On March 11, 011Wang announced the launch of a new vector database "Descartes" based on full navigation graphs, which has won the first place in 6 data set evaluations of the authoritative list ANN-Benchmarks.
Vector database, also known as the information retrieval technology in the AI era, is one of the core technologies of Retrieval-Augmented Generation (RAG). For large model application developers, the vector database is a very important infrastructure, which affects the performance of large models to a certain extent.
In the offline test of the international authoritative evaluation platform ANN-Benchmarks,
Zero One Everything Descartes vector database ranked first among the 6 data set evaluations It has a significant performance improvement compared to the first place in the industry on the previous list, and the performance improvement on some data sets is even more than 2 times.
Zero One Everything said that the Cartesian vector database will be used in AI products that will be officially launched in the near future, and will also be provided to developers in combination with tools in the future.
Vector database becomes AI 2.0 infrastructure
Won the favor of the capital market
With the advent of the AI 2.0 era represented by large models, the amount of multi-modal unstructured data such as pictures, videos, and natural languages has increased sharply, which is different from the traditional methods used to process structured data. database. Vector database is specially used to store, manage, query and retrieve vectorized unstructured data; it is like an external memory disk that can be called by large models at any time to form "long-term memory", also nicknamed large model memory The "hippocampus".
# Large models naturally have four flaws. Vector databases are like tailor-made "special medicine" that can accurately solve every pain point.
-
#Real-time information: Large models take a long time to train, update slowly, and cannot reflect the latest information. There is a "deadline" challenge for their knowledge. The vector database adopts a lightweight update mechanism that can quickly supplement the latest information.
-
Privacy protection: Users’ security and privacy data should not be directly provided to large model training, otherwise there will be a risk of leakage. Vector data cracks privacy by acting as an intermediate carrier for information transmission in the inference stage. Difficulties in protection.
-
Illusion correction: Large models often exhibit inference distortion or hallucination phenomena. Such problems can be effectively corrected and alleviated through the rich knowledge reference provided by the vector database.
-
Inference efficiency: The cost of inference for large models is high. The vector database can be used as a caching mechanism to avoid the need to re-execute complex inference calculations for each query request, greatly saving computing resources.
The technological changes and platform changes initiated by AI 2.0 have further strengthened the role of vector databases. Related products from major manufacturers such as Google, Microsoft, and Meta have come out one after another, and startups such as Zilliz, Pinecone, Weaviate, and Qdrant have also emerged. In 2023, OpenAI's vector database partner Pinecone completed a Series B financing of US$138 million, and domestic start-up Fabarta ArcNeural also completed a Pre-A round of financing of hundreds of millions of yuan.
Challenging the authoritative list
Winning the first place in six evaluations
ANN-Benchmarks is the most authoritative vector database performance testing tool in the industry. It can show the performance of different algorithms under different real data sets.
The following 6 evaluation data sets cover glove-25-angular, glove-100-angular, sift-128-euclidean, nytimes-256-angular, fashion-mnist -784-euclidean, gist-960-euclidean six major data sets, the abscissa represents recall, the ordinate represents QPS (number of requests processed per second), the closer the curve position is to the upper right corner, the better the algorithm performance, zero ten thousand The Cartesian vector database ranks highest in all 6 dataset evaluations.
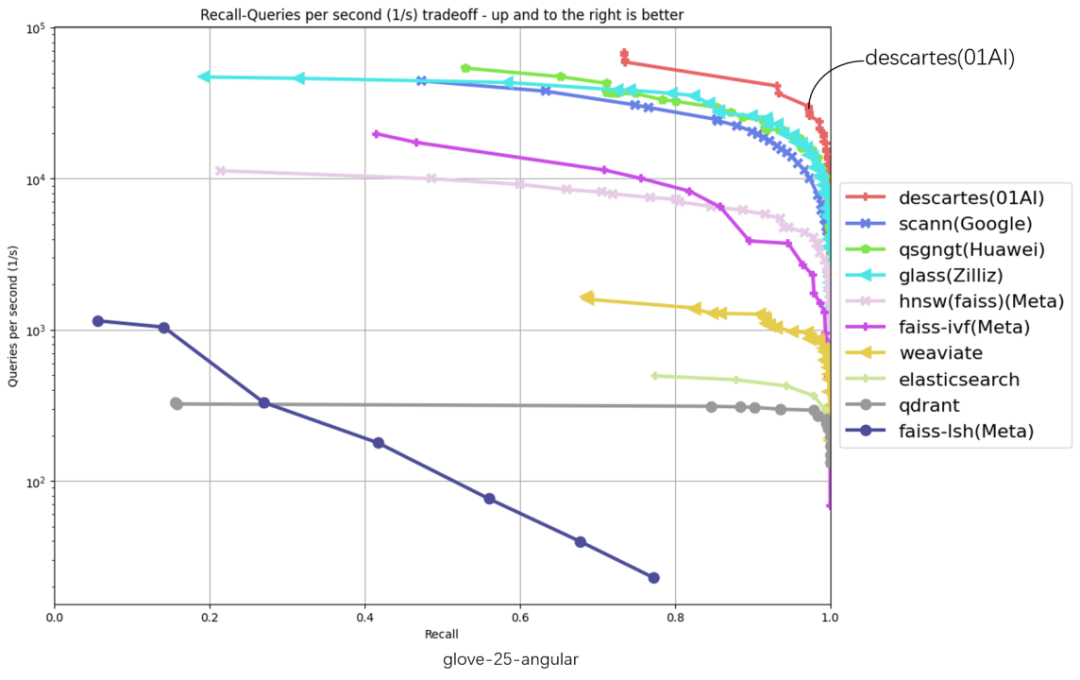
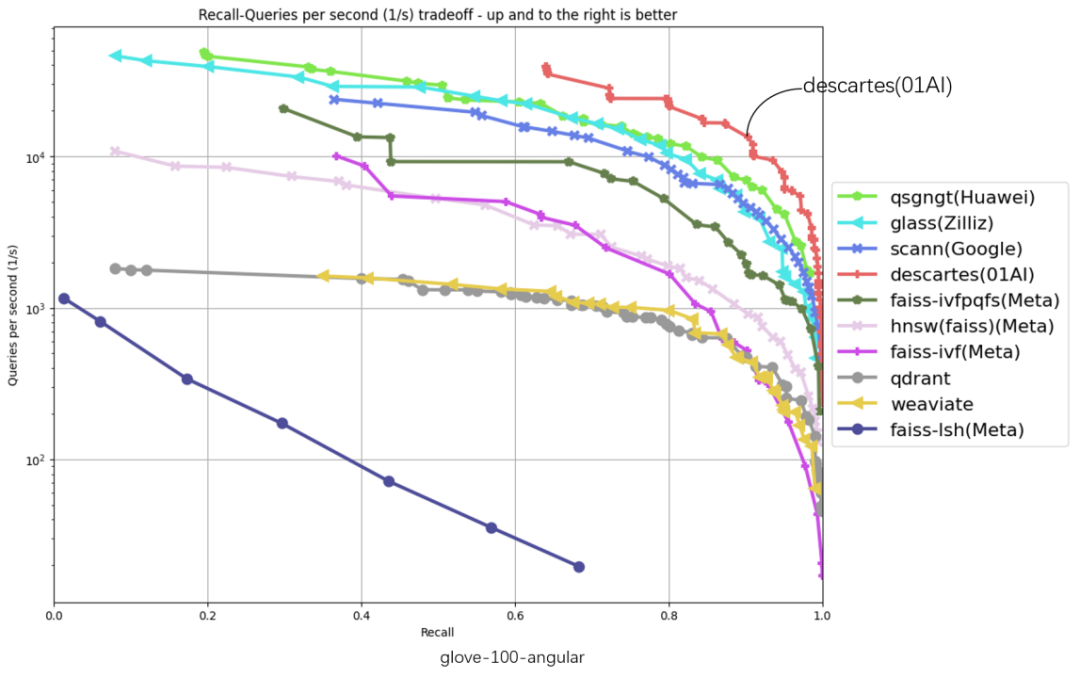
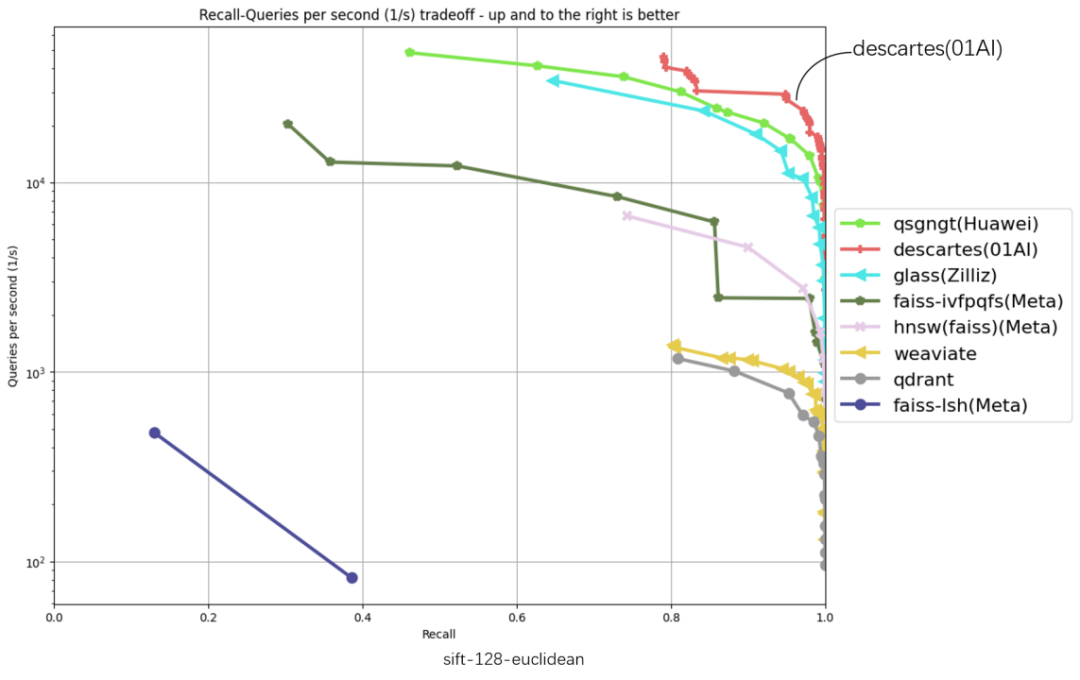
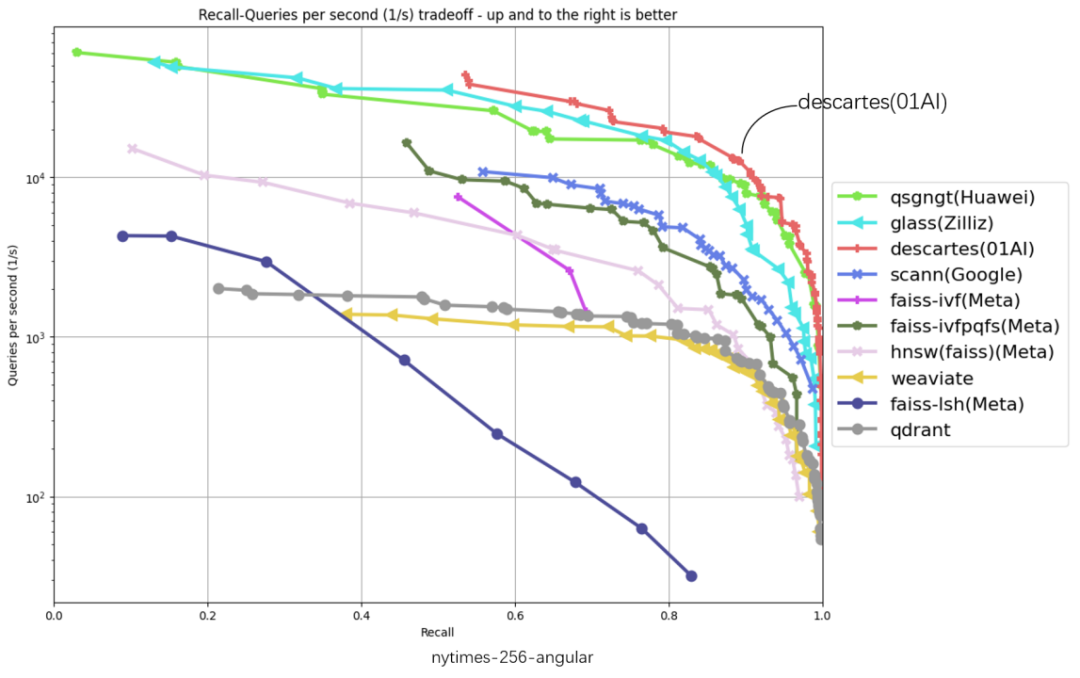
#
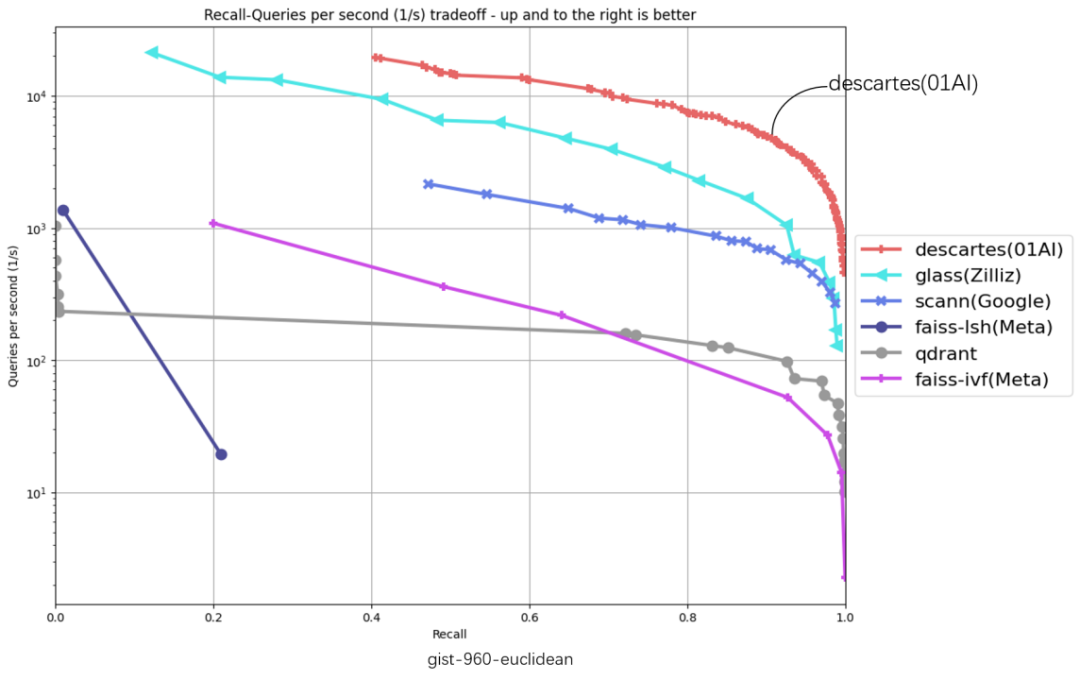
"Throughput QPS" is an important indicator to measure the query processing capabilities of an information retrieval system (such as a search engine or database). Based on the TOP1 of the original list, the Zero-One Thousand Things Cartesian Vector Database has achieved significant performance improvements. The performance improvement on some data sets is more than 2 times. In the gist-960-euclidean data set dimension, it is significantly ahead of the original TOP1 of the list. 286%.
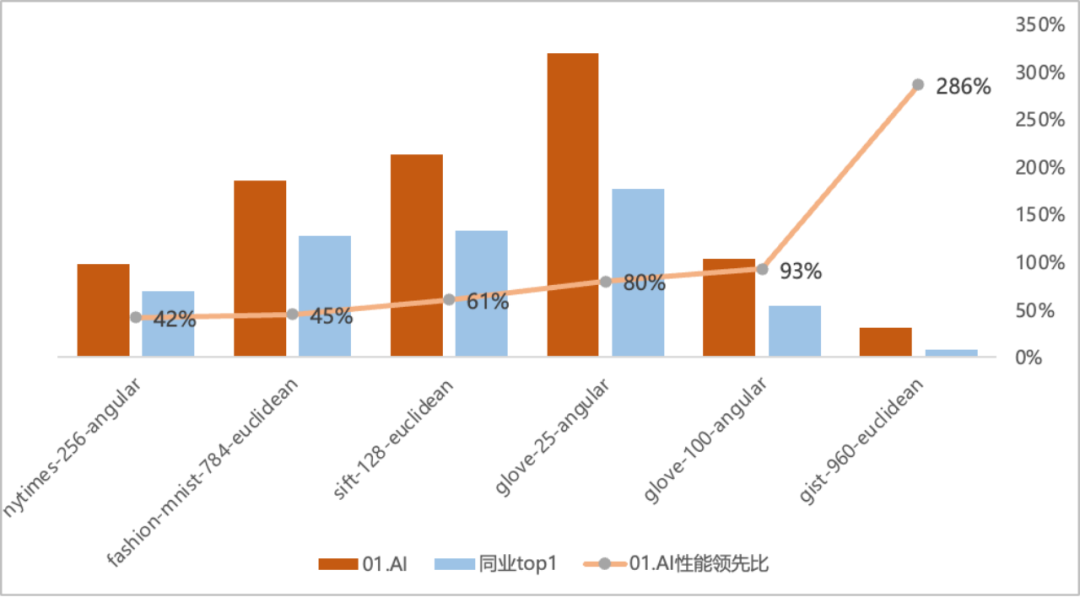
#: Poly Herigid Cartesial Pign Database and the original list TOP1 QPS Performance Comparison
##Technical Reveal
What is curious is how Descartes achieves the above excellent performance?
As we all know, RAG is a technology that combines retrieval and generation. It enhances the generation capabilities of language models by retrieving queried information from massive data. Similar to traditional retrieval methods, in essence, RAG vector retrieval mainly solves two major problems:
1. Reduce the candidate set for retrieval inspection by establishing a certain index structure ;
2. Reduce the complexity of single vector calculation.
Zero One Thousand Cartesian Vector Database has significant comparative advantages over the industry in processing complex queries, improving retrieval efficiency, and optimizing data storage. In response to the first question, the Zero One World team has two major killers:
-
Leading full navigation map technology.The current industry status quo is mainly through hashing, KD-Tree, VP-Tree and other methods. The navigation effect is not accurate enough and the cropping strength is not enough. The global multi-layer thumbnail navigation technology developed by Zero One Wish, and the coordinate system navigation on the map, It can not only ensure accuracy, but also clip a large number of irrelevant vectors.
-
The first adaptive neighbor selection strategy to fill the gap in the industry.The self-developed adaptive neighbor selection strategy of 01Wuxing breaks through the limitations of relying only on real topk or fixed edge selection strategies in the past. The new strategy allows each node to dynamically select the best one based on the distribution characteristics of itself and its neighbors. Neighbor edges converge closer to the target vector faster, thereby improving RAG vector retrieval performance by 15%-30%.
In response to the second question, Zero One Wish adopts a
two-level quantization schemeto enhance RAG. Zero One Thousand uses two-level quantization to reduce computational complexity. At the same time, columnar storage fully utilizes the concurrency capabilities of SIMD to further leverage hardware capabilities. Compared with traditional PQ table lookup, the performance is greatly improved to 2-3 times.
In addition, Zero-One Everything also has full-stack vector technology solutions such as index structure optimization and connectivity guarantee to improve the performance of Cartesian vector databases.
Full stack vector technology: higher accuracy and stronger performance
Through the above With the support of full-stack vector technology, Zero-One Cartesian Vector Database not only topped the authoritative list of ANN-Benchmarks in 6 evaluations. It also has core advantages such as higher accuracy and stronger performance in practical application scenarios.
#Zero One Everything Cartesian Vector Database currently focuses on high-performance vector databases. High-performance vector databases usually refer to vector data sets with scales of tens of millions or less (such as 20 million 128-dimensional floating-point vectors). Generally speaking, high-performance vector databases can easily handle 80 to 90 percent of daily scenarios. For example, it helps corporate customers build private domain knowledge bases and intelligent customer service systems; in the field of autonomous driving, the use of high-performance vector databases can accelerate autonomous driving model training, etc.
Zero One All High Performance Vector Database has the following advantages:
-
Ultra-high precision:Based on multi-layer thumbnails and coordinate systems, inter-layer navigation and on-map orientation navigation are realized, as well as graph connectivity guarantee, achieving an accuracy greater than 99%. Under the same performance, the accuracy is significantly ahead of the industry level.
-
Super high performance:Efficient edge selection and cropping technology, tens of millions of database ms response.
Take the e-commerce recommendation scenario as an example. The number of products on the shelves may be tens of millions, and each product can be expressed by a vector. Even if the number of vectors in the library is not very large, if the e-commerce user base is very large and the number of user requests per second at peak times is very large, it may reach hundreds of thousands or even millions of QPS. The use of high-performance vector databases can effectively improve the recommendation effect of search and advertising services in e-commerce scenarios, making everyone unable to help but keep buying.
#Zero Yiwu said that the Cartesian vector database is the team’s initial attempt based on RAG and will be effectively used in AI productivity products released in the near future. In the future, after each major model is optimized to a certain extent, the capabilities of the vector database may determine the ceiling of each major model. Zero One Wish will continue to focus on R&D and sharing in the future to bring better technology and experience to users.
The above is the detailed content of 01Wang's self-developed full navigation map vector database swept 6 first places on the authoritative list. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



