


Yuanxiang released the world's first open source large model XVERSE-Long-256K with a context window length of 256K. This model supports the input of 250,000 Chinese characters, enabling large model applications to enter the "long text era." The model is completely open source and can be commercially used for free without any conditions. It also comes with detailed step-by-step training tutorials, which allows a large number of small and medium-sized enterprises, researchers and developers to realize "large model freedom" earlier.
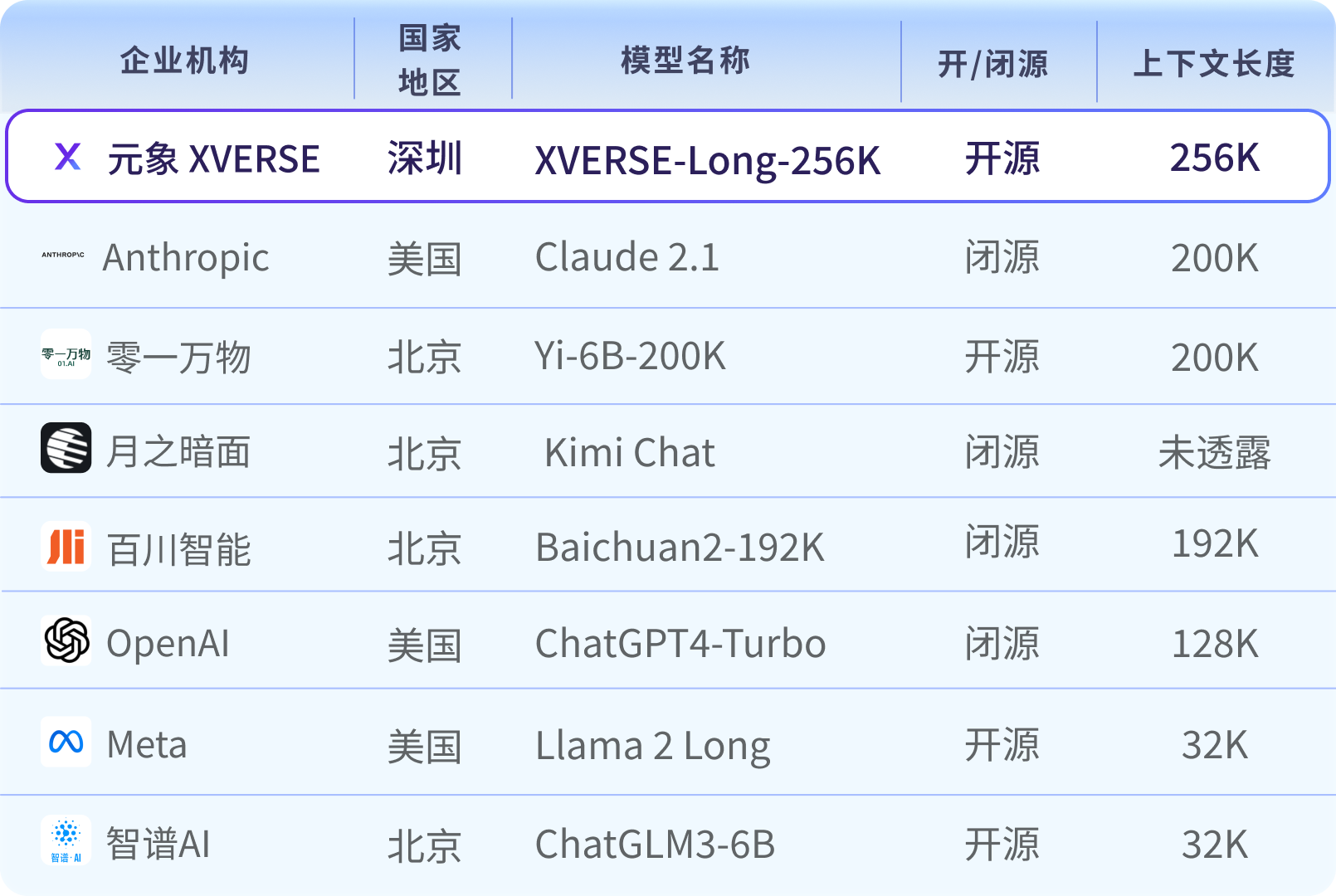 Global mainstream long text large model map
Global mainstream long text large model map
The amount of parameters and the amount of high-quality data determine the computational complexity of the large model, and long text technology (Long Context) is the "killer weapon" for the development of large-scale model applications. Due to the new technology and high difficulty in research and development, most of them are currently provided by paid closed sources.
XVERSE-Long-256K supports ultra-long text input and can be used for large-scale data analysis, multi-document reading comprehension, and cross-domain knowledge integration, effectively improving the depth and breadth of large model applications: 1. For lawyers and finance Analysts or consultants, prompt engineers, scientific researchers, etc. can solve the work of analyzing and processing longer texts; 2. In role-playing or chat applications, alleviate the memory problem of the model "forgetting" the previous dialogue, or the "hallucination" problem of nonsense etc.; 3. Better support for AI agents to plan and make decisions based on historical information; 4. Help AI native applications maintain a coherent and personalized user experience.
So far, XVERSE-Long-256K has filled the gap in the open source ecosystem, and has also formed a "high-performance family bucket" with Yuanxiang's previous 7 billion, 13 billion, and 65 billion parameter large models, improving domestic open source to the international first-class level. 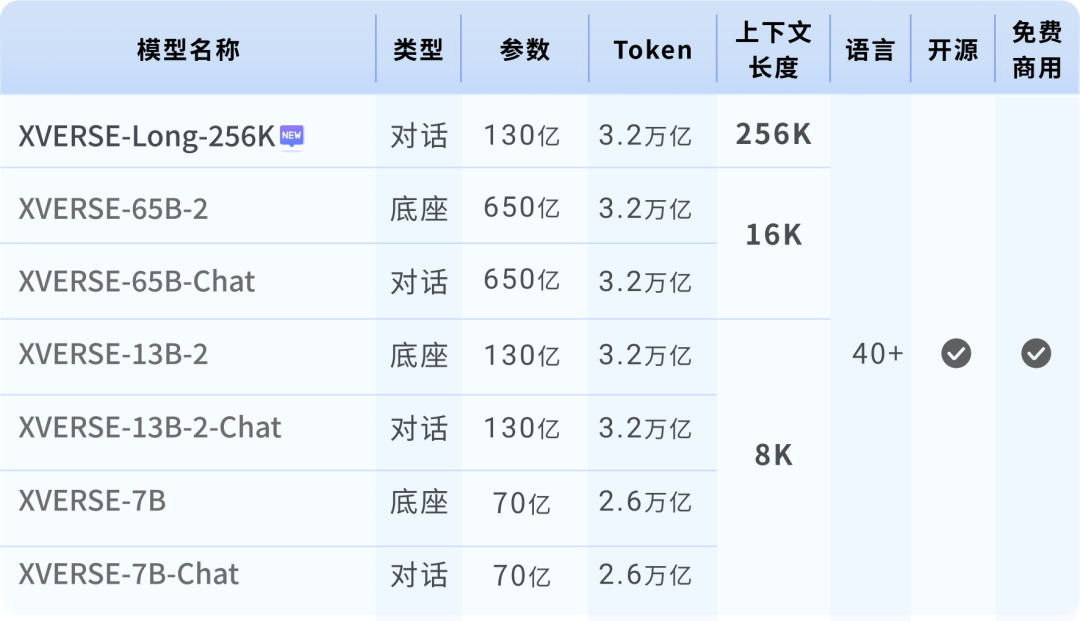 Yuanxiang large model series
Yuanxiang large model series
Free download of Yuanxiang large model
Excellent evaluation performance
In order to ensure that the industry has a comprehensive, objective and long-term understanding of the Yuanxiang large model, researchers refer to authoritative industries For evaluation, a 9-item comprehensive evaluation system with six dimensions has been developed. XVERSE-Long-256K all perform well, outperforming other long text models. Global mainstream long text open source large model evaluation results XVERSE-Long-256K passed the common long text large model performance stress test "finding the needle in the haystack". This test hides a sentence in a long text corpus that has nothing to do with its content, and uses natural language questions to let the large model accurately extract the sentence. 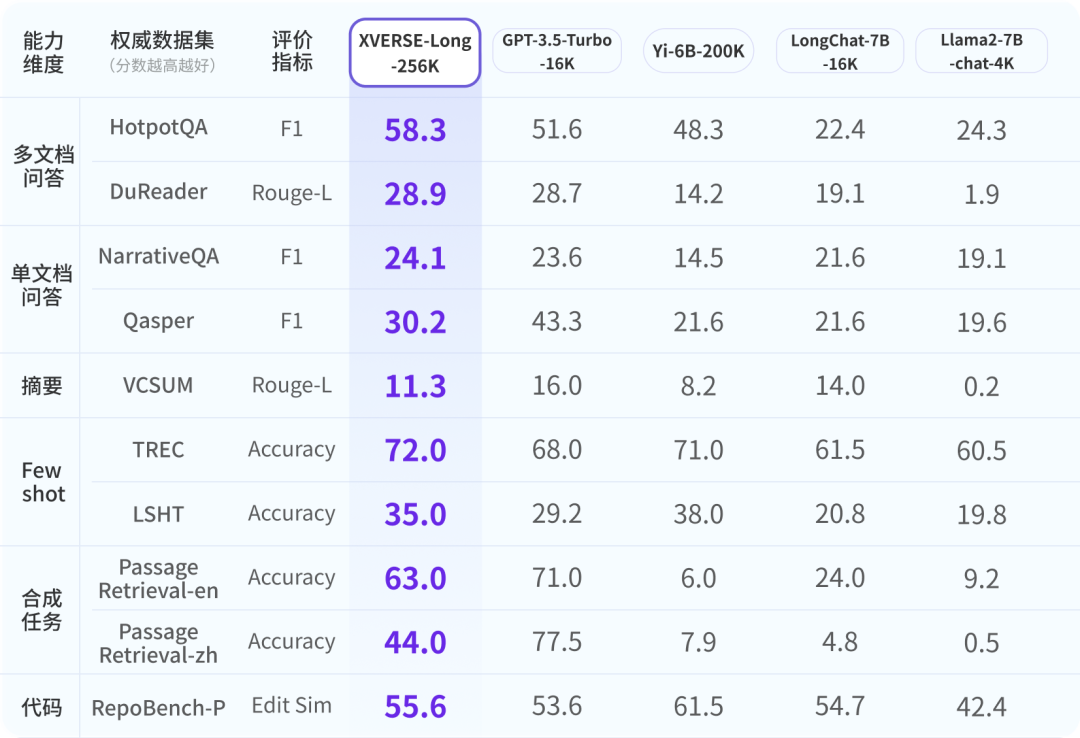 Novel
Novel
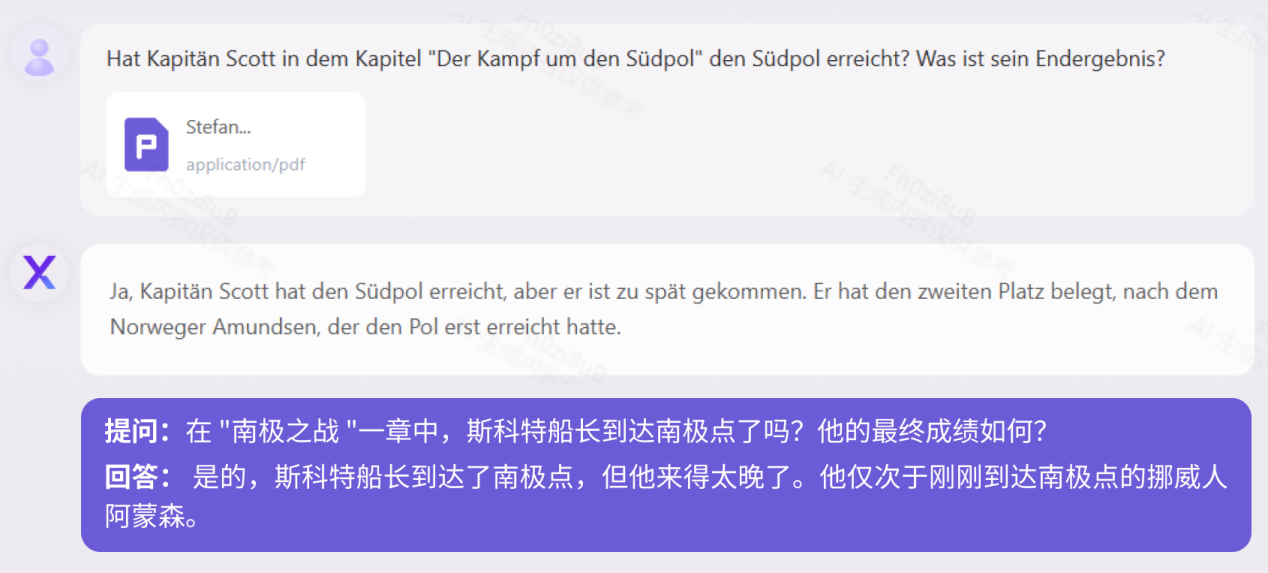
Reading ComprehensionAt present, most large-scale models in China only support Chinese and English bilingual, but Yuanxiang supports it More than 40 languages. We tested the 160,000-character Russian classic novel "How the Steel Was Tempered" and the 410,000-character German historical biography "When the Stars of Mankind Shine." "How Steel Was Tempered (Russian Version)" Test
"When the Human Stars Shine (German Version)" Test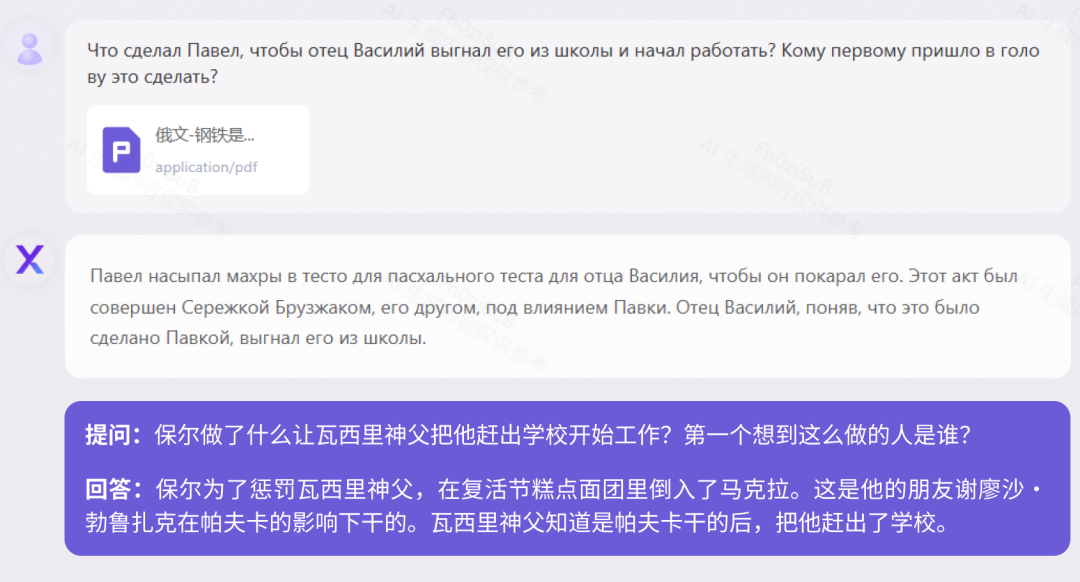
 Legal Articles
Legal Articles
Accurate Application Take the "Civil Code of the People's Republic of China" as an example to show the explanation of legal terms and cases Carry out logical analysis and combine it with practical and flexible applications:
## "Civil Code" testTeach you step by step how to train long text large models


1. Technical Challenge
2. Yuanxiang Technology Route
Long text large model technology is a new technology developed in the past year, and its main technical solutions For:
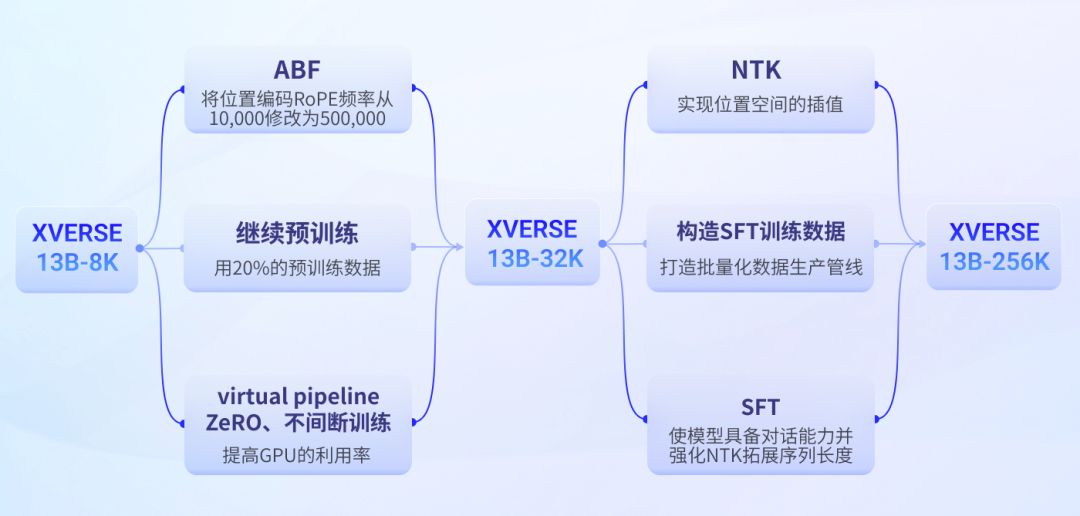
Yuanxiang long text large model training process
First stage:ABF Continue pre-training
The above is the detailed content of The world's longest open source model XVERSE-Long-256K, which is unconditionally free for commercial use. For more information, please follow other related articles on the PHP Chinese website!
 what is mysql index
what is mysql index
 What is highlighting in jquery
What is highlighting in jquery
 Ethereum browser blockchain query
Ethereum browser blockchain query
 How to retrieve Douyin flames after they are gone?
How to retrieve Douyin flames after they are gone?
 How to solve the problem of 400 bad request when the web page displays
How to solve the problem of 400 bad request when the web page displays
 Commonly used search tools
Commonly used search tools
 Free software for building websites
Free software for building websites
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



