


Google Research recently conducted an evaluation study on popular language models, using its own BIG-Bench benchmark and the newly established "BIG-Bench Mistake" data set. They mainly focused on the error probability and error correction ability of the language model. This study provides valuable data to better understand the performance of language models on the market.
Google researchers said they created a special benchmark data set called "BIG-Bench Mistake" to evaluate the "error probability" and "self-correction ability" of large language models. This is due to the lack of corresponding data sets in the past to effectively evaluate and test these key indicators.
The researchers used the PaLM language model to run 5 tasks in their own BIG-Bench benchmark task, and added the generated "Chain-of-Thought" trajectory to the "Logic Error" part. Retest model accuracy.
In order to improve the accuracy of the data set, Google researchers repeatedly performed the above process and finally created a benchmark data set specifically for evaluation, which contains 255 logical errors, called "BIG-Bench Mistake" .
The researchers pointed out that the logical errors in the "BIG-Bench Mistake" data set are very obvious and therefore can be used as a good standard for language model testing. This dataset helps the model learn from simple errors and gradually improve its ability to identify errors.
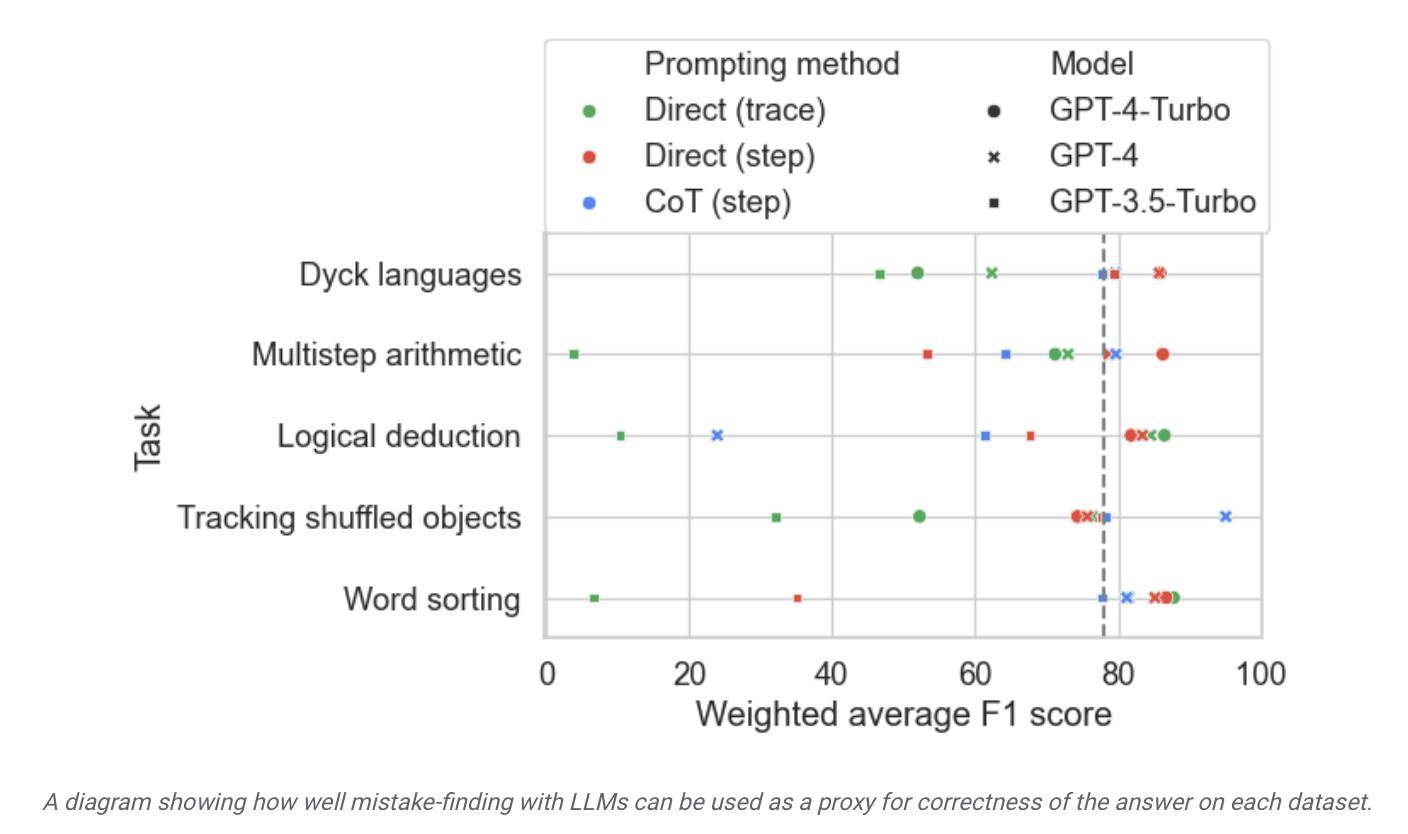
The researchers used this data set to test models on the market and found that although most language models can identify logical errors in the reasoning process and correct themselves, this process is not very ideal. Often, human intervention is also required to correct what the model outputs.
▲ Picture source Google Research Press Release
According to the report, Google claims that it is considered the most advanced large language model currently, but its self-correction ability is relatively limited. In tests, the best-performing model found only 52.9% of logical errors.

Google researchers also claimed that this BIG-Bench Mistake data set is conducive to improving the self-correction ability of the model. After fine-tuning the model on relevant test tasks, "even small model performance is usually better than that of large models with zero sample prompts." better".
According to this, Google believes that in terms of model error correction, proprietary small models can be used to "supervise" large models. Instead of letting large language models learn to "correct self-errors", deploying small dedicated models dedicated to supervising large models has the advantage of This will help improve efficiency, reduce related AI deployment costs, and make fine-tuning easier.
The above is the detailed content of Google launches BIG-Bench Mistake data set to help AI improve error correction capabilities. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



