


Paper link: https://arxiv.org/pdf/2401.03907.pdf
The multi-modal 3D detector is designed to study safe and reliable autonomous driving perception systems. Although they achieve state-of-the-art performance on clean benchmark datasets, the complexity and harsh conditions of real-world environments are often ignored. At the same time, with the emergence of the visual basic model (VFM), improving the robustness and generalization capabilities of multi-modal 3D detection faces opportunities and challenges in autonomous driving. Therefore, the authors propose the RoboFusion framework, which leverages VFM like SAM to address out-of-distribution (OOD) noise scenarios.
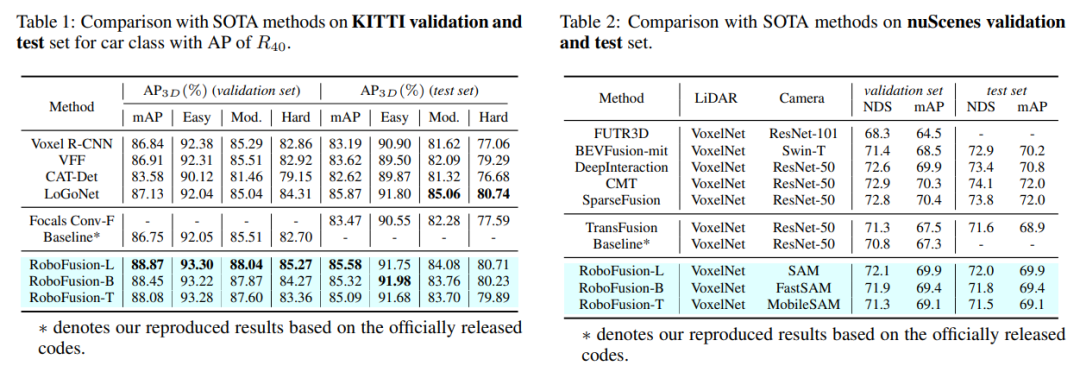
First, we apply the original SAM to an autonomous driving scenario named SAM-AD. To align SAM or SAMAD with multi-modal methods, we introduce AD-FPN to upsample the image features extracted by SAM. To further reduce noise and weather interference, we employ wavelet decomposition to denoise the depth-guided images. Finally, we use a self-attention mechanism to adaptively reweight the fused features to enhance informative features while suppressing excess noise. RoboFusion enhances the resilience of multi-modal 3D object detection by leveraging the generalization and robustness of VFM to gradually reduce noise. As a result, RoboFusion achieves state-of-the-art performance in noisy scenes, according to results from the KITTIC and nuScenes-C benchmarks.
The paper proposes a robust framework, named RoboFusion, which utilizes VFM like SAM to adapt 3D multi-modal object detectors from clean scenes to OOD noisy scenes. Among them, SAM's adaptation strategy is the key.
1) Use features extracted from SAM instead of inferring segmentation results.
2) SAM-AD is proposed, which is a pre-trained SAM for AD scenarios.
3) A new AD-FPN is introduced to solve the feature upsampling problem for aligning VFM with multi-modal 3D detectors.
In order to reduce noise interference and retain signal characteristics, the Deep Guided Wavelet Attention (DGWA) module is introduced to effectively attenuate high and low frequency noise.
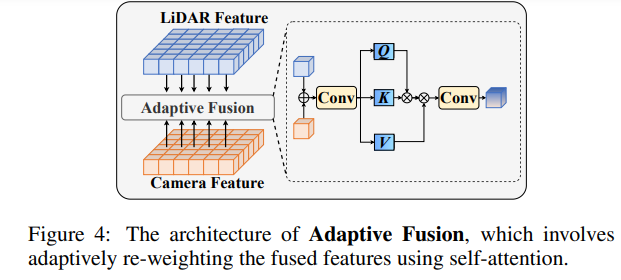
After fusing point cloud features and image features, reweight the features through adaptive fusion to enhance the robustness and noise resistance of the features.
The RoboFusion framework is shown below, with its lidar branch following the baseline [Chen et al., 2022; Bai et al., 2022] to generate laser light Radar signature. In the camera branch, the highly optimized SAM-AD algorithm is first used to extract robust image features, and combined with AD-FPN to obtain multi-scale features. Next, the original points are used to generate a sparse depth map S, which is input into the depth encoder to obtain depth features, and is fused with multi-scale image features to obtain depth-guided image features. Then, the mutation noise is removed through the fluctuating attention mechanism. Finally, adaptive fusion is achieved through a self-attention mechanism to combine point cloud features with robust image features with depth information.
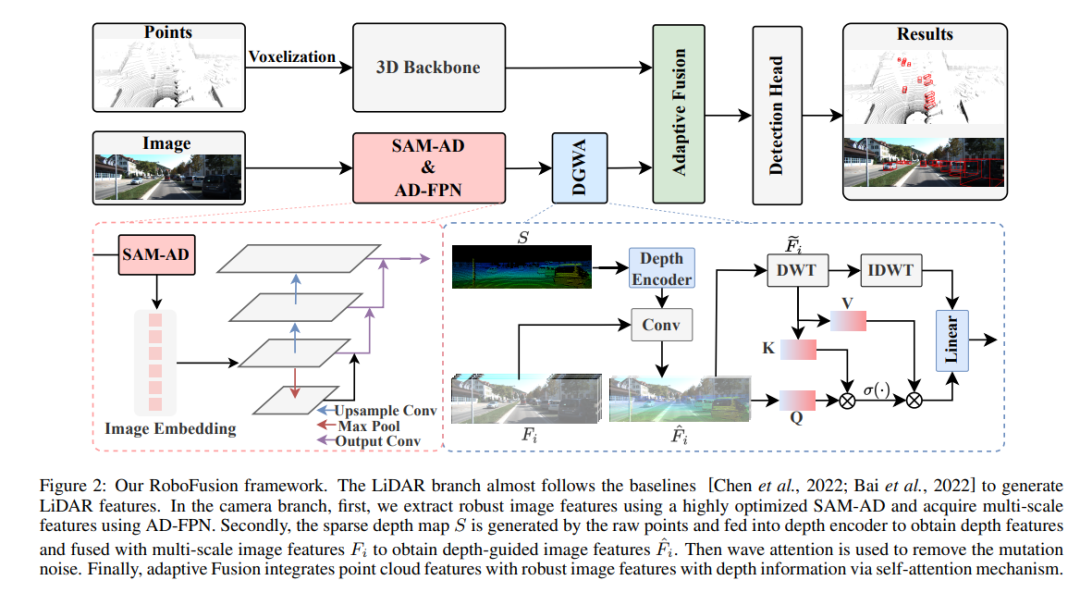
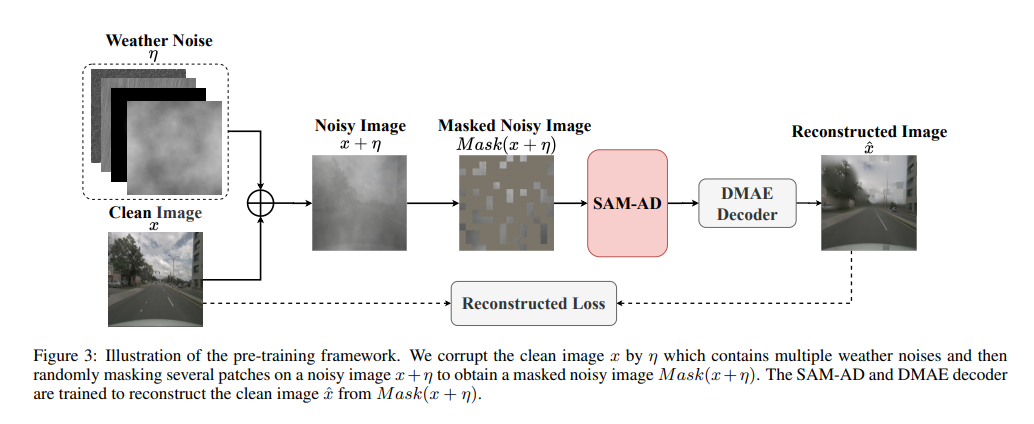
SAM-AD: In order to further adapt SAM to AD (autonomous driving) scenarios, SAM is pre-trained to obtain SAM-AD. Specifically, we collect a large number of image samples from mature datasets (i.e., KITTI and nuScenes) to form the basic AD dataset. After DMAE, SAM is pre-trained to obtain SAM-AD in AD scenarios, as shown in Figure 3. Denote x as the clean image from the AD dataset (i.e. KITTI and nuScenes) and eta as the noisy image generated based on x. The noise type and severity were randomly selected from four weather conditions (i.e., rain, snow, fog, and sunshine) and five severity levels from 1 to 5, respectively. Using SAM, MobileSAM's image encoder as our encoder, while the decoder and reconstruction losses are the same as DMAE.
AD-FPN. As a cueable segmentation model, SAM consists of three parts: image encoder, cue encoder and mask decoder. In general, it is necessary to generalize the image encoder to train the VFM and then train the decoder. In other words, the image encoder can provide high-quality and highly robust image embeddings to downstream models, while the mask decoder is only designed to provide decoding services for semantic segmentation. Furthermore, what we need is robust image features rather than the processing of cue information by the cue encoder. Therefore, we use SAM’s image encoder to extract robust image features. However, SAM utilizes the ViT series as its image encoder, which excludes multi-scale features and only provides high-dimensional low-resolution features. In order to generate multi-scale features required for target detection, inspired by [Li et al., 2022a], an AD-FPN is designed, which provides multi-scale features based on ViT!
Despite the ability of SAM-AD or SAM to extract robust image features, the gap between the 2D domain and the 3D domain still exists, and cameras lacking geometric information in damaged environments often amplify noise and cause negative transfer problems. To alleviate this problem, we propose the Deep Guided Wavelet Attention (DGWA) module, which can be divided into the following two steps. 1) A depth guidance network is designed to add geometry before image features by combining image features and depth features of point clouds. 2) Use Haar wavelet transform to decompose the features of the image into four sub-bands, and then the attention mechanism allows to denoise the information features in the sub-bands!
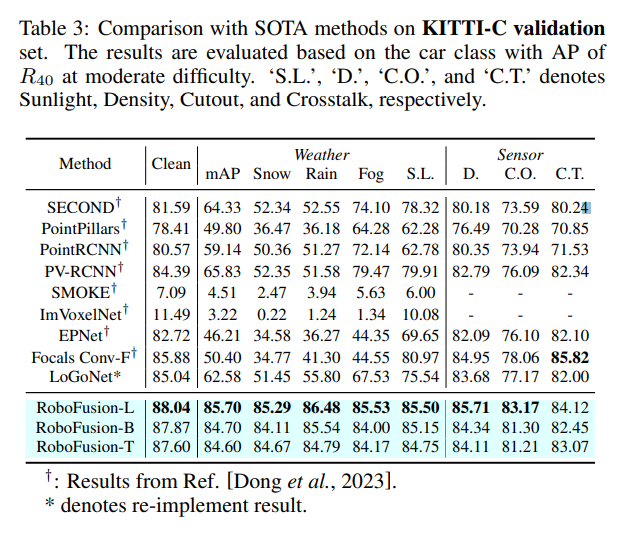
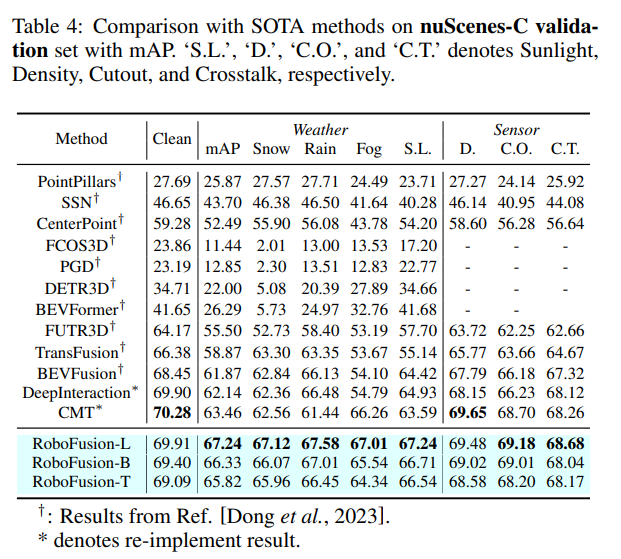
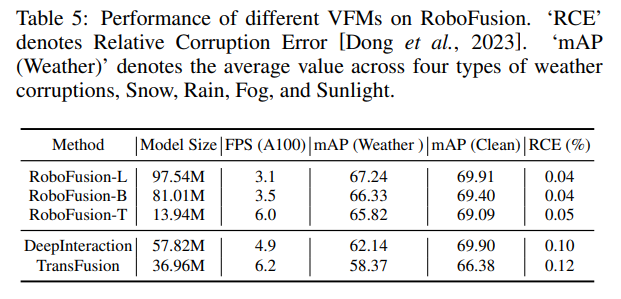


The above is the detailed content of RoboFusion for reliable multi-modal 3D detection using SAM. For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



