


With the widespread application of new technologies such as virtualization and cloud computing, the scale of IT infrastructure within enterprise data centers has grown rapidly. This resulted in an increase in the size of computer hardware and software, as well as frequent computer failures. Therefore, front-line operation and maintenance personnel urgently need more professional and powerful operation and maintenance tools to meet the challenges.
In the daily operation and maintenance of data centers, basic monitoring systems and application monitoring systems are usually used to build fault discovery mechanisms. By setting preset thresholds, when various software and hardware abnormalities occur, indicator items will exceed these thresholds, thus triggering alarms. Operations experts are notified immediately and perform troubleshooting to ensure stable operation of the data center. Such a monitoring mechanism can detect and solve potential problems in time, improving the reliability and availability of the data center.
The event intelligent analysis system is a system designed to resolve alarm transitions and analyze and handle them.
The event intelligent analysis system creates a full-process fault handling system of "fault identification-fault analysis-fault handling", and integrates the experience of operation and maintenance experts into a digital model. When a fault occurs, it can automatically "identify the fault- Analysis-Disposal", thereby shortening MTTR (Mean Time To Repair).
The event intelligent analysis system introduces AI technology to empower each module of the system. When the operation and maintenance expert does not manually establish a fault model, AI will automatically establish a fault for the alarm and automatically analyze it. , and then provide an analysis plan to assist operation and maintenance experts in analyzing the fault. AI empowerment reduces the modeling workload pressure of operation and maintenance experts, and also makes up for the experience blind spots of operation and maintenance experts.
The following is the overall architecture diagram of the event intelligent analysis system:
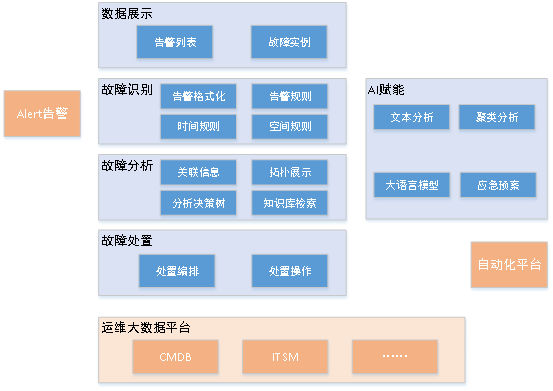 Picture
Picture
The blue part is the functional module of the event intelligent analysis system, and the orange part is the peripheral system, providing corresponding data or interfaces.
Unified event platform: Alert system collects data from each monitoring system (basic monitoring , application monitoring, log monitoring), after unified aggregation, they are converted into a unified format and sent to kafka; the event intelligent analysis system will read all alarm data from the kafka system.
Automation platform: Operation and maintenance experts create some arrangements and scripts on the automation platform in advance as a method to deal with faults. When the root cause is found through fault analysis, it can be handled by calling the automation platform interface. Tasks are orchestrated and issued for execution, ultimately achieving the purpose of automatic processing.
CMDB: During fault analysis, the object instance attributes and relationships stored in the CMDB can be used to logically associate alarm instances and disposal instances; at the same time, some of the objects surrounding the alarm object can be displayed. When providing information, the corresponding CMDB object instance data also needs to be associated.
ITSM: Provides work order data such as change orders and incident orders. When a failure occurs, these work order data need to be used for analysis.
Operation and maintenance big data platform: The big data platform provides data cleaning tools to help the event intelligent analysis platform clean the required data, and also provides technical support for massive data storage; big data The platform is a solid foundation for the data required for event intelligent analysis. It also provides analysis data for subsequent AI analysis, including object data from CMDB, work order data from ITSM, indicator data and alarm data from the monitoring system, etc.
The main function of fault identification is to establish a fault model, which can define the rules for converting alarms into faults. At the same time, the definition of the fault model is also a simple classification of faults, such as high CPU usage faults, high memory usage faults, etc. High disk usage faults, network delay faults, etc. Simply put, it means which alarms can become a fault. The relationship between the number of alarms and faults can be either 1:1 or n:1; only the relationship between Only by identifying the specific fault can subsequent analysis and processing be facilitated.
Alarm formatting:
The alarms received from the unified event platform are standardized and processed by the event intelligent processing system. The required format, some fields need to be supplemented by searching for the object instance data of configuration management.
Fault model definition:
The definition of fault scenario model mainly includes basic information, fault rules, analysis and decision-making functions, etc. The specific description is as follows:
1) Basic information includes fault name, belonging object, fault type and fault description;
2) Fault rules can be divided into The following categories:
#3) Associate the specified analysis decision tree to determine the analysis plan.
Fault analysis is based on related data display, topology data display, analysis decision tree and Faults are analyzed and displayed in multiple aspects such as knowledge base retrieval, providing data support for operation and maintenance experts to help them quickly find the root cause of the fault and handle the fault. The analysis decision tree can be associated with disposition.
Related information display:
1) Alarm analysis: the physical subsystem corresponding to the alarm object and other software and hardware objects associated with the deployment unit Alarm data in the last 48 hours;
2) Indicator analysis: Indicator data of the physical subsystem corresponding to the alarm object and other software and hardware objects associated with the deployment unit within 2 hours before the failure;
3) Change analysis: Change work order records of the system corresponding to the alarm object in the last 48 hours, and conduct change analysis;
4) Log analysis: Application of specified paths for the alarm object and surrounding objects Logs and system logs are analyzed and displayed;
5) Link analysis: With the transaction code as the core, the upstream and downstream link data of the transaction code involved in the alarm object is analyzed and displayed;
Topological structure display:
Taking the physical subsystem as the dimension, the operation and maintenance objects involved in the entire system are organized in a tree topology structure Display, and at the same time, nodes with alarms are marked red to alert operation and maintenance experts.
Specific examples are as follows:
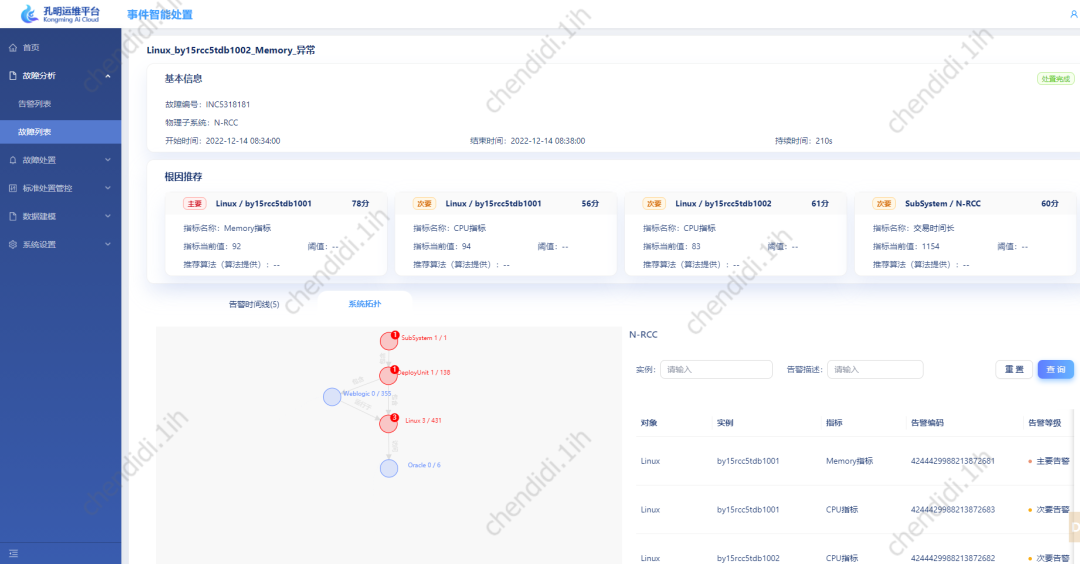 Picture
Picture
Analysis decision tree:
Based on data such as CMDB objects and relationships, alarms, indicators, changes, logs and links, it is integrated into a customizable and editable analysis decision tree.
Operation and maintenance experts can preset the order and judgment criteria for analyzing data, and precipitate operation and maintenance experience into the analysis decision tree in the form of a digital model. When a failure occurs, the platform will Analyze and judge relevant data according to the preset analysis decision tree, and finally provide the results.
The final leaf nodes of the analysis decision tree can be associated with disposal, ensuring the automated operation of the entire life cycle of "identification-analysis-disposal" of faults.
The specific examples are as follows:
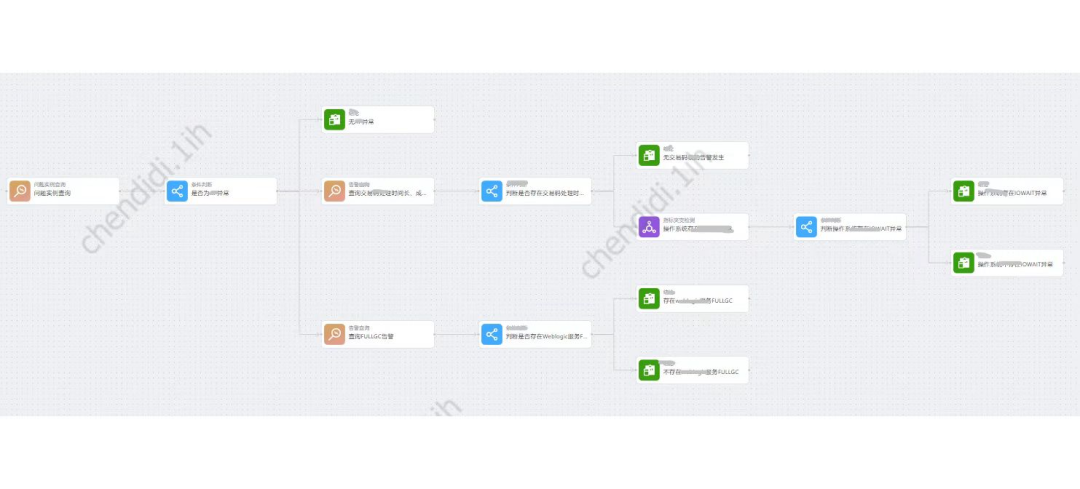 Picture
Picture
Knowledge base search:
The data center builds a knowledge base system based on the data on the operation and maintenance big data platform. It mainly collects text data such as emergency plans, incident order processing records, and operation and maintenance expert experience summaries.
When a fault occurs, the fault keyword will be used to search the knowledge base (string matching), and the corresponding text knowledge will be returned as expert experience. In the chapter on AI empowerment, we will talk about using text analysis for related searches, not just simple string matching.
Fault handling is mainly handled according to the pre-defined handling model, which mainly includes handling Decision-making, orchestration and disposal operations need to rely on an automation platform to orchestrate and execute disposal tasks.
1) Disposal orchestration: Disposal orchestration is an organic combination of a series of disposal operations, because some disposals require the operation and maintenance objects to be isolated and then restarted; edit the script of the disposal operation in the process , so that several operation scripts are delivered to specific instance machines in a predetermined order and executed;
2) Disposal operation: Encapsulate the script (shell, python) so that it can be Executed on the instance machine, it can also be called by the processing orchestration; the processing operation is the minimum action of the processing, such as tomcat restart, isolation, circuit breaker and other scripts;
Fault handling is mostly based on operation and maintenance experts Experience or emergency plan documents are digitally precipitated into models.
After the fault handling is completed, relevant records of the handling will be recorded according to the process for subsequent review and analysis.
AI empowerment is to minimize the manual configuration workload and reduce the work pressure of operation and maintenance experts in the entire process of "identification-analysis-disposal" of faults. It can also make up for the parts that cannot be covered by the experience of operation and maintenance experts, and It can cover 100% of the alarm types that have occurred in history during the initialization stage; the overall principle is to use AI calculations to build fault models and analysis in the field of fault identification and analysis through automatic modeling, automatic aggregation, automatic analysis, etc. The plan provides a reference for operation and maintenance experts, but ensures that the final judgment and control are made by operation and maintenance experts, ensuring that the algorithm does 99% of the work, and manual review ensures the last 1% of the work.
Reviewing the definition of fault model in Chapter 3-1, we found that as long as we determine Alarm rules, time rules and space rules, and the analysis decision tree can be determined at the same time to build a fault model. The time rules and space rules can default to the most common immediate execution and the same machine, and the analysis decision tree can use the most conventional health checks.
Therefore, when establishing a fault model and building a model for the same type of faults, the core issue is to classify the faults through the alarm content, and we use the keywords of the alarm content to determine the classification. , and then establish a certain type of fault model. Then the problem of automatic modeling degenerates into finding keywords for alarms and establishing fault models based on them.
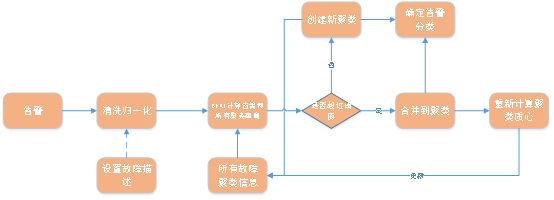
The overall logic diagram is as follows:
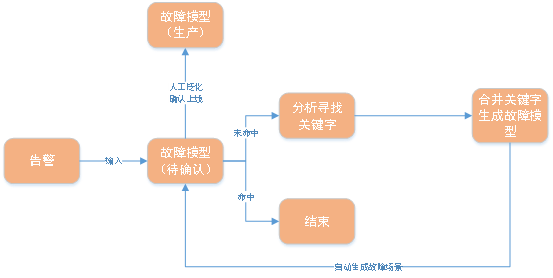 Picture
Picture
Input historical alarms and real-time alarms into the fault model one by one. If the existing fault model can be matched, the processing of this alarm will end; if there is no fault model that can be matched, the algorithm will be used to calculate Keyword of this alarm content, and use this keyword to build a fault model, and then add the newly built fault model to the fault model list.
Operation and maintenance experts can generalize the fault model and put it online through manual confirmation.
This automatic modeling method has the following advantages:
1) Alarms can be processed in real time and fault modeling can be performed in real time. , the speed of updating the model is very fast;
2) Modeling does not rely on the experience of operation and maintenance experts, and can be modeled directly through the alarm content;
3) All historical alarms can be covered, and Can respond to new types of alarms in real time;
4) There is no need for operation and maintenance experts to perform a large amount of model setting work, saving manpower; operation and maintenance experts only need to do the final manual confirmation, which improves efficiency while ensuring results;
Generally speaking, words that appear frequently in documents to be calculated, but have a low probability of appearing in massive documents, have a higher probability of becoming keywords, so part of the alarm memory is used for processing. The results are as follows:
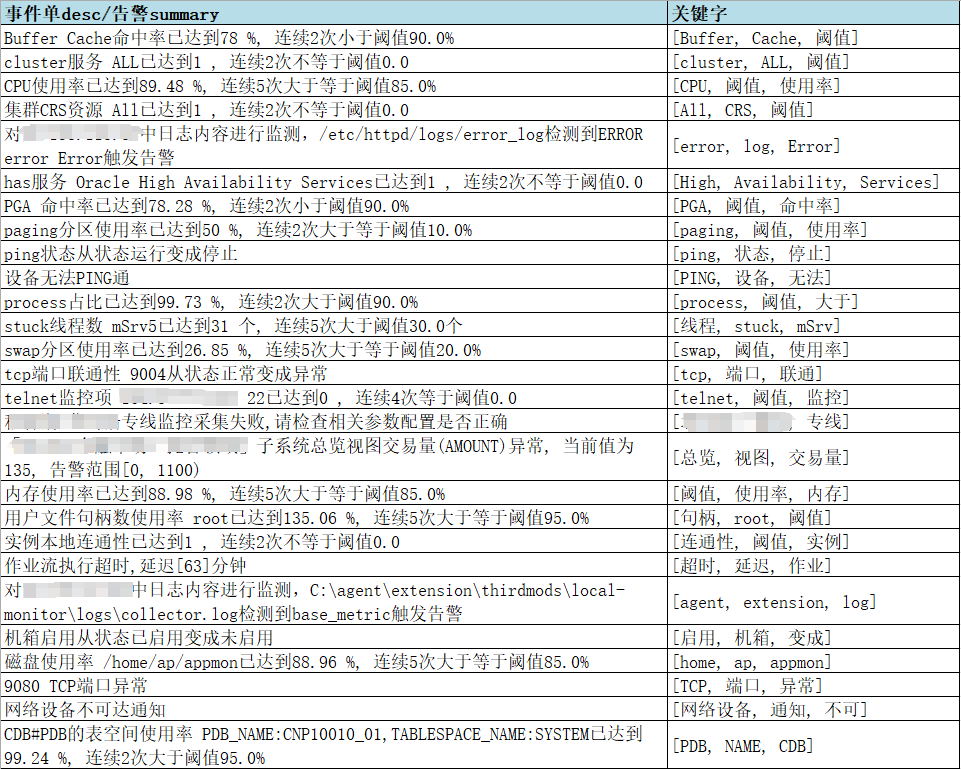 Picture
Picture
Using the above algorithm and using part of the alarm content for calculation, we get The data effect is as follows:
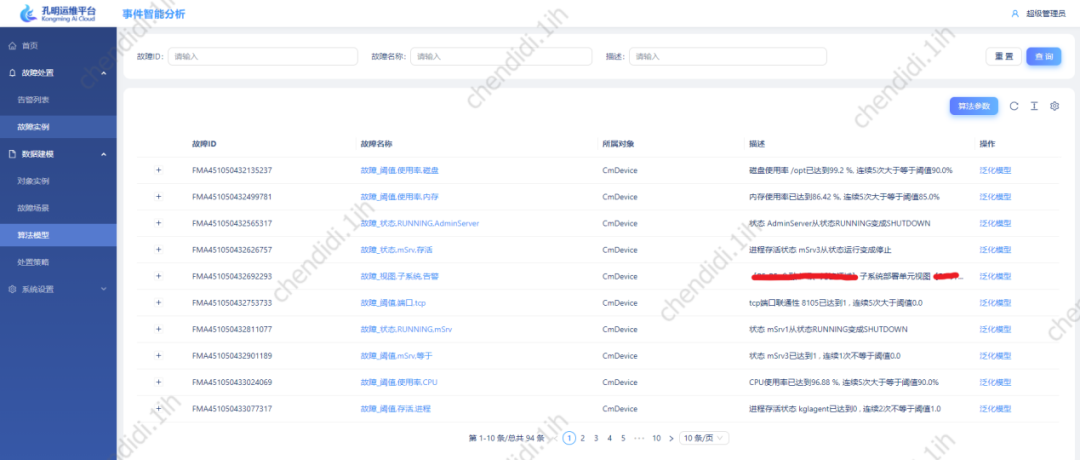 Picture
Picture
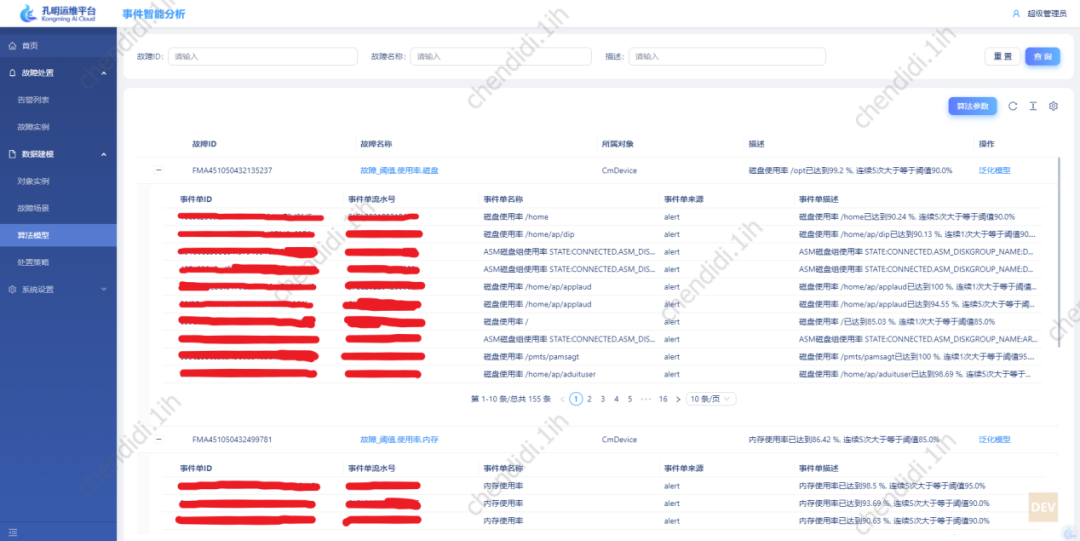 ##Picture
##Picture
 Picture
Picture
The advantages of this algorithm are as follows:
1) Through historical and real-time alarm data, fault classification is automatically performed without supervision, and there is no need to establish a fault model, saving manpower;
2) For real-time alarms, the fault clustering process ensures real-time online updates without the need for regular calculations and model updates;
3) Alarms are automatically generated or associated with faults, which can be further correlated Corresponding emergency plans, and obtain fault analysis plans and treatment methods.
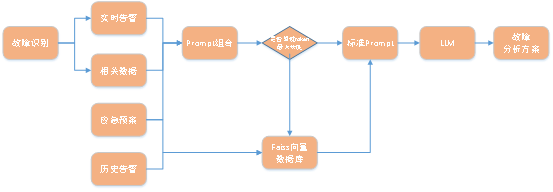
3. Automatically generate analysis plan
Review Chapter 3-2 Fault Analysis, the analysis of the fault, mainly It focuses on displaying the information of the fault node and surrounding nodes, and also requires more manual settings in the setting of the analysis decision tree.
After AI empowerment, consider using emergency plans, alarm details, and display information in fault analysis as prompts (prompts), and use existing large language models with excellent results to Automatically provide fault analysis solutions.
Considering the issue of privatized deployment, large language models can consider ChatGLM2, llama2, etc. In the specific implementation stage, different large language models can be selected according to needs and hardware levels. In the plan description of this article , LLM is used uniformly to represent large language models, please pay attention to the distinction.
The main process diagram is as follows:
 Picture
Picture
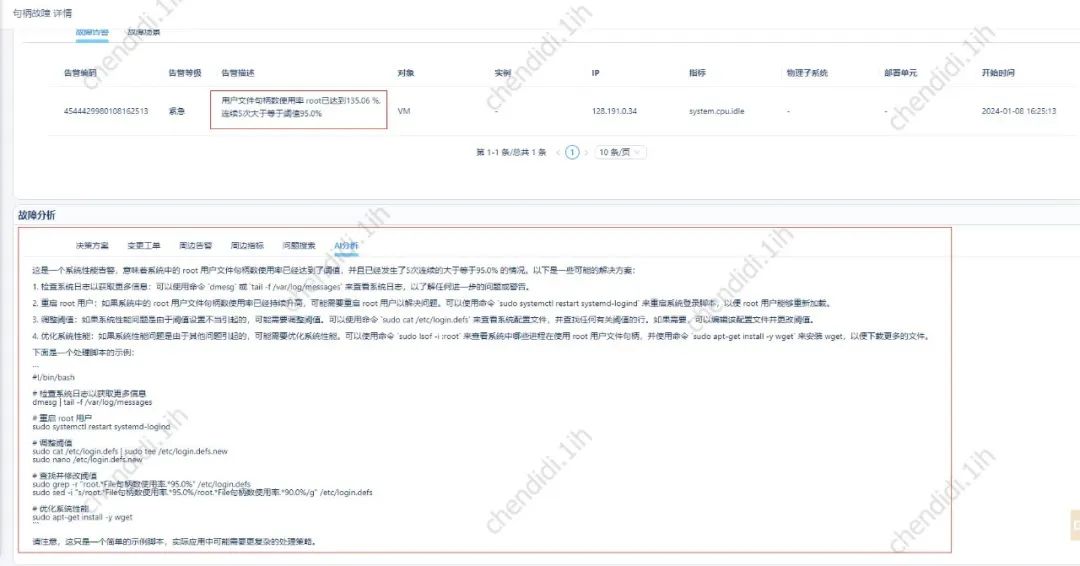 Picture
Picture
The above is the detailed content of Practical construction and application of AI-driven event intelligent analysis system. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



