


Large-scale models can only remember and understand limited context, which has become a major limitation in their practical applications. For example, conversational AI systems are often unable to persistently remember the content of the previous day's conversations, which results in agents built using large models exhibiting inconsistent behavior and memory.
To allow large models to better handle longer contexts, the researchers proposed a new method called InfLLM. This method, jointly proposed by researchers from Tsinghua University, MIT, and Renmin University, enables large language models (LLMs) to handle very long texts without additional training. InfLLM utilizes a small amount of computing resources and graphics memory overhead to achieve efficient processing of very long texts.

Paper address: https://arxiv.org/abs/2402.04617
Code warehouse: https://github.com/thunlp/InfLLM
The experimental results show that InfLLM can effectively expand the context processing window of Mistral and LLaMA, and perform the task of finding a needle in a haystack of 1024K contexts. Achieve 100% recall.
Large-scale pre-trained language models (LLMs) have made breakthrough progress in many tasks in recent years and have become the basic model for many applications.
These practical applications also pose higher challenges to the ability of LLMs to process long sequences. For example, an LLM-driven agent needs to continuously process information received from the external environment, which requires it to have stronger memory capabilities. At the same time, conversational AI needs to better remember the content of conversations with users in order to generate more personalized responses.
However, current large-scale models are usually only pre-trained on sequences containing thousands of Tokens, which leads to two major challenges when applying them to very long texts:
1. Out-of-distribution length:Directly applying LLMs to longer length texts often requires LLMs to process position encodings that exceed the training range. , thus causing Out-of-Distribution problem and unable to be generalized;
2. Attention interference:Excessively long context will make The model attention is excessively divided into irrelevant information, making it unable to effectively model long-range semantic dependencies in context.
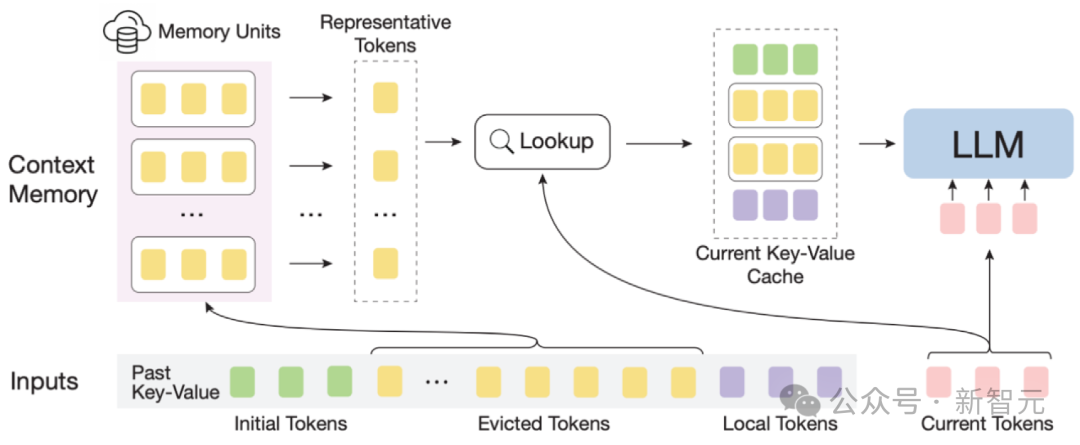
InfLLM diagram
In order to efficiently implement large models Length generalization ability, the authors propose a training-free memory enhancement method, InfLLM, for streaming processing of very long sequences.
InfLLM aims to stimulate the intrinsic ability of LLMs to capture long-distance semantic dependencies in ultra-long contexts with limited computational cost, thereby enabling efficient long text understanding.
Overall framework: Considering the sparsity of long text attention, processing each Token usually requires only a small part of its context.
The author built an external memory module to store ultra-long context information; using a sliding window mechanism, at each calculation step, there are only Tokens (Local Tokens) that are close to the current Token. A small amount of relevant information in the external memory module is involved in the calculation of the attention layer, while other irrelevant noise is ignored.
Therefore, LLMs can use a limited window size to understand the entire long sequence and avoid introducing noise.
However, the massive context in ultra-long sequences brings significant challenges to the effective location of relevant information in the memory module and the efficiency of memory search.
In order to deal with these challenges, each memory unit in the context memory module consists of a semantic block, and a semantic block consists of several consecutive Tokens.
Specifically, (1) In order to effectively locate relevant memory units, the coherent semantics of each semantic block can more effectively meet the needs of related information queries than fragmented Tokens.
In addition, the author selects the semantically most important Token from each semantic block, that is, the Token that receives the highest attention score, as the representation of the semantic block. This method helps To avoid the interference of unimportant Tokens in the correlation calculation.
(2) For efficient memory search, the memory unit at the semantic block level avoids token-by-token and attention-by-attention correlation calculations, reducing computational complexity.
In addition, semantic block-level memory units ensure continuous memory access and reduce memory loading costs.
Thanks to this, the author designed an efficient offloading mechanism (Offloading) for the context memory module.
Considering that most memory units are not used frequently, InfLLM unloads all memory units to CPU memory and dynamically retains frequently used memory units in GPU memory, thus Significantly reduced video memory usage.
InfLLMcan be summarizedas:
1. Based on the sliding window, a remote context memory module is added.
2. Divide the historical context into semantic blocks to form memory units in the context memory module. Each memory unit determines a representative token through its attention score in the previous attention calculation, as the representation of the memory unit. Thereby avoiding noise interference in the context and reducing memory query complexity
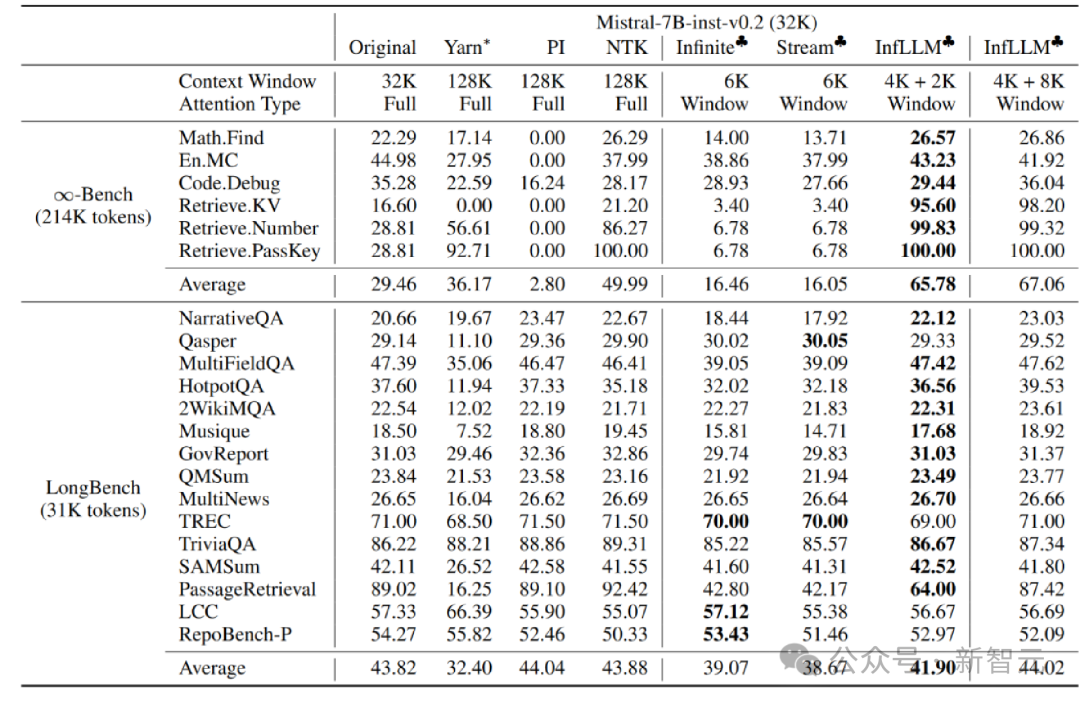
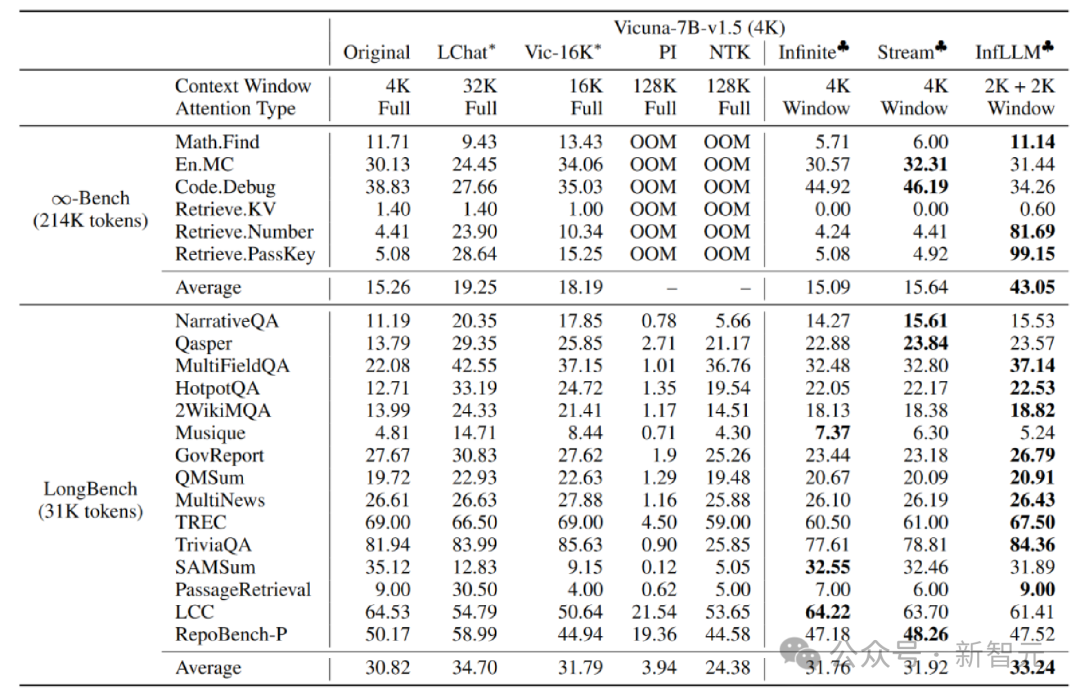
The author is working on Mistral-7b-Inst-v0.2 (32K) and Vicuna InfLLM is applied on the -7b-v1.5 (4K) model, using local window sizes of 4K and 2K respectively.
Compared with the original model, positional coding interpolation, Infinite-LM and StreamingLLM, significant performance improvements have been achieved on long text data Infinite-Bench and Longbench.
##Super long text experiment
In addition, the author continues to explore the generalization ability of InfLLM on longer texts, and can still maintain a 100% recall rate in the "needle in a haystack" task of 1024K length.
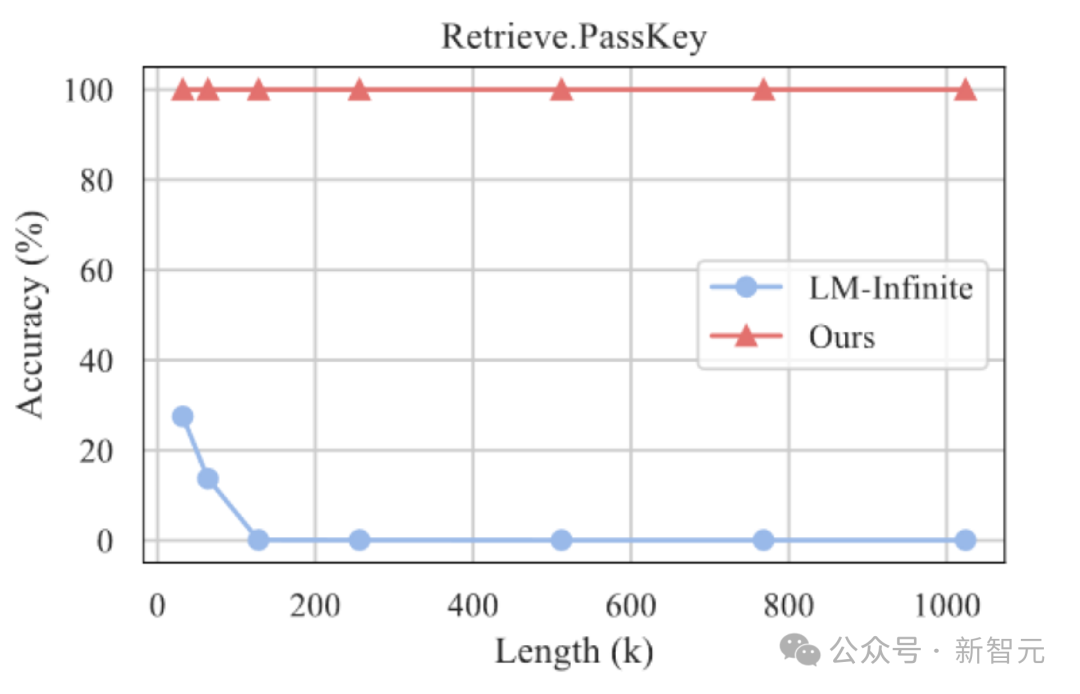
Needle in a haystack experimental results
SummaryIn this article, the team InfLLM is proposed, which can realize the extension of LLM for ultra-long text processing without training and can capture long-distance semantic information.
Based on the sliding window, InfLLM adds a memory module containing long-distance context information, and uses cache and offload mechanisms to implement streaming long text reasoning with a small amount of calculation and memory consumption. .
The above is the detailed content of Tsinghua NLP Group released InfLLM: No additional training required, '1024K ultra-long context' 100% recall!. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



