


В ответ на продолжающийся рост спроса на инструменты 3D-творчества в Метавселенной в последнее время наблюдается большой интерес к созданию трехмерного контента (3D AIGC). В то же время создание 3D-контента также значительно продвинулось по качеству и скорости.
Хотя текущие генеративные модели с прямой связью могут генерировать 3D-объекты за секунды, их разрешение ограничено интенсивными вычислениями, необходимыми во время обучения, что приводит к низкому качеству генерации Контента. Возникает вопрос: можно ли создать высококачественный 3D-объект с высоким разрешением всего за 5 секунд?

В этой статье исследователи из Пекинского университета, Наньянского технологического университета S-Lab и Шанхайской лаборатории искусственного интеллекта предложили
новую структуру LGM , а именно Большая Гауссова Модель, позволяет создавать трехмерные объекты высокого разрешения и высокого качества из однопросмотровых изображений или ввода текста всего за 5 секунд.
В настоящее время код и веса модели находятся в открытом исходном коде. Исследователи также предоставляют онлайн-демонстрацию, которую каждый может попробовать. 
Для достижения такой цели исследователи сталкиваются со следующими двумя проблемами:
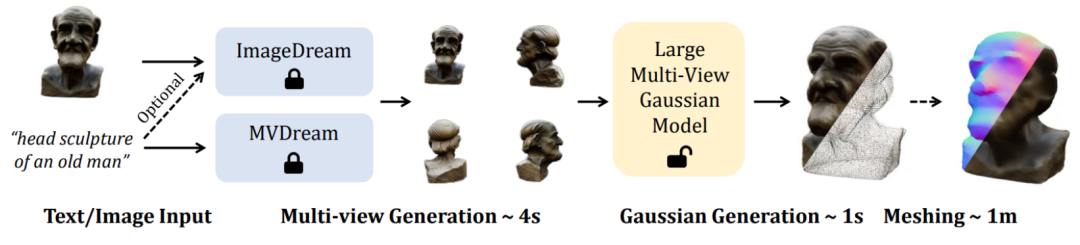
При ограниченном объеме вычислений Эффективное трехмерное представление : Существующие работы по созданию 3D-изображений используют NeRF на основе трех плоскостей в качестве конвейера трехмерного представления и рендеринга, что значительно ограничивает плотное моделирование сцены и технологию объемного рендеринга с трассировкой лучей. Его разрешение обучения ( 128×128) делает текстуру окончательно сгенерированного контента размытой и некачественной.
3D-магистральная сеть генерации с высоким разрешением
#: Существующая работа по 3D-генерации использует плотные трансформаторы в качестве магистральной сети для обеспечения достаточной плотности Количество параметры используются для моделирования универсальных объектов, но это в определенной степени жертвует разрешением обучения, что приводит к низкому качеству конечного трехмерного объекта.
С этой целью в данной статье предлагается новый метод синтеза трехмерных представлений высокого разрешения из четырехракурсных изображений, а затем Перспективных изображений или одно- преобразование изображения в многоракурсные модели изображений для поддержки высококачественных задач преобразования текста в 3D и изображения в 3D.
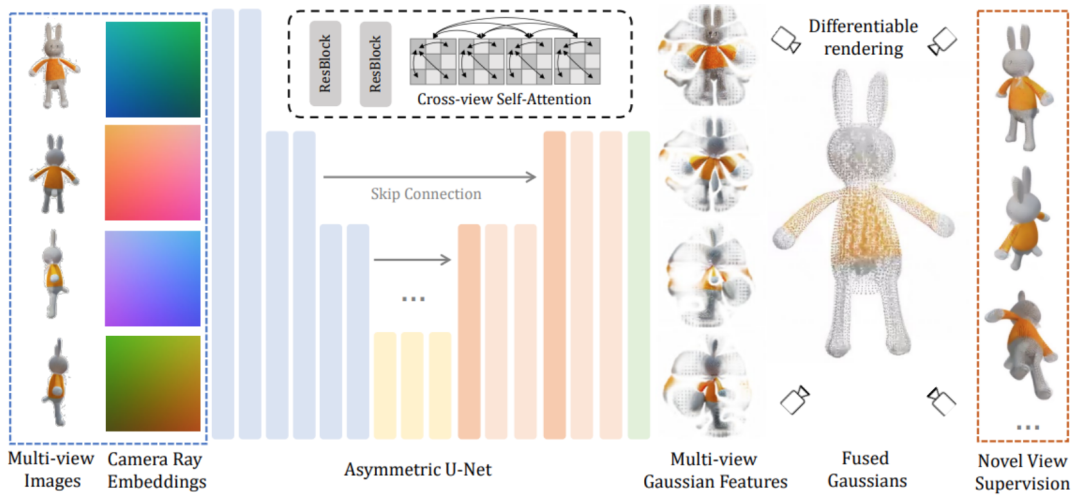
##########################Технически ###LGM основной модуль представляет собой большую многовидовую гауссову модель###. Вдохновленный гауссовским распылением, этот метод использует эффективную и легкую асимметричную сеть U-Net в качестве магистральной сети для прямого прогнозирования гауссовских примитивов высокого разрешения на основе четырехракурсных изображений и, наконец, рендеринга изображений под любым углом обзора. ############ В частности, магистральная сеть U-Net принимает изображения с четырех точек зрения и соответствующие координаты Плакера и выводит фиксированное количество гауссовских функций с нескольких точек зрения. Этот набор гауссовских функций напрямую объединяется с конечным гауссовским элементом, и изображения под разными углами обзора получаются посредством дифференцируемого рендеринга. ############В этом процессе используется механизм перекрестного просмотра для достижения корреляционного моделирования между различными представлениями на картах объектов с низким разрешением, сохраняя при этом меньшие вычислительные затраты. #####################Стоит отметить, что эффективно обучить такую модель в высоком разрешении непросто. Чтобы добиться надежного обучения, исследователи по-прежнему сталкиваются со следующими двумя проблемами. ######First, the three-dimensional consistent multi-view images rendered in the objaverse data set are used in the training phase, while in the inference phase, existing models are directly used to synthesize multi-perspective images from text or images. Since multi-view pictures synthesized based on the model always have the problem of multi-view inconsistency, in order to bridge the gap in this domain, this article proposes a data enhancement strategy based on grid distortion: in the image space, images from three views are Apply random distortion to simulate multi-view inconsistencies.
The second reason is that the multi-view images generated in the inference stage do not strictly guarantee the consistency of the three-dimensional geometry of the camera perspective, so this article also randomly perturbs the camera poses from the three perspectives To simulate this phenomenon, make the model more robust in the inference stage.
Finally, the generated Gaussian primitives are rendered into corresponding images through differentiable rendering, and learned directly end-to-end on the two-dimensional images through supervised learning.
After training is completed, LGM can achieve high-quality Text-to-3D and Image-to-3D through the existing image-to-multi-view or text-to-multi-view diffusion model. Task.

Given the same input text or image, this method can generate a variety of high-quality 3D models.

In order to further support downstream graphics tasks, the researchers also proposed an efficient method to convert the generated Gaussian representation into a smooth and banded representation. Texture Mesh:
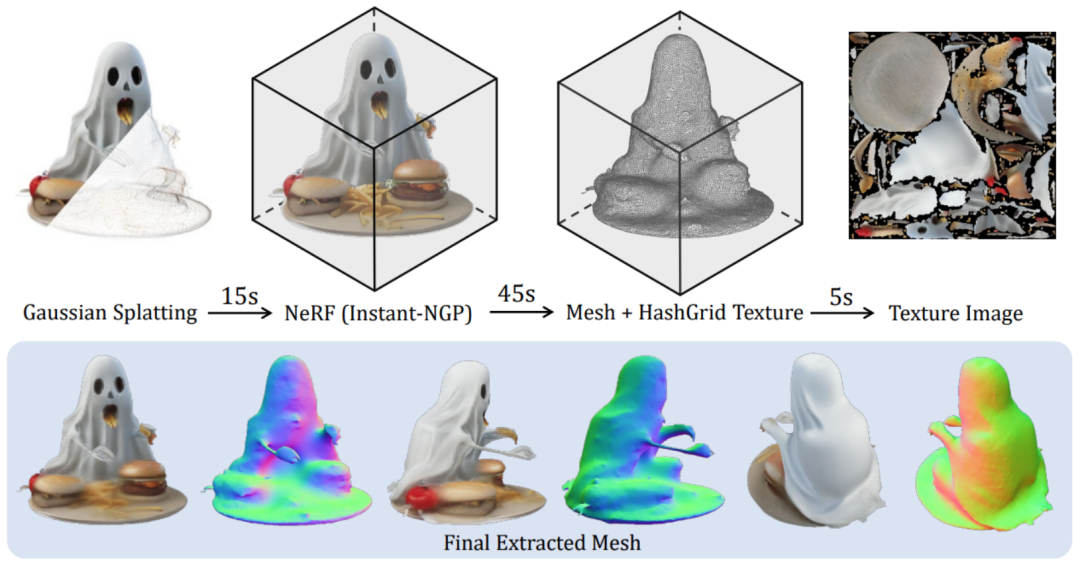
Please refer to the original paper for more details.
The above is the detailed content of Large multi-view Gaussian model LGM: produces high-quality 3D objects in 5 seconds, available for trial play. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



