


With just a photo and a piece of audio, you can directly generate a video of the character talking!
Recently, researchers from Google released the multi-modal diffusion model VLOGGER, taking us one step closer to virtual digital humans.

Paper address: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger can collect a single input image, use text or audio driver, and generate a video of human speech, including mouth shapes, expressions, body movements, etc., which are very natural.
Let’s look at a few examples first:




If you feel that the use of other people’s voices in the video is a bit inconsistent, the editor will help you turn off the sound:

It can be seen that the entire generated effect is very elegant and natural.
VLOGGER builds on recent successes in generating diffusion models, including a model that translates humans into 3D motion, and a new diffusion-based architecture for control through time and space , enhance the effect of text-generated images.

VLOGGER can generate high-quality videos of variable length, and these videos can be easily controlled with high-level representations of faces and bodies.

For example, we can make the people in the generated video shut up:

Or close your eyes:

Compared with previous similar models, VLOGGER does not need to be trained on individuals and does not rely on Face detection and cropping, but also body movements, torso and background, constitute a normal human representation that can communicate.
AI voice, AI expression, AI action, AI scene, the value of human beings at the beginning is to provide data, but may it have no value in the future?


On the data side, the researchers collected a new, diverse dataset, MENTOR, than The previous similar data set was an entire order of magnitude larger. The training set included 2,200 hours and 800,000 different individuals, and the test set included 120 hours and 4,000 people with different identities.

The researchers evaluated VLOGGER on three different benchmarks, showing that the model achieves state-of-the-art performance in image quality, identity preservation, and temporal consistency. of optimal.

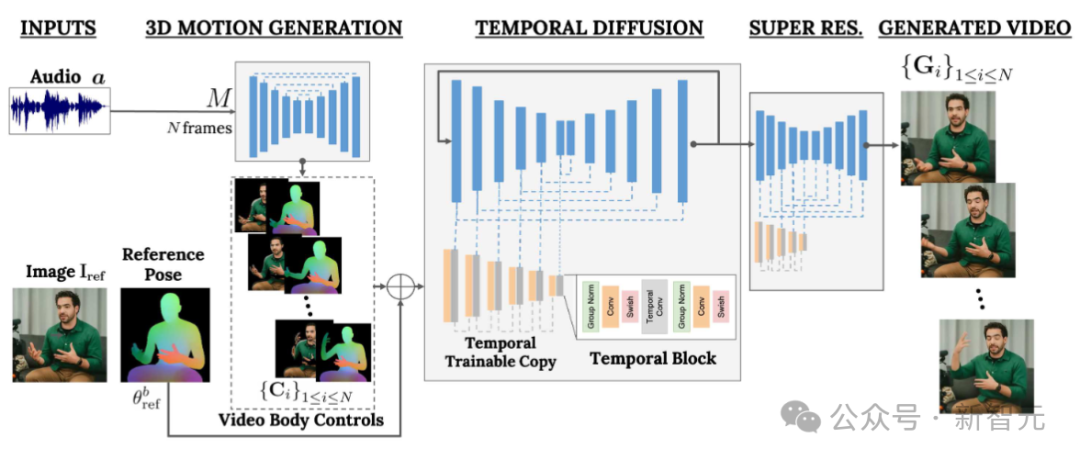
The goal of VLOGGER is to generate a variable-length realistic video depicting the entire process of the target person speaking, Includes head movements and gestures.

As shown above, given a single input image shown in column 1 and a sample audio input, a series of Composite image.
Including generating head movements, gazes, blinks, lip movements, and something that previous models were unable to do, generating upper body and gestures, which is a major advancement in audio-driven synthesis.
VLOGGER adopts a two-stage pipeline based on a random diffusion model to simulate one-to-many mapping from speech to video.
The first network takes audio waveforms as input to generate body motion controls responsible for gaze, facial expressions and gestures over the length of the target video.
The second network is a temporal image-to-image translation model that extends the large image diffusion model to employ predicted body control to generate corresponding frames. To align this process with a specific identity, the network obtains a reference image of the target person.
VLOGGER uses a statistically based 3D body model to regulate the video generation process. Given an input image, the predicted shape parameters encode the geometric properties of the target identity.
First, the network M takes the input speech and generates a series of N frames of 3D facial expressions and body poses.
A dense representation of the moving 3D body is then rendered to act as a 2D control during the video generation stage. These images, along with the input images, serve as input to the temporal diffusion model and super-resolution modules.
The first network of the pipeline is designed to predict motion based on input speech. In addition, the input text is converted into a waveform through a text-to-speech model, and the generated audio is represented as standard Mel-Spectrograms.
The pipeline is based on the Transformer architecture and has four multi-head attention layers in the time dimension. Includes positional encoding of frame number and diffusion step, as well as embedding MLP for input audio and diffusion step.
In each frame, use a causal mask to make the model only focus on the previous frame. The model is trained using variable length videos (such as the TalkingHead-1KH dataset) to generate very long sequences.
The researchers employ statistically based estimated parameters of a 3D human body model to generate intermediate control representations for synthetic videos.
The model takes into account both facial expressions and body movements to generate better expressive and dynamic gestures.
In addition, previous face generation work usually relies on warped images, but this method has been ignored in diffusion-based architectures.
The authors recommend using distorted images to guide the generation process, which facilitates the network’s task and helps maintain the subject identity of the character.
#The next goal is to perform motion processing on the input image of a person , making it follow previously predicted body and facial movements.
Inspired by ControlNet, the researchers froze the initially trained model and used input time controls to make a zero-initialized trainable copy of the encoding layer.
The author interleaves one-dimensional convolutional layers in the time domain. The network is trained by obtaining consecutive N frames and controls, and generates action videos of reference characters based on the input controls.
The model is trained using the MENTOR data set built by the author. Because during the training process, the network will obtain a series of continuous frames and arbitrary reference images, so in theory any video can be Frame specified as reference.
In practice, however, the authors choose to sample references further away from the target clip because closer examples offer less generalization potential.
The network is trained in two stages, first learning a new control layer on a single frame, and then training on the video by adding a temporal component. This allows the use of large batches in the first stage and faster learning of head-replay tasks.
The learning rate adopted by the author is 5e-5, and the image model is trained with a step size of 400k and a batch size of 128 in both stages.
The following figure shows the diverse distribution of target videos generated from an input image. The rightmost column shows the pixel diversity obtained from the 80 generated videos.

The person's head and body move significantly while the background remains fixed (red means higher diversity of pixel colors) , and, despite the diversity, all videos look realistic.

One of the applications of the model is to edit existing video. In this case, VLOGGER takes a video and changes the subject's expression by closing their mouth or eyes, for example.
In practice, the author takes advantage of the flexibility of the diffusion model to repair the parts of the image that should be changed, making the video edit consistent with the original unchanged pixels.
One of the main applications of the model is video translation. In this case, VLOGGER takes an existing video in a specific language and edits the lips and facial areas to align with the new audio (e.g. Spanish).
The above is the detailed content of An AI video can be generated from just one picture! Google's new diffusion model makes characters move. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist How to solve the problem that wlan does not have a valid ip configuration
How to solve the problem that wlan does not have a valid ip configuration telnet command
telnet command What should I do if IE browser prompts a script error?
What should I do if IE browser prompts a script error? What are the differences between c++ and c language
What are the differences between c++ and c language How to integrate idea with Tomcat
How to integrate idea with Tomcat Solution to java report that build path entries are empty
Solution to java report that build path entries are empty The installer cannot create a new system partition solution
The installer cannot create a new system partition solution




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



