

 Technology peripherals
AI
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Technology peripherals
AI
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving

Original title: SIMPL: A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving
Paper link: https://arxiv.org/pdf/2402.02519.pdf
Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL
Author affiliation: Hong Kong University of Science and Technology DJI

Thesis idea:
This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Unlike traditional agent-centric methods (which have high accuracy but require repeated computations) and scene-centric methods (where accuracy and generality suffer), SIMPL can provide a comprehensive solution for all relevant traffic. Participants provide real-time, accurate movement predictions. To improve accuracy and inference speed, this paper proposes a compact and efficient global feature fusion module that performs directed message passing in a symmetric manner, enabling the network to predict the future motion of all road users in a single feedforward pass , and reduce the accuracy loss caused by viewpoint movement. Furthermore, this paper investigates the use of Bernstein basis polynomials in trajectory decoding for continuous trajectory parameterization, allowing the evaluation of states and their higher-order derivatives at any desired time point, which is valuable for downstream planning tasks. As a strong baseline, SIMPL shows highly competitive performance on the Argoverse 1 and 2 motion prediction benchmarks compared to other state-of-the-art methods. Furthermore, its lightweight design and low inference latency make SIMPL highly scalable and promising for real-world airborne deployments.
Network Design:
Predicting the movement of surrounding traffic participants is critical for autonomous vehicles, especially in downstream decision-making and planning modules. Accurate prediction of intentions and trajectories will improve safety and ride comfort.
For learning-based motion prediction, one of the most important topics is context representation. Early methods usually represented the surrounding scene as a multi-channel bird's-eye view image [1]–[4]. In contrast, recent research increasingly adopts vectorized scene representation [5]-[13], in which locations and geometries are annotated using point sets or polylines with geographical coordinates, thereby improving fidelity and expand the receptive field. However, for both rasterized and vectorized representations, there is a key question: how should we choose the appropriate reference frame for all these elements? A straightforward approach is to describe all instances within a shared coordinate system (centered on the scene), such as one centered on an autonomous vehicle, and use the coordinates directly as input features. This enables us to make predictions for multiple target agents in a single feedforward pass [8, 14]. However, using global coordinates as input, predictions are typically made for multiple target agents in a single feedforward pass [8, 14]. However, using global coordinates as input (which often vary over a wide range) will greatly exacerbate the inherent complexity of the task, resulting in degraded network performance and limited adaptability to new scenarios. To improve accuracy and robustness, a common solution is to normalize the scene context according to the current state of the target agent [5, 7, 10]-[13] (agent-centric). This means that the normalization process and feature encoding must be performed repeatedly for each target agent, leading to better performance at the expense of redundant computations. Therefore, it is necessary to explore a method that can effectively encode the features of multiple objects while maintaining robustness to perspective changes.
For downstream modules of motion prediction, such as decision-making and motion planning, not only future position needs to be considered, but also heading, speed and other high-order derivatives need to be considered. For example, the predicted headings of surrounding vehicles play a key role in shaping future space-time occupancy, which is a key factor in ensuring safe and robust motion planning [15, 16]. Furthermore, predicting high-order quantities independently without adhering to physical constraints may lead to inconsistent prediction results [17, 18]. For example, although the velocity is zero, it may produce a positional displacement that confuses the planning module.
This article introduces a method called SIMPL (Simple and Efficient Motion Prediction Baseline) to solve the key issue of multi-agent trajectory prediction in autonomous driving systems. The method first adopts an instance-centric scene representation and then introduces symmetric fusion Transformer (SFT) technology, which is able to effectively predict the trajectories of all agents in a single feed-forward pass while maintaining accuracy and robustness to perspective invariance. sex. Compared with other methods based on symmetric context fusion, SFT is simpler, more lightweight and easier to implement, making it suitable for deployment in vehicle environments.
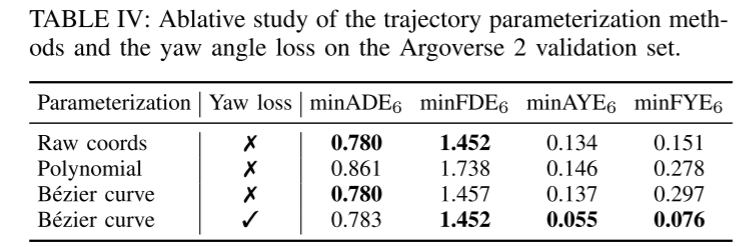
Secondly, this paper introduces a novel parameterization method for predicted trajectories based on Bernstein basis polynomial (also known as Bezier curve). This continuous representation ensures smoothness and enables easy evaluation of the precise state and its higher-order derivatives at any given point in time. The empirical study of this paper shows that learning to predict the control points of Bezier curves is more efficient and numerically stable than estimating the coefficients of monomial basis polynomials.
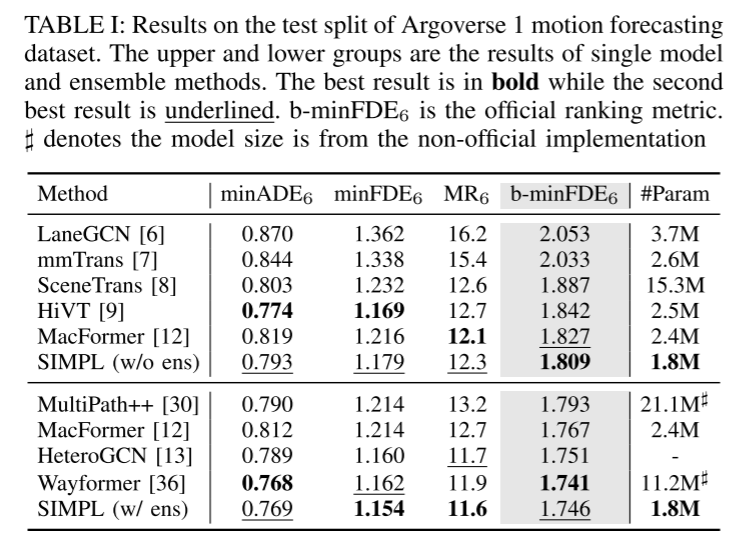
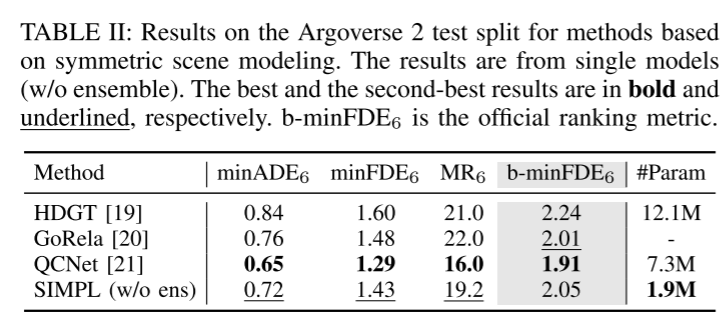
Finally, the proposed components are well integrated into a simple and efficient model. This paper evaluates the proposed method on two large-scale motion prediction datasets [22, 23], and the experimental results show that despite its simplified design, SIMPL is still highly competitive with other state-of-the-art methods. More importantly, SIMPL enables efficient multi-agent trajectory prediction with fewer learnable parameters and lower inference latency without sacrificing quantization performance, which is promising for real-world airborne deployment. This paper also highlights that, as a strong baseline, SIMPL is highly scalable. The simple architecture facilitates direct integration with the latest advances in motion prediction, providing opportunities to further improve overall performance.
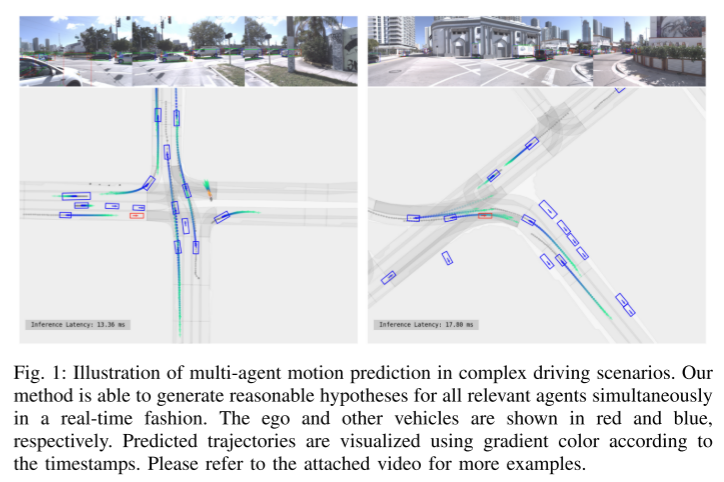
Figure 1: Illustration of multi-agent motion prediction in complex driving scenarios. Our approach is able to generate reasonable hypotheses for all relevant agents simultaneously in real time. Your own vehicle and other vehicles are shown in red and blue respectively. Use gradient colors to visualize predicted trajectories based on timestamps. Please refer to the attached video for more examples.
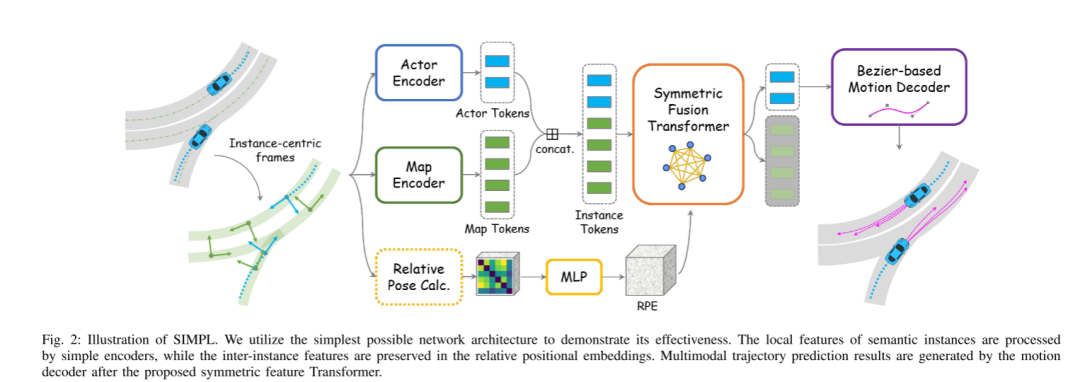
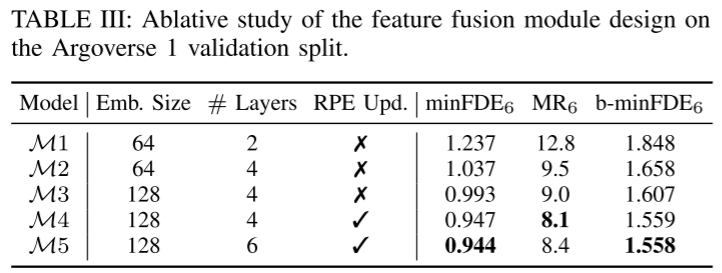
Figure 2: SIMPL schematic. This article uses the simplest possible network architecture to demonstrate its effectiveness. Local features of semantic instances are processed by a simple encoder, while inter-instance features are preserved in relative position embeddings. Multimodal trajectory prediction results are generated by a motion decoder after the proposed symmetric feature Transformer.
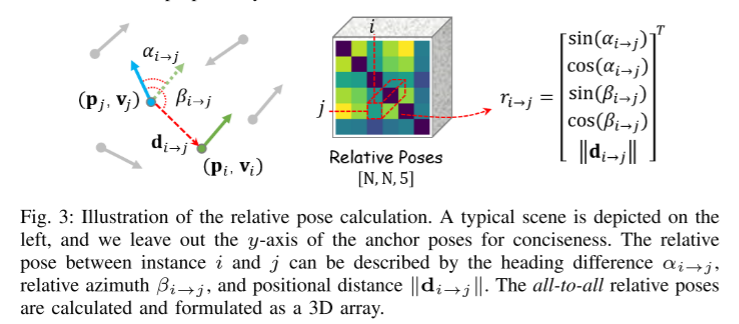
Figure 3: Schematic diagram of relative pose calculation.
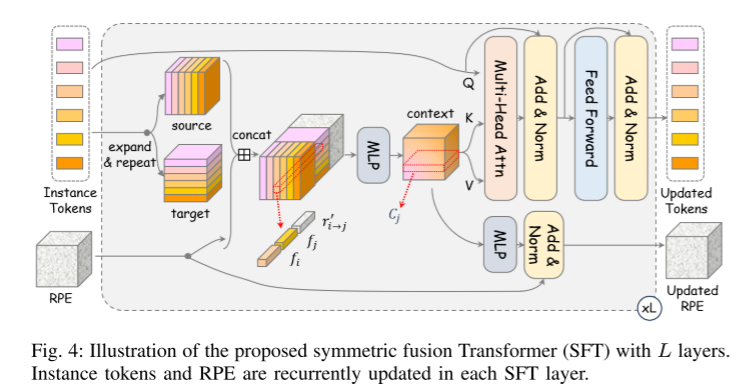
Figure 4: Illustration of the proposed L-layer symmetric fusion Transformer (SFT). Instance tokens and relative position embeddings (RPE) are updated cyclically in each SFT layer.
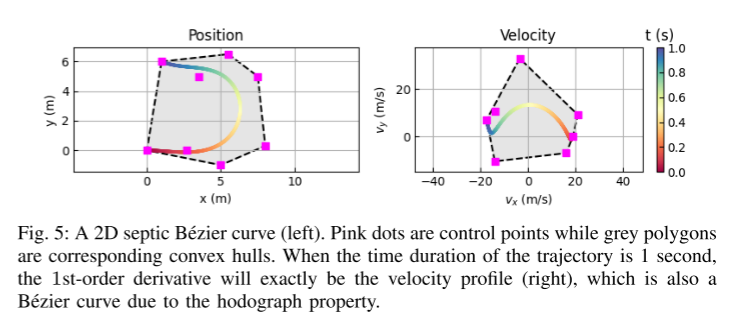
Figure 5: 2D septic Bezier curve (left).
Experimental results:
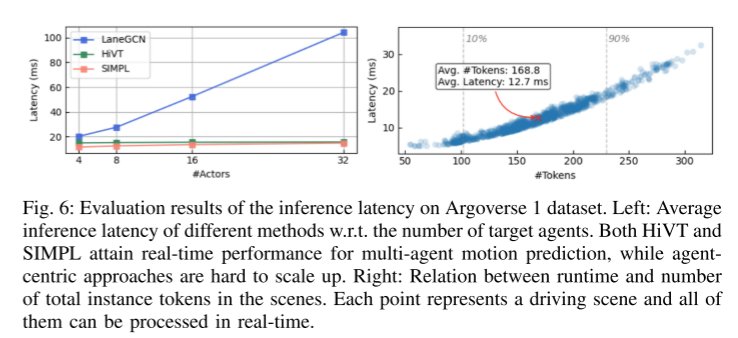
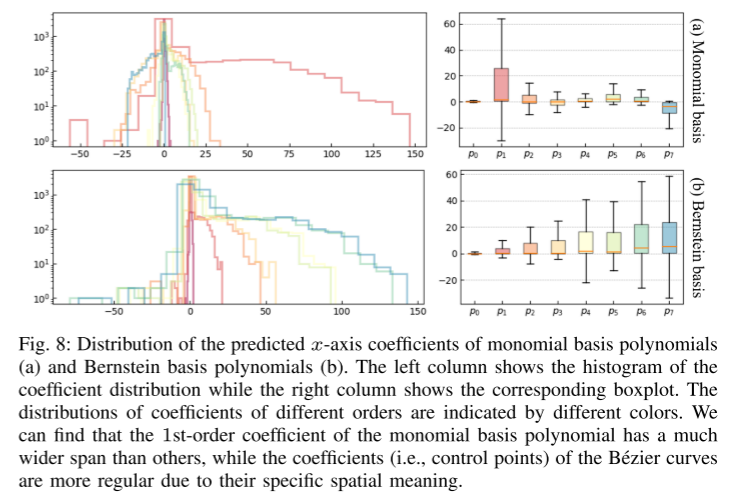
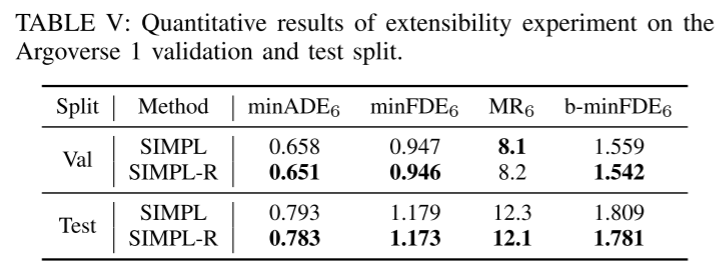
##Summarize:
This paper proposes a simple and efficient multi-agent motion prediction baseline for autonomous driving. Utilizing the proposed symmetric fusion Transformer, the proposed method achieves efficient global feature fusion and maintains robustness against viewpoint movement. Continuous trajectory parameterization based on Bernstein basis polynomials provides higher compatibility with downstream modules. Experimental results on large-scale public datasets show that SIMPL has advantages in model size and inference speed while achieving the same level of accuracy as other state-of-the-art methods.Citation:
Zhang L, Li P, Liu S, et al. SIMPL: A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving[J] . arXiv preprint arXiv:2402.02519, 2024.The above is the detailed content of SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Do not change the meaning of the original content, fine-tune the content, rewrite the content, and do not continue. "Quantile regression meets this need, providing prediction intervals with quantified chances. It is a statistical technique used to model the relationship between a predictor variable and a response variable, especially when the conditional distribution of the response variable is of interest When. Unlike traditional regression methods, quantile regression focuses on estimating the conditional magnitude of the response variable rather than the conditional mean. "Figure (A): Quantile regression Quantile regression is an estimate. A modeling method for the linear relationship between a set of regressors X and the quantiles of the explained variables Y. The existing regression model is actually a method to study the relationship between the explained variable and the explanatory variable. They focus on the relationship between explanatory variables and explained variables
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
