


The image-to-video generation (I2V) task is a challenge in the field of computer vision that aims to convert static images into dynamic videos. The difficulty of this task is to extract and generate dynamic information in the temporal dimension from a single image while maintaining the authenticity and visual coherence of the image content. Existing I2V methods often require complex model architectures and large amounts of training data to achieve this goal.
Recently, a new research result "I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models" led by Kuaishou was released. This research introduces an innovative image-to-video conversion method and proposes a lightweight adapter module, the I2V-Adapter. This adapter module is capable of converting static images into dynamic videos without changing the original structure and pre-trained parameters of existing text-to-video generation (T2V) models. This method has broad application prospects in the field of image to video conversion, and can bring more possibilities to video creation, media communication and other fields. The release of the research results is of great significance for promoting the development of image and video technology, and provides an effective tool and method for researchers in related fields.

Relative to existing methods In other words, I2V-Adapter has made huge improvements in terms of trainable parameters, with the minimum number of parameters reaching 22M, which is only 1% of the mainstream solution Stable Video Diffusion. At the same time, the adapter is also compatible with customized T2I models (such as DreamBooth, Lora) and control tools (such as ControlNet) developed by the Stable Diffusion community. Through experiments, the researchers proved the effectiveness of I2V-Adapter in generating high-quality video content, opening up new possibilities for creative applications in the I2V field.

Temporal modeling with Stable Diffusion
Compared to image generation, video generation faces a unique challenge of modeling temporal coherence between video frames. Most current methods are based on pre-trained T2I models, such as Stable Diffusion and SDXL, by introducing timing modules to model the timing information in videos. Inspired by AnimateDiff, a model originally designed for customized T2V tasks, it models timing information by introducing a timing module decoupled from the T2I model, and retains the ability of the original T2I model to generate smooth videos . Therefore, the researchers believe that the pre-trained temporal module can be regarded as a universal temporal representation and can be applied to other video generation scenarios, such as I2V generation, without any fine-tuning. Therefore, the researchers directly used the pre-trained AnimateDiff timing module and kept its parameters fixed.
Adapter for attention layers
Another challenge in the I2V task is to maintain the ID information of the input image. There are two main current solutions: one is to use a pre-trained image encoder to encode the input image, and inject the encoded features into the model through a cross-attention mechanism to guide the denoising process; the other is to The image is concatenated with the noisy input in the channel dimension and then fed together into the subsequent network. However, the former method may cause the generated video ID to change because it is difficult for the image encoder to capture the underlying information; while the latter method often requires changing the structure and parameters of the T2I model, resulting in high training costs and poor compatibility.
In order to solve the above problems, researchers proposed I2V-Adapter. Specifically, the researcher inputs the input image and noised input to the network in parallel. In the spatial block of the model, all frames will additionally query the first frame information, that is, the key and value features come from the first frame without noise, and the output The result is added to the self attention of the original model. The output mapping matrix in this module is initialized with zeros and only the output mapping matrix and query mapping matrix are trained. In order to further enhance the model's understanding of the semantic information of the input image, the researchers introduced a pre-trained content adapter (this article uses IP-Adapter [8]) to inject the semantic features of the image.
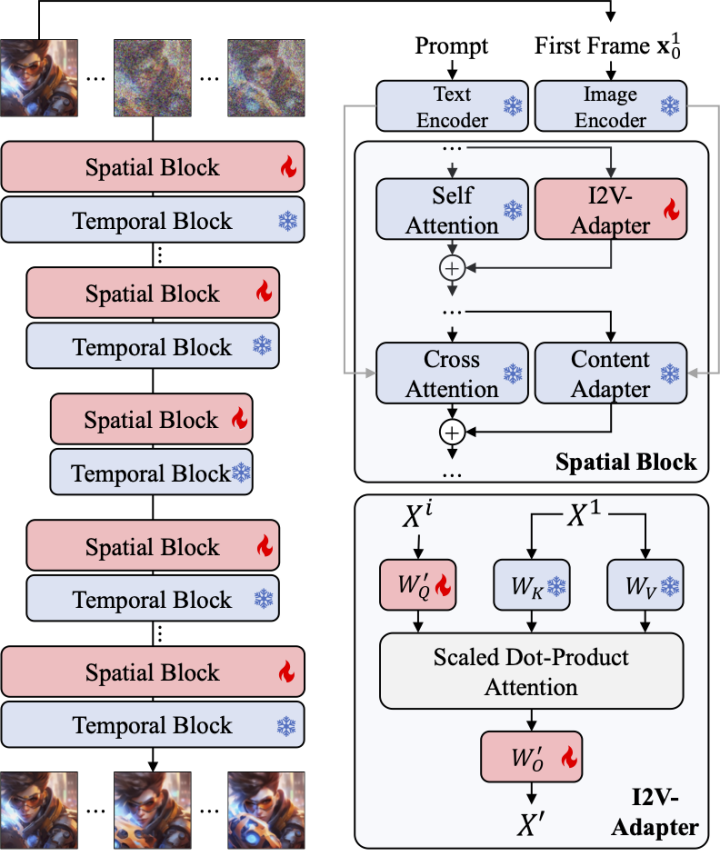
Frame Similarity Prior
In order to further enhance the stability of the generated results, the researcher proposed the frame Inter-similarity prior is used to strike a balance between the stability and motion intensity of the generated video. The key assumption is that at a relatively low Gaussian noise level, the noisy first frame and the noisy subsequent frames are close enough, as shown in the following figure:
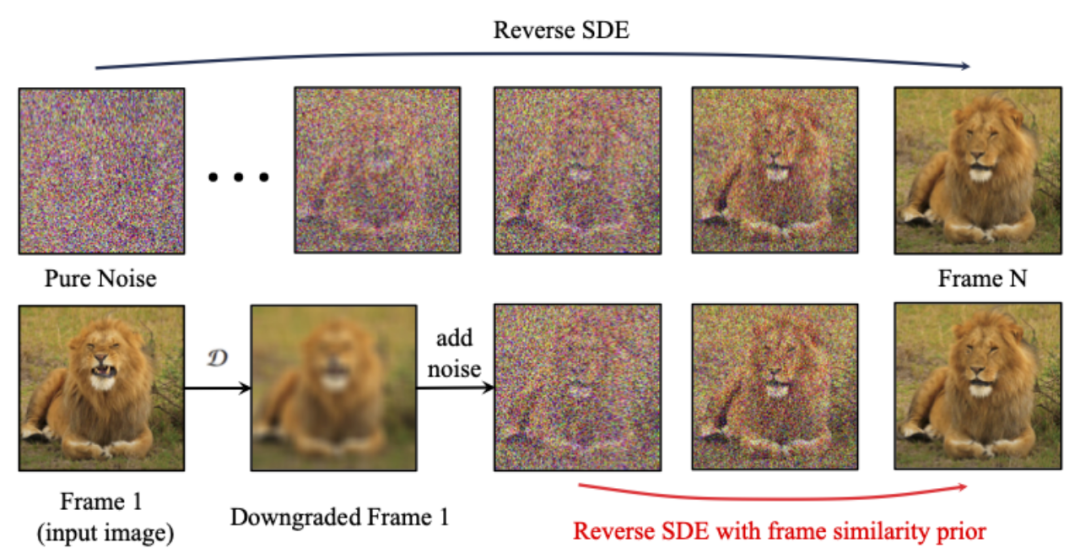
Therefore, the researcher assumes that all frames have similar structures and become indistinguishable after adding a certain amount of Gaussian noise. Therefore, the noisy input image can be used as a priori input for subsequent frames. In order to eliminate the misleading of high-frequency information, the researchers also used Gaussian blur operator and random mask mixing. Specifically, the operation is given by:

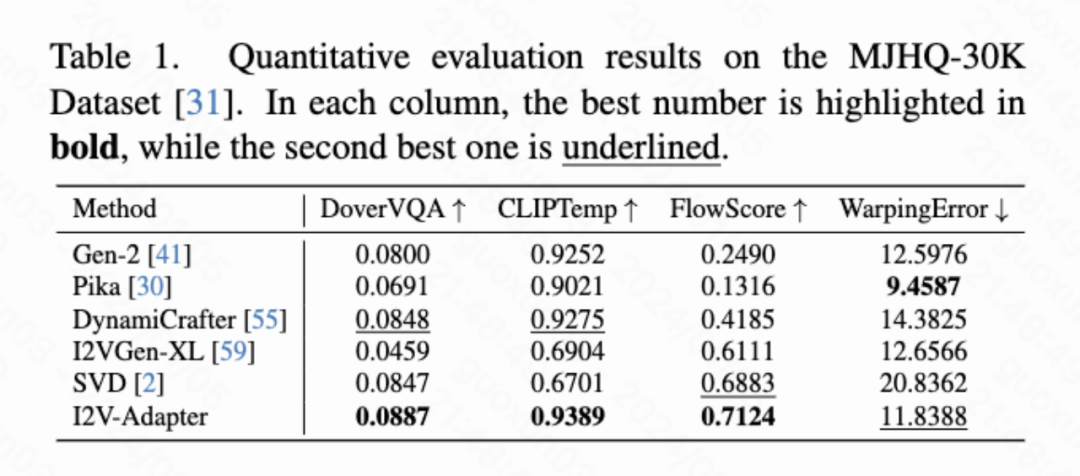
Quantitative Results
This article calculated four quantitative indicators: DoverVQA (aesthetic score), CLIPTemp (first frame consistency), FlowScore (motion range) and WarppingError (motion error) Used to evaluate the quality of generated videos. Table 1 shows that I2V-Adapter received the highest aesthetic score and also exceeded all comparison schemes in terms of first frame consistency. In addition, the video generated by I2V-Adapter has the largest motion amplitude and relatively low motion error, indicating that this model is able to generate more dynamic videos while maintaining the accuracy of temporal motion.
Qualitative results
Image Animation (left is input, right is Output):



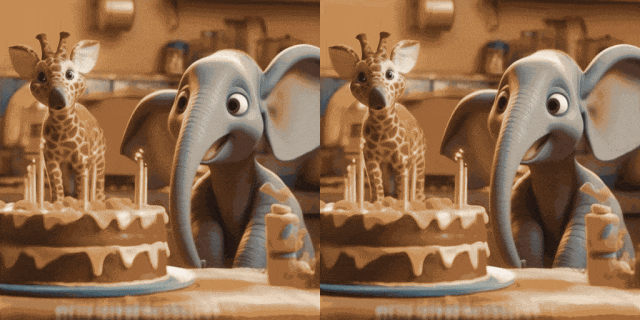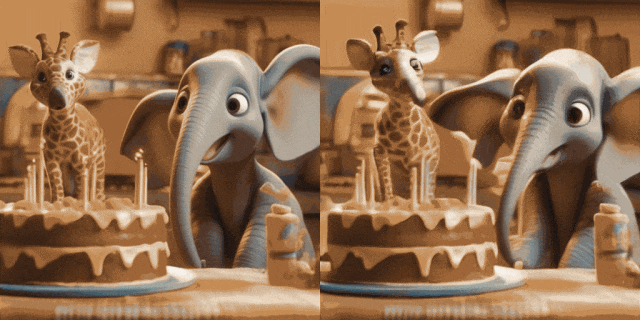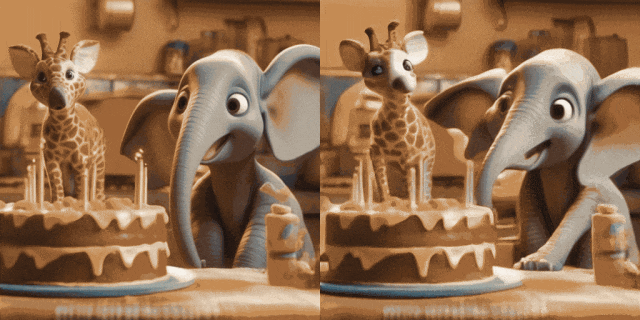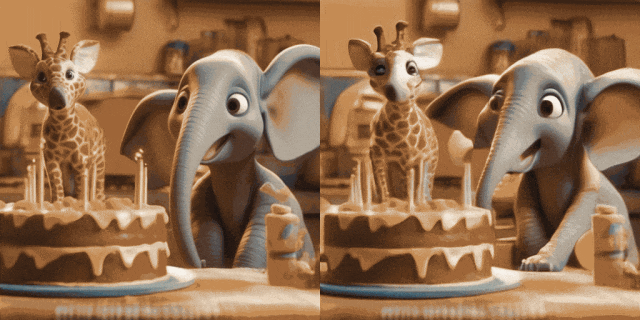
# #w/ Personalized T2Is (left is input, right is output):






This paper proposes I2V-Adapter, a plug-and-play lightweight module for image-to-video generation tasks. This method keeps the spatial block and motion block structures and parameters of the original T2V model fixed, inputs the first frame without noise and the subsequent frames with noise in parallel, and allows all frames to interact with the first frame without noise through the attention mechanism, thus Produce a video that is temporally coherent and consistent with the first frame. Researchers have demonstrated the effectiveness of this method on I2V tasks through quantitative and qualitative experiments. In addition, its decoupled design allows the solution to be directly combined with modules such as DreamBooth, Lora and ControlNet, proving the compatibility of the solution and promoting research on customized and controllable image-to-video generation.
The above is the detailed content of I2V-Adapter from the SD community: no configuration required, plug and play, perfectly compatible with Tusheng video plug-in. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



