


On January 24, Shanghai Yanxinshuzhi Artificial Intelligence Technology Co., Ltd. launched a large general natural language model without Attention mechanism-Yan model. According to the Yancore Digital Intelligence press conference, the Yan model uses a new self-developed "Yan architecture" to replace the Transformer architecture. Compared with the Transformer, the Yan architecture has a memory capacity increased by 3 times and a speed increased by 7 times while achieving inference throughput. 5 times improvement.  Liu Fanping, CEO of Yancore Digital Intelligence, believes that Transformer, which is famous for its large scale, has high computing power and high cost in practical applications, which has deterred many small and medium-sized enterprises. The complexity of its internal architecture makes the decision-making process difficult to explain; the difficulty in processing long sequences and the problem of uncontrollable hallucinations also limit the wide application of large models in certain key fields and special scenarios. With the popularization of cloud computing and edge computing, the industry's demand for large-scale AI models with high performance and low energy consumption is growing.
Liu Fanping, CEO of Yancore Digital Intelligence, believes that Transformer, which is famous for its large scale, has high computing power and high cost in practical applications, which has deterred many small and medium-sized enterprises. The complexity of its internal architecture makes the decision-making process difficult to explain; the difficulty in processing long sequences and the problem of uncontrollable hallucinations also limit the wide application of large models in certain key fields and special scenarios. With the popularization of cloud computing and edge computing, the industry's demand for large-scale AI models with high performance and low energy consumption is growing.
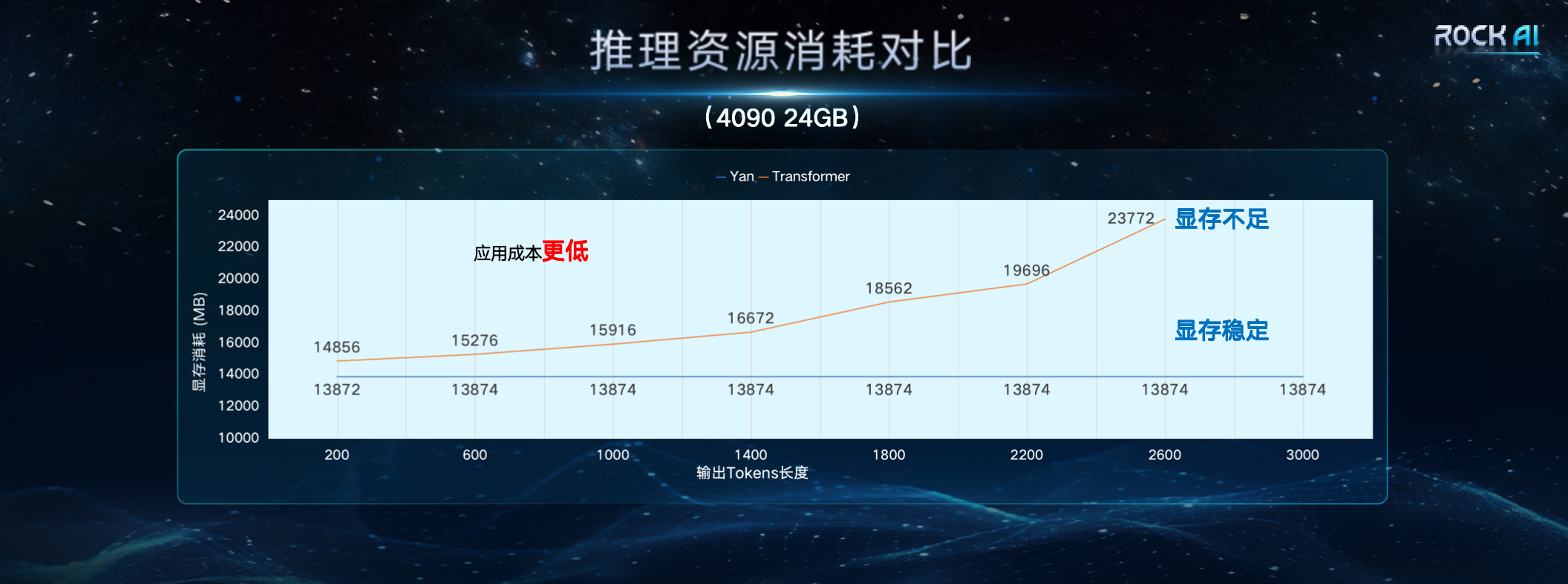
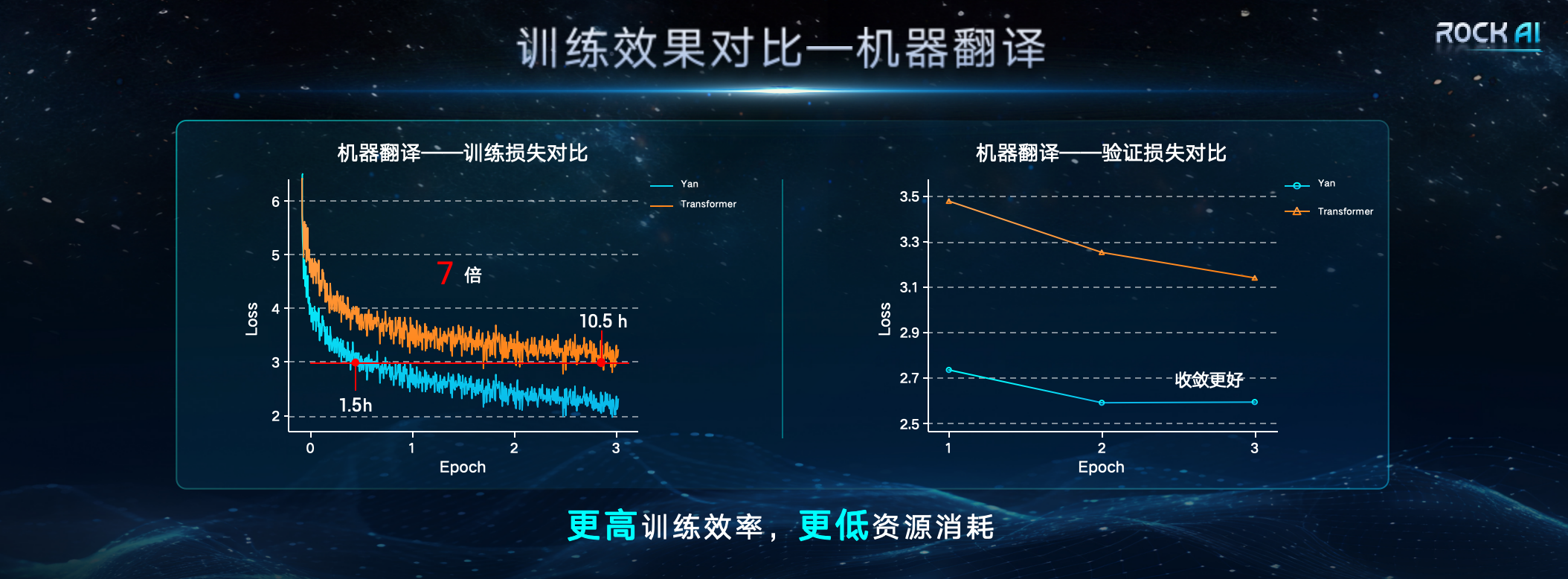
"Globally, many outstanding researchers have been trying to fundamentally solve the over-reliance on the Transformer architecture and seek better ways to replace Transformer. Even Llion Jones, one of the authors of the Transformer paper, In exploring the 'possibilities after Transformer', we try to use a nature-inspired intelligent method based on evolutionary principles to create a redefinition of the AI framework from different angles." Under resource conditions, the training efficiency and inference throughput of the Yan architecture model are 7 times and 5 times that of the Transformer architecture respectively, and the memory capacity is improved by 3 times. The design of the Yan architecture makes the space complexity of the Yan model constant during inference. Therefore, the Yan model also performs well against the long sequence problems faced by the Transformer. Comparative data shows that on a single 4090 24G graphics card, when the length of the model output token exceeds 2600, the Transformer model will suffer from insufficient video memory, while the video memory usage of the Yan model is always stable at around 14G, which theoretically enables infinite length inference. .
 In addition, the research team pioneered a reasonable correlation characteristic function and memory operator, combined with linear calculation methods, to reduce the complexity of the internal structure of the model. The Yan model under the new architecture will open the "uninterpretable black box" of natural language processing in the past, fully explore the transparency and explainability of the decision-making process, and thus facilitate the widespread use of large models in high-risk fields such as medical care, finance, and law.
In addition, the research team pioneered a reasonable correlation characteristic function and memory operator, combined with linear calculation methods, to reduce the complexity of the internal structure of the model. The Yan model under the new architecture will open the "uninterpretable black box" of natural language processing in the past, fully explore the transparency and explainability of the decision-making process, and thus facilitate the widespread use of large models in high-risk fields such as medical care, finance, and law.
The above is the detailed content of Yancore Digital releases a large-scale non-Attention mechanism model that supports offline device-side deployment. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



