


In the field of natural language processing, the Transformer model has attracted much attention due to its excellent sequence modeling performance. However, due to the limitation of context length during its training, neither it nor its large language model based on it can effectively handle sequences exceeding this length limit. This is called the lack of "effective length extrapolation" capability. This results in large language models performing poorly when processing long texts, or even being unable to handle them. In order to solve this problem, researchers have proposed a series of methods, such as truncation method, segmented method and hierarchical method. These methods aim to improve the effective length extrapolation capabilities of the model through some tricks, so that it can better handle extremely long sequences. Although these methods alleviate this problem to a certain extent, more research is still needed to further improve the effective length extrapolation ability of the model to better adapt to the needs of practical application scenarios.
Text continuation and language extension are one of the important aspects of human language ability. In the era of large models, length extrapolation has become an important method in order to effectively apply the capabilities of the model to long sequence data. Research on this issue has theoretical and practical value, so related work continues to emerge. At the same time, a systematic review is also needed to provide an overview of this field and continuously expand the boundaries of language models.
Researchers from Harbin Institute of Technology systematically reviewed the research progress of the Transformer model in length extrapolation from the perspective of position encoding. Researchers mainly focus on extrapolable position codes and extension methods based on these codes to enhance the length extrapolation ability of the Transformer model.

Paper link: https://arxiv.org/abs/2312.17044
Since the Transformer model itself cannot capture the positional information of each word in the sequence, positional encoding has become a common way to add it. Position encoding can be divided into two types: absolute position encoding and relative position encoding. Absolute position encoding adds a position vector to each word in the input sequence to represent the absolute position information of the word in the sequence. Relative position encoding encodes the relative distance between each pair of words in different positions. Both encoding methods can integrate the element order information in the sequence into the Transformer model to improve the performance of the model.
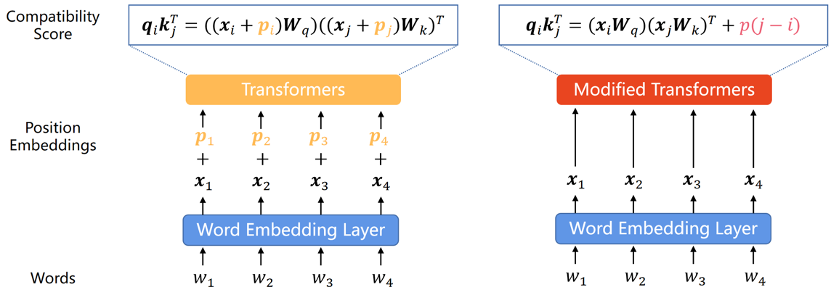
Given that existing research shows that this classification is critical to the model’s extrapolation capabilities, we will divide this section according to this classification.
Absolute position encoding
In the original Transformer paper, the position encoding is generated by sine and cosine functions ,Although this method has been proven not to ,extrapolate well, as the first PE of the Transformer, the,sine APE has a profound impact on subsequent PEs.
To enhance the extrapolation capabilities of the Transformer model, researchers either incorporate displacement invariance into sinusoidal APE through random displacements, or generate position embeddings that change smoothly with position and expect the model to learn Extrapolate this change function. Methods based on these ideas exhibit stronger extrapolation capabilities than sinusoidal APE, but still cannot reach the level of RPE. One reason is that APE maps different positions to different position embeddings, and extrapolation means the model must infer unseen position embeddings. However, this is a difficult task for the model. Because there are a limited number of position embeddings that recur during extensive pre-training, especially in the case of LLM, the model is highly susceptible to overfitting to these position encodings.
Relative position encoding
Because APE’s performance in length extrapolation is unsatisfactory, while RPE naturally Ground has better extrapolation capabilities due to its displacement invariance, and it is generally believed that the relative order of words in context is more important. In recent years, RPE has become the dominant method for encoding positional information.
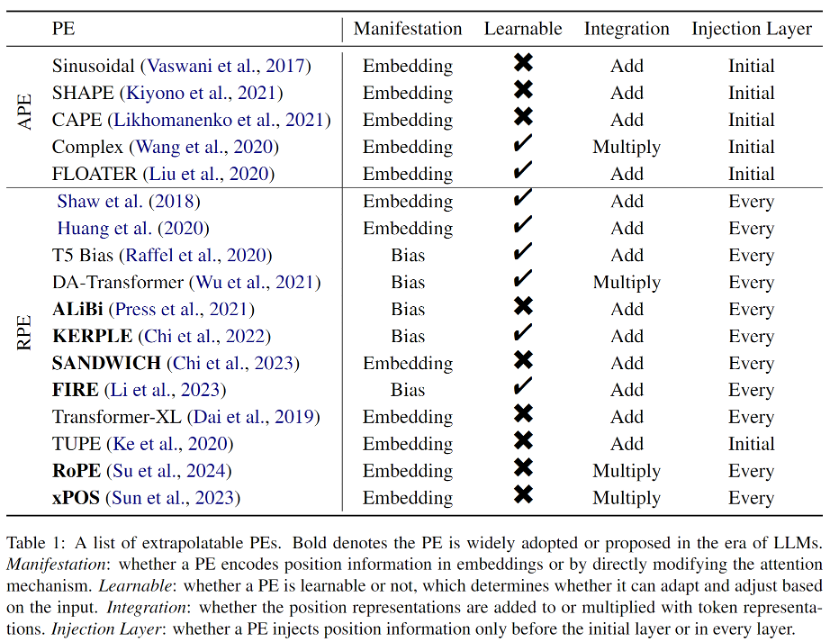
Early RPEs came from simple modifications to sinusoidal position encodings, often combined with pruning or binning strategies to avoid out-of-distribution position embeddings, which were thought to facilitate extrapolation. Furthermore, since RPE decouples the one-to-one correspondence between position and position representation, adding the bias term directly to the attention formula becomes a feasible or even better way to integrate position information into Transformer. This approach is much simpler and naturally disentangles the value vector and position information. However, although these biasing methods have strong extrapolation properties, they cannot represent complex distance functions as in RoPE (Rotary Position Embedding). Therefore, although RoPE has poor extrapolation, it has become the most mainstream position encoding for LLMs recently due to its excellent comprehensive performance. All extrapolable PEs introduced in the paper are shown in Table 1.
In order to enhance the length extrapolation ability of LLMs, research Researchers have proposed a variety of methods based on existing position encoding, mainly divided into two categories: position interpolation (Position Interpolation) and randomized position encoding (Randomized Position Encoding).
Position interpolation method
The position interpolation method scales the position encoding during inference so that it would otherwise exceed the model The position encoding of the training length is interpolated to fall into the trained position interval. Positional interpolation methods have attracted widespread interest from the research community due to their excellent extrapolation performance and extremely low overhead. Furthermore, unlike other extrapolation methods, positional interpolation methods have been widely used in open source models such as Code Llama, Qwen-7B, and Llama2. However, current interpolation methods only focus on RoPE, and how to make LLM using other PEs have better extrapolation capabilities through interpolation still needs to be explored.
Randomized position encoding
# Simply put, randomizing PE is just by introducing random positions during training. Decoupling pre-trained context windows from longer inference lengths improves the exposure of all locations in longer context windows. It is worth noting that the idea of randomized PE is very different from the position interpolation method. The former aims to make the model observe all possible positions during training, while the latter tries to interpolate the positions during inference so that they fall into a predetermined location. For the same reason, positional interpolation methods are mostly plug-and-play, while randomized PE often requires further fine-tuning, which makes positional interpolation more attractive. However, these two categories of methods are not mutually exclusive, so they can be combined to further enhance the extrapolation capabilities of the model.
Evaluation and Benchmark Datasets:In Early Research , the evaluation of Transformer's extrapolation ability comes from the performance evaluation indicators of various downstream tasks, such as BLEU of machine translation; as language models such as T5 and GPT2 gradually unify natural language processing tasks, the perplexity used in language modeling becomes the basis for extrapolation. Evaluation indicators. However, the latest research has shown that perplexity cannot reveal the performance of downstream tasks, so there is an urgent need for dedicated benchmark data sets and evaluation metrics to promote further development in the field of length extrapolation.
Theoretical Explanation:Current work related to length extrapolation is mostly empirical, although there are some preliminary examples of successful extrapolation by explanatory models. attempts, but a solid theoretical foundation has not yet been established, and exactly what factors affect and how they affect length extrapolation performance remains an open question.
Other methods:As mentioned in this article, most of the existing length extrapolation work focuses on the positional encoding perspective, but it is not difficult to Understand that length extrapolation requires systematic design. Positional encoding is a key component, but by no means the only one, and a broader view will further stimulate the problem.
The above is the detailed content of Application of positional encoding in Transformer: exploring the infinite possibilities of length extrapolation. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist What's the matter with Douyin crashing?
What's the matter with Douyin crashing? Characteristics of management information systems
Characteristics of management information systems Usage of accept function
Usage of accept function Introduction to service providers with cost-effective cloud server prices
Introduction to service providers with cost-effective cloud server prices Can program files be deleted?
Can program files be deleted? Commonly used linux commands
Commonly used linux commands java string to number
java string to number




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



