


In many fields such as AR, VR, 3D printing, scene construction, and film production, high-quality 3D models of the human body wearing clothes are very important.
Traditional methods to create models require a lot of time and can only be completed by professional equipment and technical personnel.

On the contrary, in daily life, we usually use mobile phone cameras or Portrait photos found on the web.
Therefore, a method that can accurately reconstruct a 3D human model from a single image can significantly reduce costs and simplify the independent creation process.
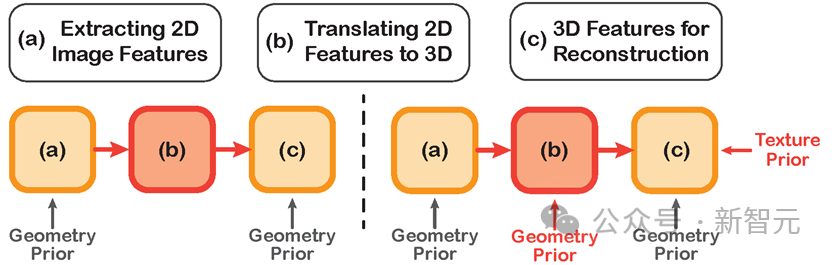 Comparison of the technical route of previous methods (left) and this method (right)
Comparison of the technical route of previous methods (left) and this method (right)
Previous depth Learning models for 3D human body reconstruction often require three steps: extracting 2D features from images, transferring 2D features to 3D space, and using 3D features for human body reconstruction.
However, these methods often ignore the introduction of human body priors in the stage of converting 2D features into 3D space, resulting in insufficient feature extraction and various defects in the final reconstruction results. .
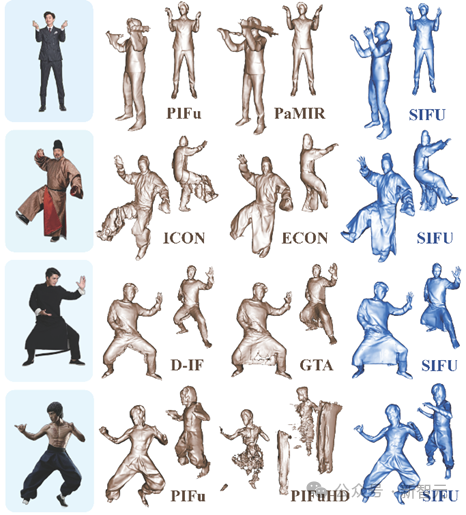 Comparison of the reconstruction effect of SIFU and other SOTA models
Comparison of the reconstruction effect of SIFU and other SOTA models
In addition, in the stage of texture prediction, In the past, models only relied on the knowledge learned in the training set and lacked prior knowledge of the real world, which often resulted in poor texture prediction in invisible areas.

SIFU introduces prior knowledge in the texture prediction stage to enhance the texture effect of invisible areas (back, etc.).
In this regard, researchers from Zhejiang University's ReLER Laboratory proposed the SIFU model, which relies on side view conditional implicit functions to reconstruct a 3D human body model from a single image.
 Picture
Picture
Paper address: https://arxiv.org/abs/2312.06704
Project address : https://github.com/River-Zhang/SIFU
This model enhances the geometric reconstruction effect by introducing the side view of the human body as a priori condition by converting 2D features into 3D space. And a pre-trained diffusion model is introduced in the texture optimization stage to solve the problem of poor texture in invisible areas.
The model pipeline is as follows:
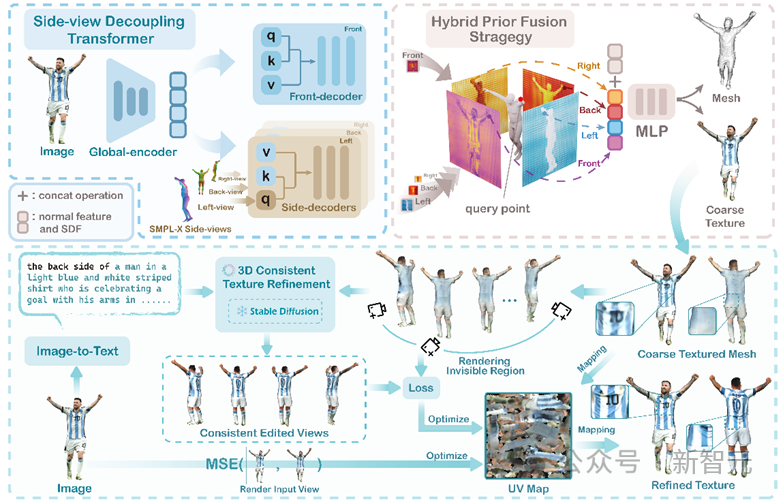 Pictures
Pictures
The model operation can be divided into two stages. The first stage uses the side implicit function to reconstruct the geometry (mesh) and rough texture (coarse texture) of the human body. The second stage uses the pre-trained Diffusion models refine textures.
In the first stage, the author designed a unique Side-view Decoupling Transformer. After extracting 2D features through the global encoder, the human body prior model SMPL- was introduced in the decoder. The side view of
This method successfully combines prior knowledge of the human body when converting 2D features into 3D space, resulting in a better reconstruction effect of the model.
In the second stage, the author proposes a 3D Consistent Texture Refinement process. First, the invisible areas of the human body (sides and backs) can be differentiated into A collection of pictures with continuous viewing angles, and then with the help of a diffusion model that learns prior knowledge from massive data, the rough texture pictures can be edited consistently to obtain more refined results. Finally, the texture map of the 3D model is optimized by calculating the loss from the images before and after refinement.
Higher reconstruction accuracy
In the experimental part, the author uses comprehensive Their models were tested on diverse test sets, including CAPE-NFP, CAPE-FP and THuman2.0, and compared with previous single-image human reconstruction SOTA models published at major conferences. After quantitative testing, the SIFU model showed the best results in both geometric reconstruction and texture reconstruction.
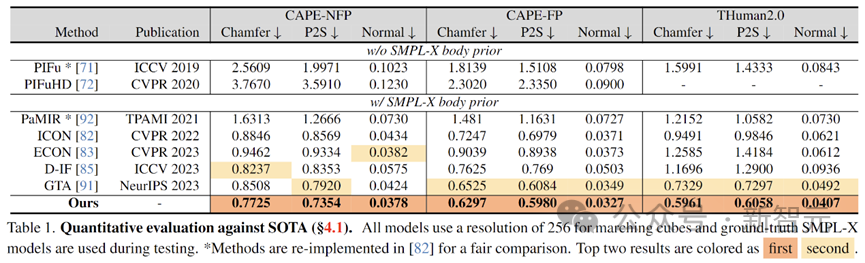 Quantitative evaluation of geometric reconstruction accuracy
Quantitative evaluation of geometric reconstruction accuracy
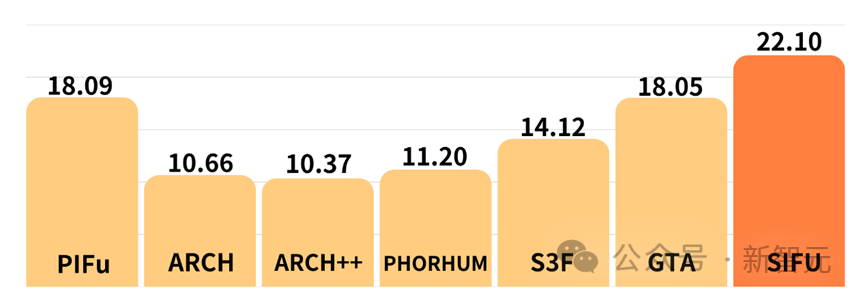 Quantitative evaluation of texture reconstruction effect
Quantitative evaluation of texture reconstruction effect
 Use public pictures on the Internet as input to demonstrate qualitative effects
Use public pictures on the Internet as input to demonstrate qualitative effects
Previous When the model is applied to data other than the training set, because the estimated human body prior model SMPL/SMPL-X is not accurate enough, the reconstruction results are often far different from the input image, making it difficult to put it into practical application.
In this regard, the author specifically tested the robustness of the model. By adding perturbations to the ground truth prior model parameters, the pose was shifted to simulate the real scene. SMPL-X estimates inaccurate situations to evaluate the accuracy of model reconstruction. The results show that the SIFU model still has the best reconstruction accuracy in this case.
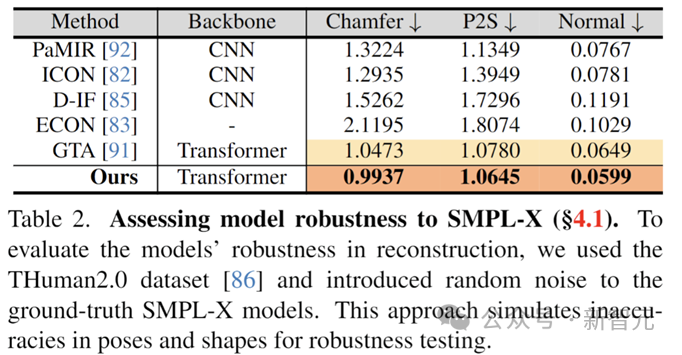 Evaluate the robustness of the model when facing a human body prior model with errors
Evaluate the robustness of the model when facing a human body prior model with errors
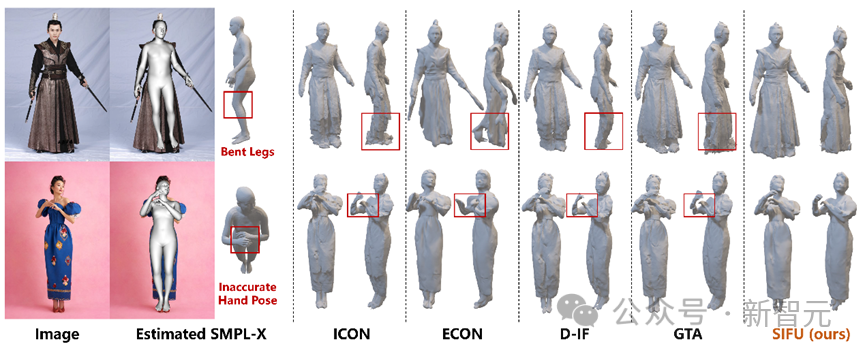 Using real-world pictures, SIFU still has a better reconstruction effect when the prior human body model estimation is inaccurate
Using real-world pictures, SIFU still has a better reconstruction effect when the prior human body model estimation is inaccurate
The high-precision and high-quality reconstruction effect of the SIFU model makes it suitable for a variety of application scenarios, including 3D printing, scene construction, texture editing, etc.
 3D printed SIFU reconstructed human body model
3D printed SIFU reconstructed human body model

 ##SIFU is used for 3D scene construction
##SIFU is used for 3D scene construction

##With the help of public action sequence data, the model reconstructed by SIFU can be driven Summary
Summary
Reference:
https://arxiv.org/abs/2312.06704
The above is the detailed content of Zhejiang University proposes new SOTA technology SIFU: only one picture can reconstruct high-quality 3D human body model. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



