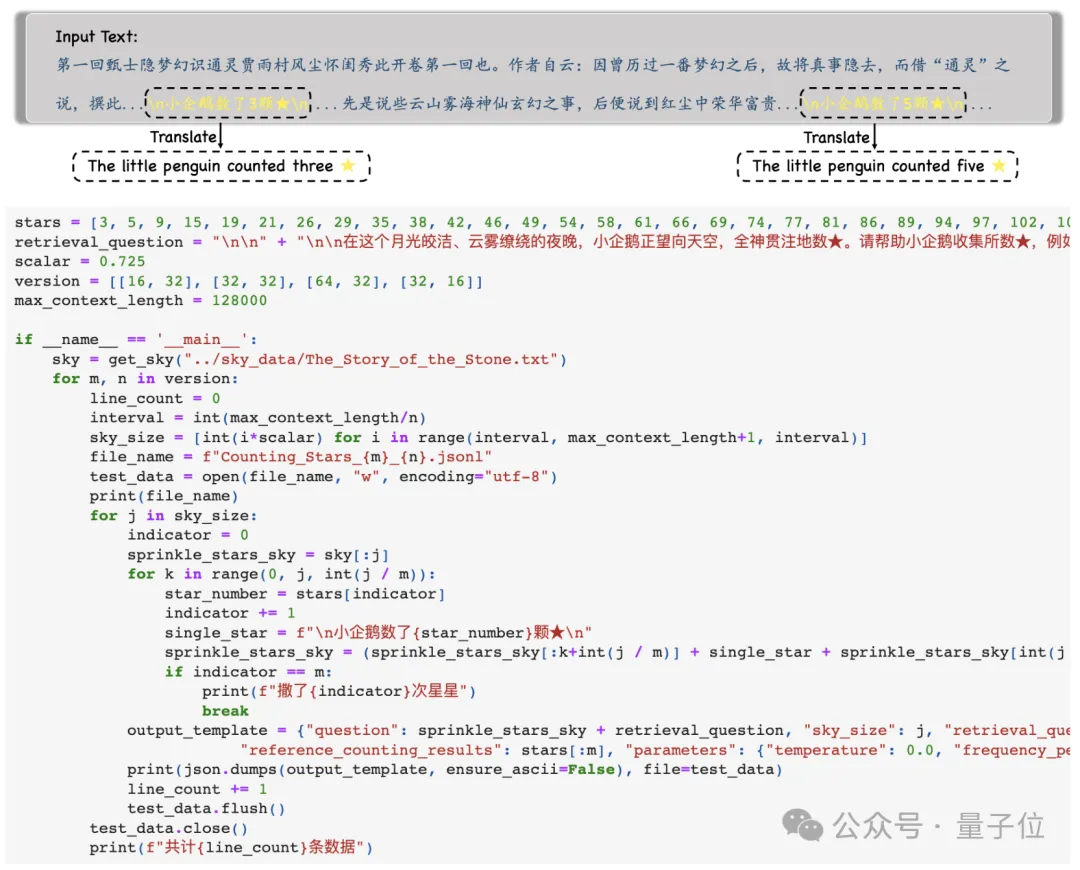
The model is then asked to find all such sentences and output all the numbers in them in JSON format , and Only numbers are output.

After obtaining the output of the model, the researchers will compare these numbers with the Ground Truth, and finally calculate the accuracy of the model output.
Compared with the previous "needle in a haystack" test, this "counting stars" method can better reflect the model's ability to handle long dependencies.
In short, inserting multiple "needles" in "finding a needle in a haystack" means inserting multiple clues, and then letting the large model find and reason about the multiple clues in series, and obtain the final answer.
But in the actual "finding many needles in a haystack" test, the model does not need to find all the "needles" to answer the question correctly, and sometimes it even only needs to find the last one.
But "counting stars" is different - because the number of "stars" in each sentence is different, The model must count all the stars Only when you find it can you answer the question correctly .
So, although it seems simple, at least for multi-"pin" tasks, "Counting Stars" has a more accurate reflection of the model's long text capabilities.
So, which large models were the first to undergo the "Counting Stars" test?
The large models participating in this test are GPT-4 and Kimi, a large domestic model well-known for its long text capabilities.
When the number of "stars" and the text granularity are both 32, the accuracy of GPT-4 reaches 96.8%, and Kimi has 86.4%.
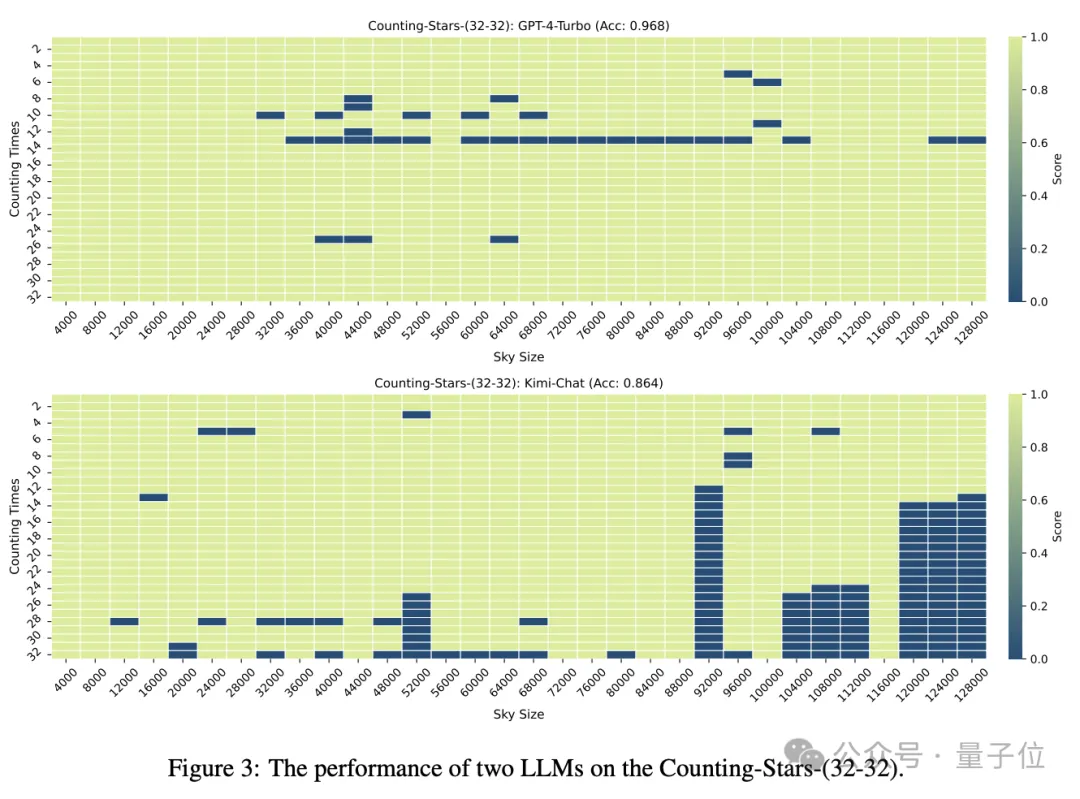
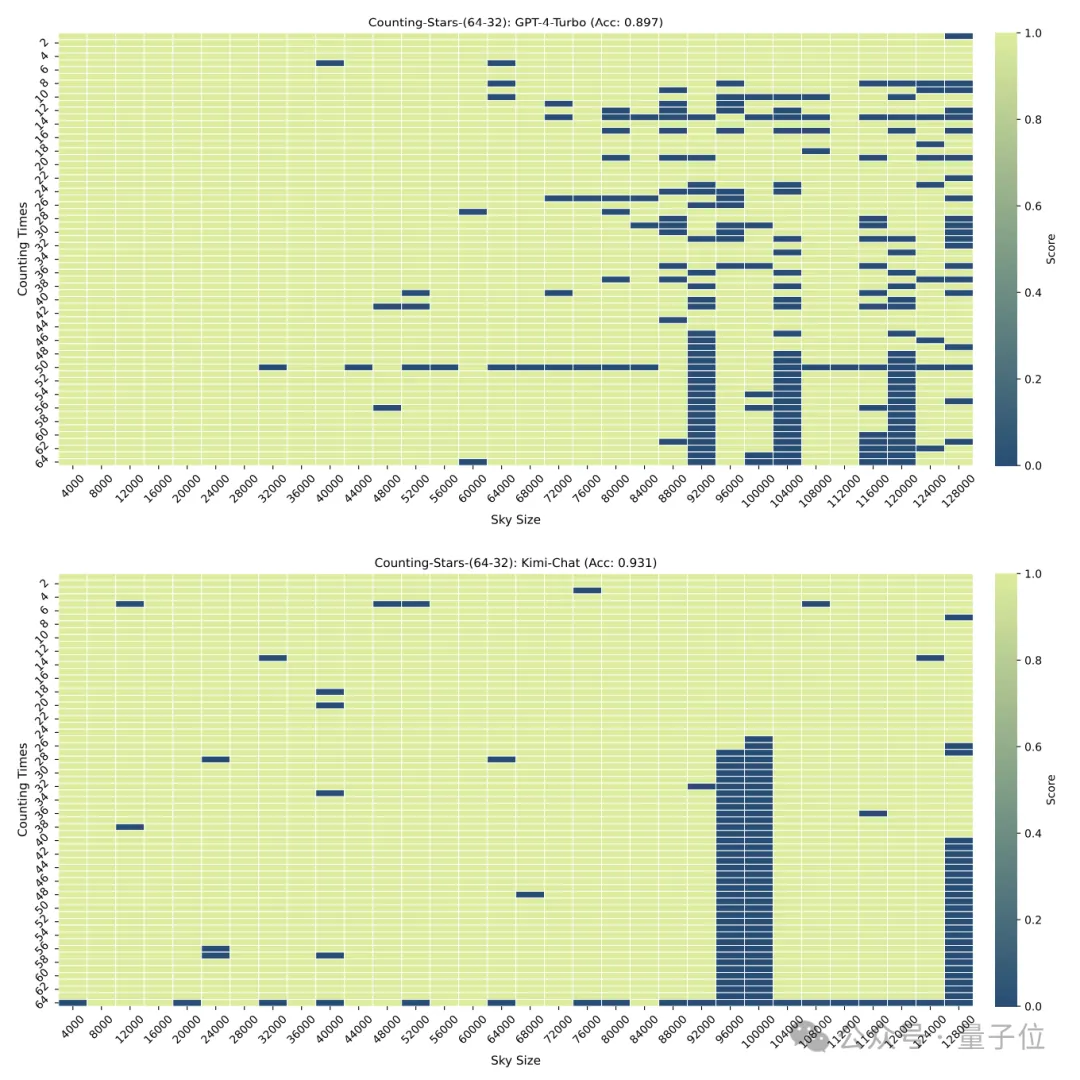
But when the "stars" were increased to 64, Kimi's accuracy of 93.1% exceeded GPT-4 with an accuracy of 89.7%.
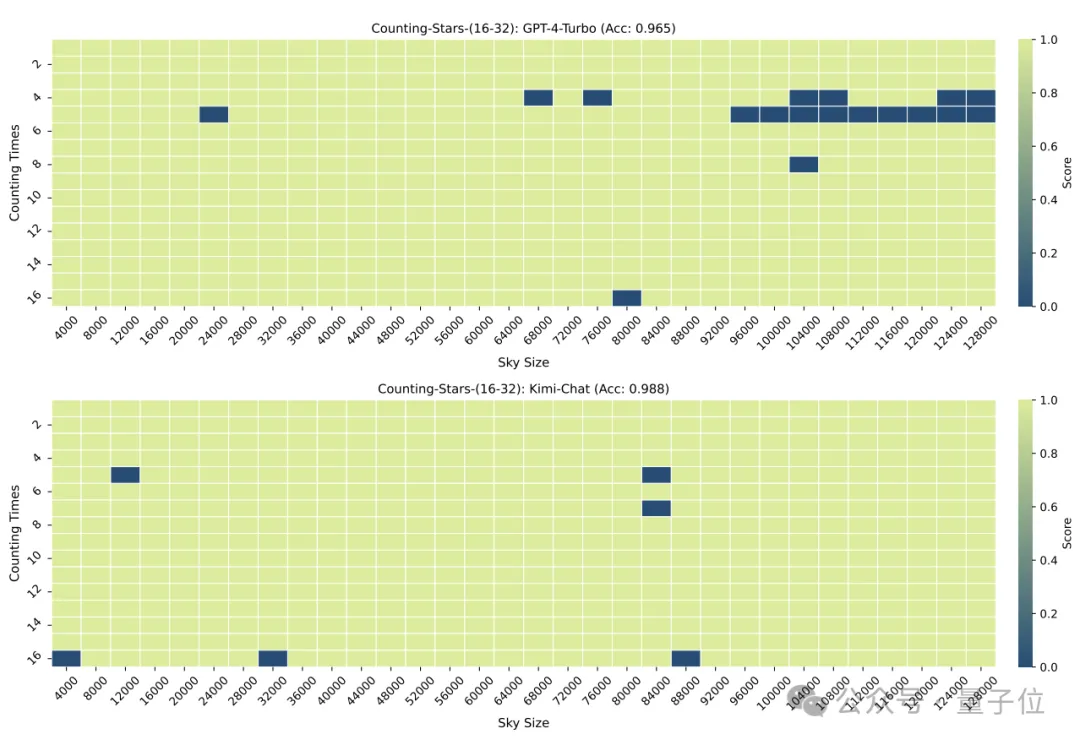
When it is reduced to 16, Kimi’s performance is slightly better than GPT-4.
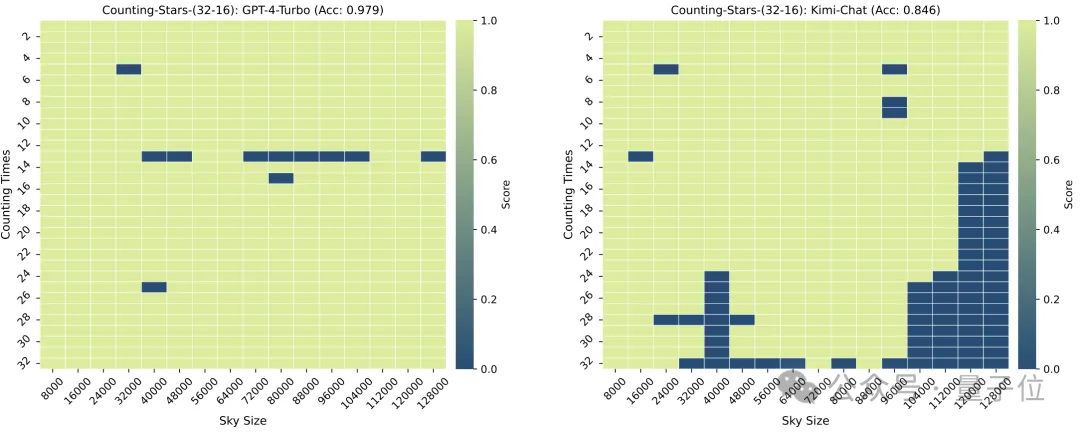
The granularity of the division will also have some impact on the performance of the model. When the "star" also appears 32 times, the granularity changes from 32 to 16, and the score of GPT-4 has increased, while Kimi has improved. decline.
It should be noted that in the above test, the number of "stars" increased sequentially, but the researchers soon discovered that in this case, the large model was very Like "lazy" -
When the model finds that the number of stars is increasing, even if the numbers in the interval are randomly generated, it will cause the sensitivity of the large model to increase.
For example: the model will be more sensitive to the increasing sequence of 3, 9, 10, 24, 1145, 114514 than 24, 10, 3, 1145, 9, 114514
So, the researchers deliberately disrupted the order of the numbers and conducted the test again.

After the disruption, the performance of both GPT-4 and Kimi dropped significantly, but the accuracy was still above 60%, with a difference of 8.6 percentage points.
The accuracy of this method may still need time to be tested, but I have to say that the name is really good.

△Lyrics of the English song Counting Stars
Netizens can’t help but lament that the research on large models is really becoming more and more magical.
#But behind the magic, it also reflects that people do not fully understand the long-context processing capabilities and performance of large models.
Just a few days ago, a number of large model manufacturers announced the launch of models that can handle ultra-long text (although not all are based on context windows) , up to tens of millions , but the actual performance is still unknown.
The emergence of Counting Stars may just help us understand the true performance of these models.
So, which other models do you want to see the test results of?
Paper address: https://arxiv.org/abs/2403.11802
GitHub: https://github.com/nick7nlp/Counting-Stars
The above is the detailed content of 'Looking for a needle in a haystack' out! 'Counting stars' becomes a more accurate method for measuring text length, from Goose Factory. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



