In order to rewrite the content without changing the original meaning, the language needs to be rewritten into Chinese, and the original sentence does not need to appear
The editorial department of the website
The emergence of PowerInfer makes running AI on consumer-grade hardware more efficient
The Shanghai Jiao Tong University team has just launched PowerInfer, a super powerful CPU/GPU LLM high-speed inference engine. 
## Project address: https://github.com/SJTU-IPADS/PowerInfer

Paper address: https://ipads.se.sjtu.edu.cn/_media /publications/powerinfer-20231219.pdf
How fast?
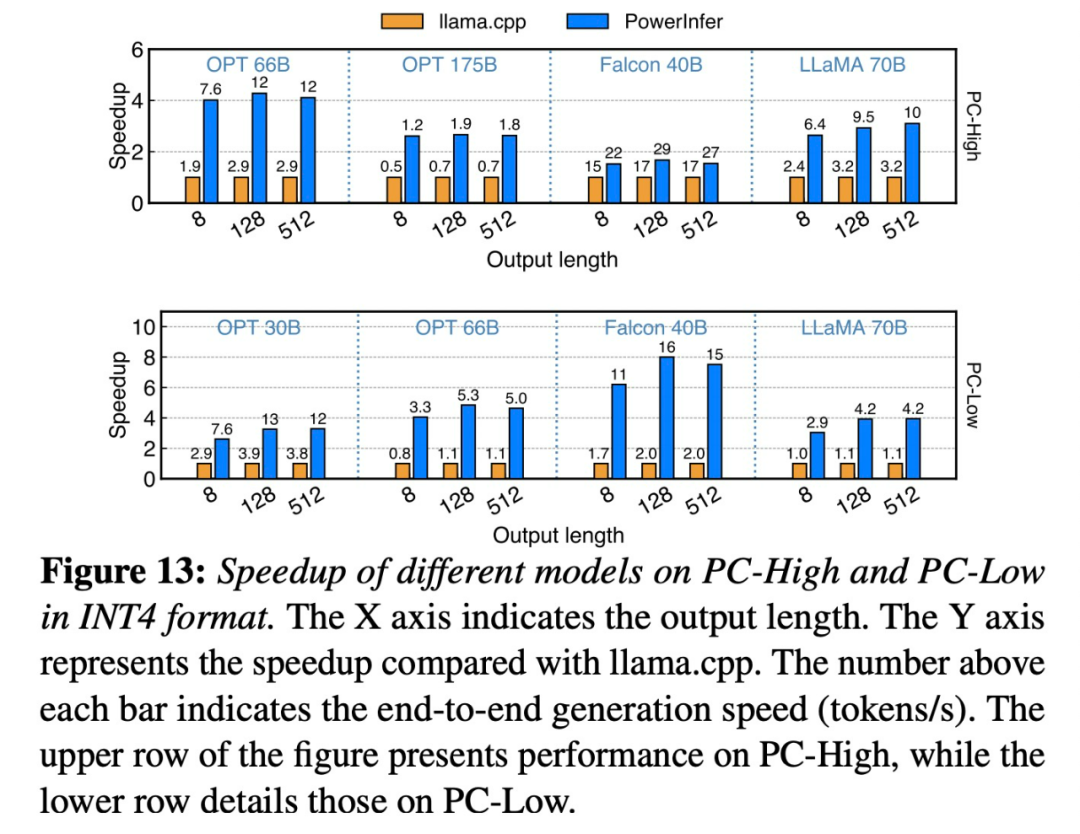
On a single RTX 4090 (24G) running Falcon (ReLU)-40B-FP16, PowerInfer achieved an 11x speedup compared to llama.cpp!
Both PowerInfer and llama.cpp run on the same hardware and take full advantage of VRAM on RTX 4090. Across various LLMs on a single NVIDIA RTX 4090 GPU, PowerInfer has an average token generation rate of 13.20 tokens/sec, with a peak of 29.08 tokens/sec. seconds, only 18% lower than the top server-grade A100 GPU.
##Specifically, PowerInfer is a high-speed inference engine for on-premises LLM deployment. It exploits the high locality in LLM inference to design a GPU-CPU hybrid inference engine. Hot-activated neurons are preloaded on the GPU for quick access, while cold-activated neurons are (mostly) computed on the CPU. This approach significantly reduces GPU memory requirements and CPU-GPU data transfers. PowerInfer can run large language models (LLM) at high speed on a personal computer (PC) equipped with a single consumer GPU. Users can now use PowerInfer with Llama 2 and Faclon 40B, with support for Mistral-7B coming soon. #The key to PowerInfer’s design is to exploit the high degree of locality inherent in LLM inference, which is characterized by the power-law distribution in neuronal activations.
Figure 7 below shows an architectural overview of PowerInfer, including offline and online components. 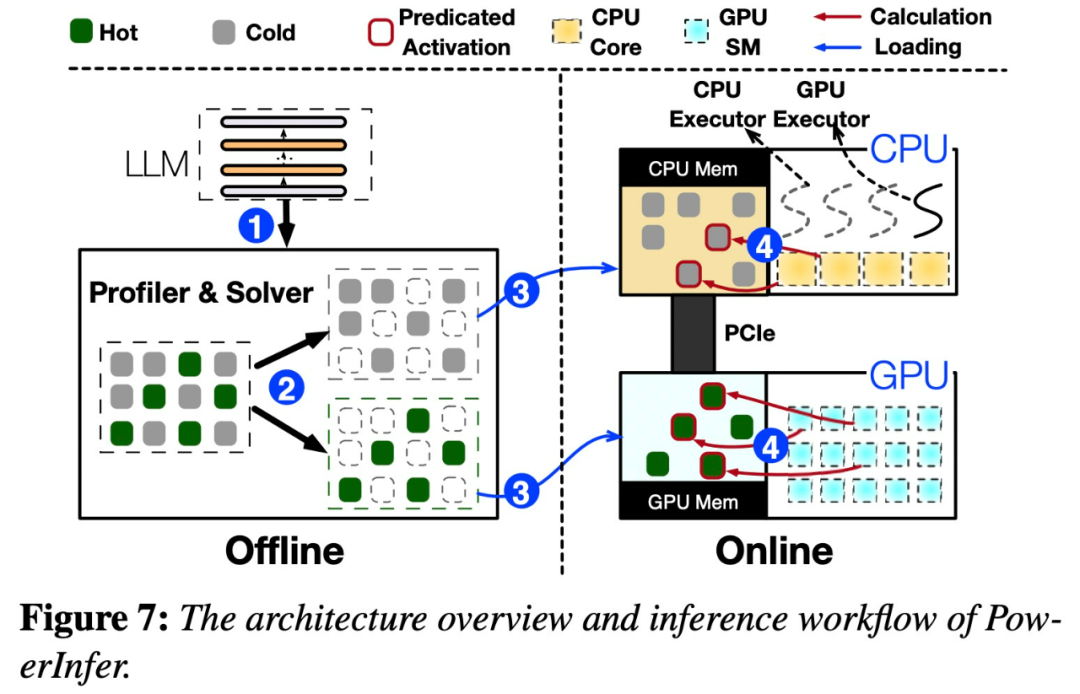
This distribution indicates that a small subset of neurons (called hot neurons) Activation is consistent across inputs, whereas most cold neurons vary depending on specific inputs. PowerInfer leverages this mechanism to design a GPU-CPU hybrid inference engine. 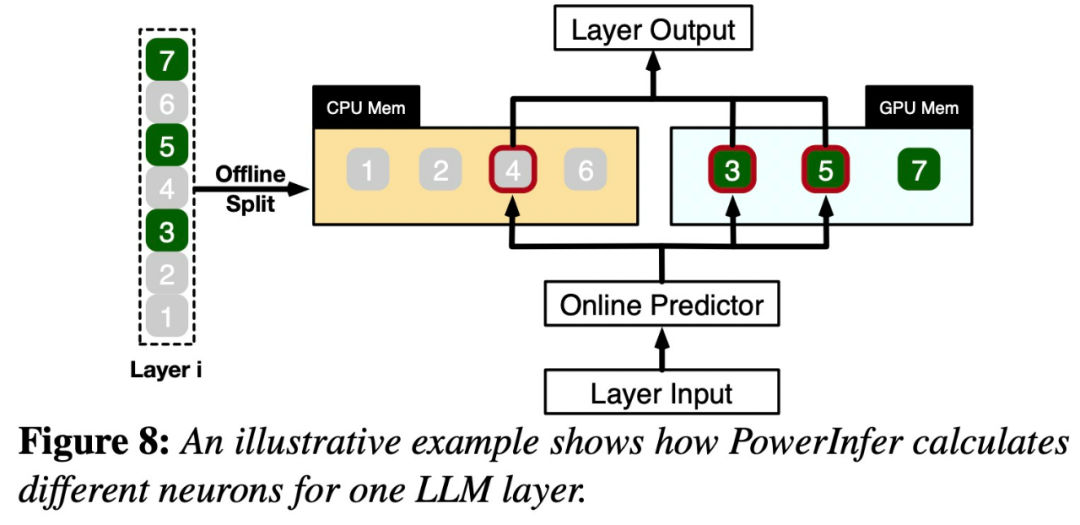
PowerInfer further integrates adaptive predictors and neuron-aware sparse operators to optimize It improves the efficiency of neuron activation and computational sparsity. After seeing this study, netizens expressed excitement: It is no longer a dream to run a 175B large model with a single card 4090. 
For more information, please view the original paper. The above is the detailed content of Shanghai Jiao Tong University releases inference engine PowerInfer. Its token generation rate is only 18% lower than A100. It may replace 4090 as a substitute for A100.. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



