


This new work from Apple will bring unlimited imagination to the ability to add large models to future iPhones.
In recent years, large language models (LLM) such as GPT-3, OPT, and PaLM have demonstrated strong performance in a wide range of natural language processing (NLP) tasks. However, achieving these performances requires extensive computational and memory inference because these large language models may contain hundreds of billions or even trillions of parameters, making it challenging to load and run efficiently on resource-constrained devices
The current standard solution is to load the entire model into DRAM for inference. However, this approach severely limits the maximum model size that can be run. For example, a 7 billion parameter model requires more than 14GB of memory to load parameters in half-precision floating point format, which is beyond the capabilities of most edge devices.
In order to solve this limitation, Apple researchers proposed to store model parameters in flash memory, which is at least an order of magnitude larger than DRAM. Then during inference, they directly and cleverly flash-loaded the required parameters, eliminating the need to fit the entire model into DRAM.
This approach builds on recent work that shows that LLM exhibits a high degree of sparsity in the feedforward network (FFN) layer, with models such as OPT and Falcon achieving sparsity exceeding 90%. Therefore, we exploit this sparsity to selectively load from flash memory only parameters that have non-zero inputs or are predicted to have non-zero outputs.

Paper address: https://arxiv.org/pdf/2312.11514.pdf
Specifically, the researchers discussed a hardware-inspired cost model that includes flash memory, DRAM, and compute cores (CPU or GPU). Then two complementary techniques are introduced to minimize data transfer and maximize flash throughput:
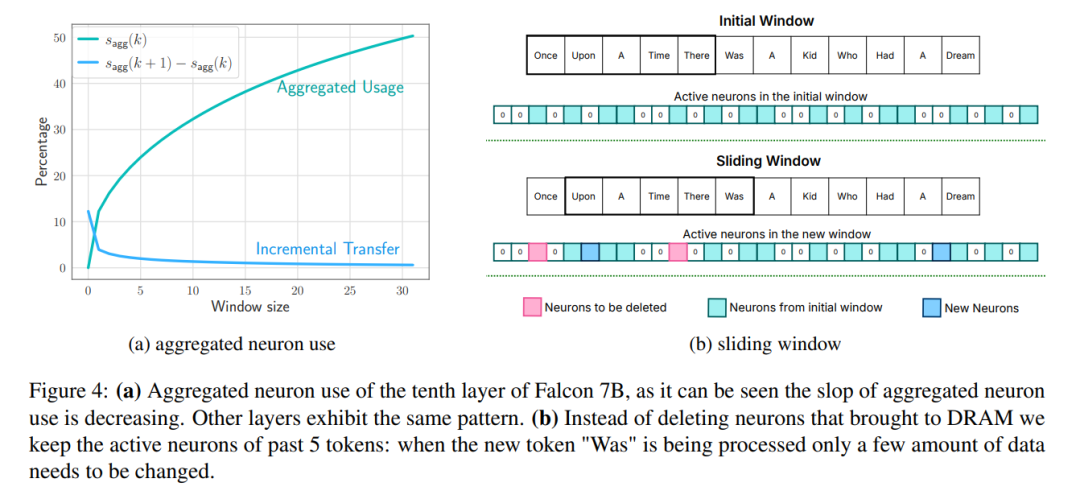
Window: only loads the parameters of the first few tags and reuses the activation of the most recently calculated tag. This sliding window approach reduces the number of IO requests to load weights;
Row and row bundling: stores concatenated rows and columns of up- and down-projection layers to read larger contiguous portions of flash memory piece. This will increase throughput by reading larger blocks.
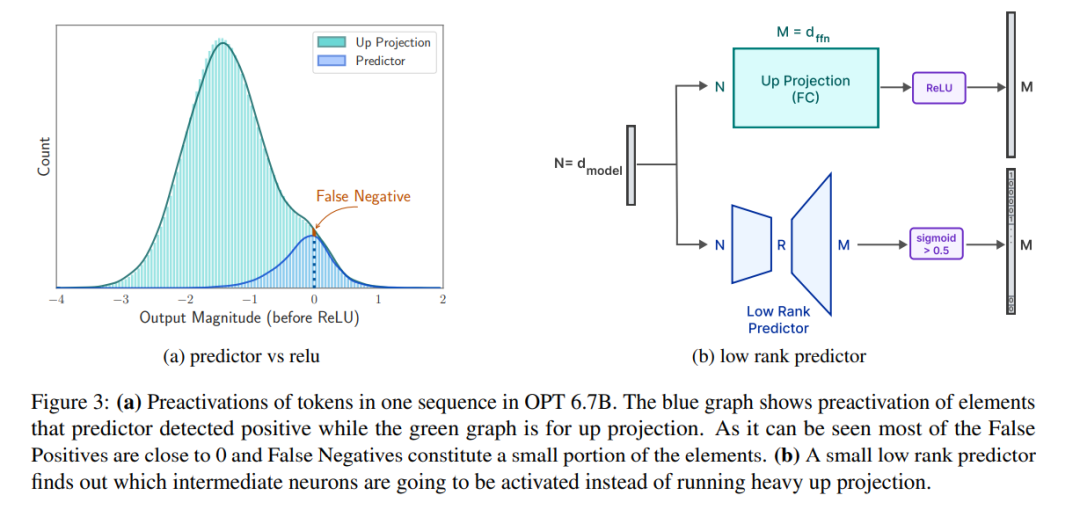
To further reduce the number of weights transferred from flash to DRAM, the researchers tried to predict the sparsity of FFN and avoid loading zeroing parameters. By using a combination of windowing and sparsity prediction, only 2% of the flash FFN layer is loaded per inference query. They also propose static memory pre-allocation to minimize intra-DRAM transfers and reduce inference latency
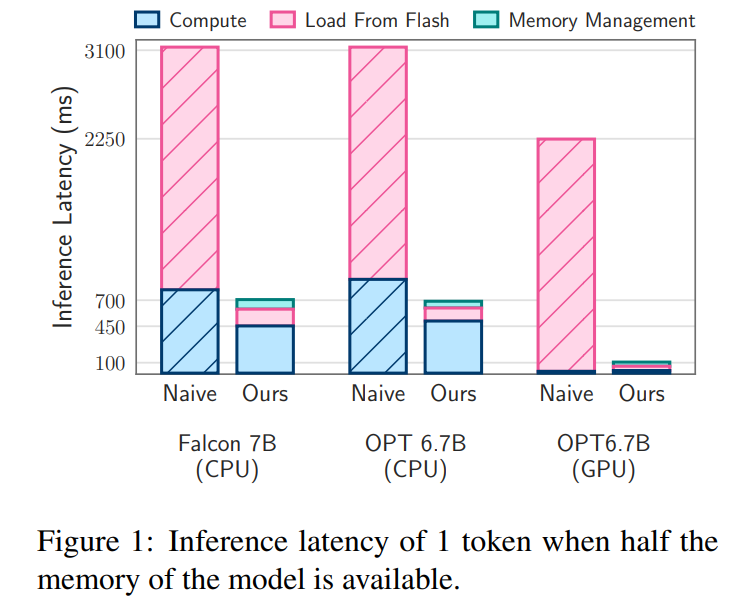
This paper’s flash load cost model strikes a balance between loading better data and reading larger blocks . A flash strategy that optimizes this cost model and selectively loads parameters on demand can run models with twice the DRAM capacity and improve inference speeds by 4-5x and 20-25x respectively compared to naive implementations in CPUs and GPUs. times.
Some people commented that this work will make iOS development more interesting.
Flash Memory and LLM Reasoning
Bandwidth and Energy Limitations
Although modern NAND flash memory provides high bandwidth and low latency, But it still falls short of DRAM performance levels, especially in memory-constrained systems. Figure 2a below illustrates these differences.
Naive inference implementations that rely on NAND flash may require reloading the entire model for each forward pass, a process that is time consuming and even compressing the model takes several seconds. Additionally, transferring data from DRAM to CPU or GPU memory requires more energy.
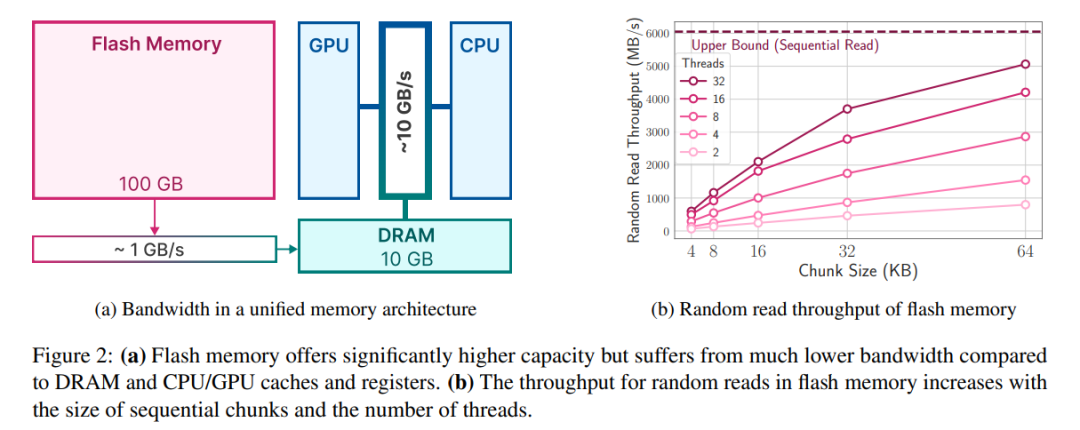
In scenarios where DRAM is sufficient, the cost of loading data is reduced, and the model can reside in DRAM. However, the initial loading of the model still consumes energy, especially if the first token requires fast response time. Our approach exploits activation sparsity in LLM to address these challenges by selectively reading model weights, thereby reducing time and energy costs.
Reexpressed as: Get data transfer rate
Flash systems perform best with large amounts of sequential reads. For example, the Apple MacBook Pro M2 is equipped with 2TB of flash memory, and in benchmark tests, the linear read speed of 1GiB of uncached files exceeded 6GiB/s. However, smaller random reads cannot achieve such high bandwidths due to the multi-stage nature of these reads, including the operating system, drivers, mid-range processors, and flash controllers. Each stage introduces latency, resulting in a larger impact on smaller read speeds
To circumvent these limitations, researchers advocate two main strategies, which can be used simultaneously.
The first strategy is to read larger data blocks. While the increase in throughput is not linear (larger data blocks require longer transfer times), the delay in initial bytes accounts for a smaller proportion of the total request time, making data reads more efficient. Figure 2b depicts this principle. A counter-intuitive but interesting observation is that in some cases, reading more data than needed (but in larger chunks) and then discarding it is faster than reading only what is needed but in smaller chunks .
The second strategy is to exploit the inherent parallelism of the storage stack and flash controller to achieve parallel reads. The results show that it is possible to achieve throughput suitable for sparse LLM inference using multi-threaded random reads of 32KiB or larger on standard hardware.
The key to maximizing throughput lies in how the weights are stored, as a layout that increases the average block length can significantly increase bandwidth. In some cases, it may be beneficial to read and subsequently discard excess data, rather than splitting the data into smaller, less efficient chunks.
Flash loading
Inspired by the above challenges, the researchers proposed a method to optimize the data transfer volume and improve the data transfer rate, which can be expressed as: To improve reasoning speed. This section discusses the challenges of performing inference on devices where the available computational memory is much smaller than the model size.
Analyzing this challenge requires storing complete model weights in flash memory. The primary metric used by researchers to evaluate various flash loading strategies is latency, which is divided into three different components: the I/O cost of performing the flash load, the memory overhead of managing the newly loaded data, and the computational cost of the inference operation.
Apple divides solutions for reducing latency under memory constraints into three strategic areas, each targeting a specific aspect of latency:
1. Reducing data load: Aiming to Load less data to reduce latency associated with flash I/O operations.
2. Optimize data block size: Improve flash throughput by increasing the size of the loaded data block, thereby reducing latency.
The following is the strategy used by researchers to increase data block size to improve flash read efficiency:
Bundle columns and rows
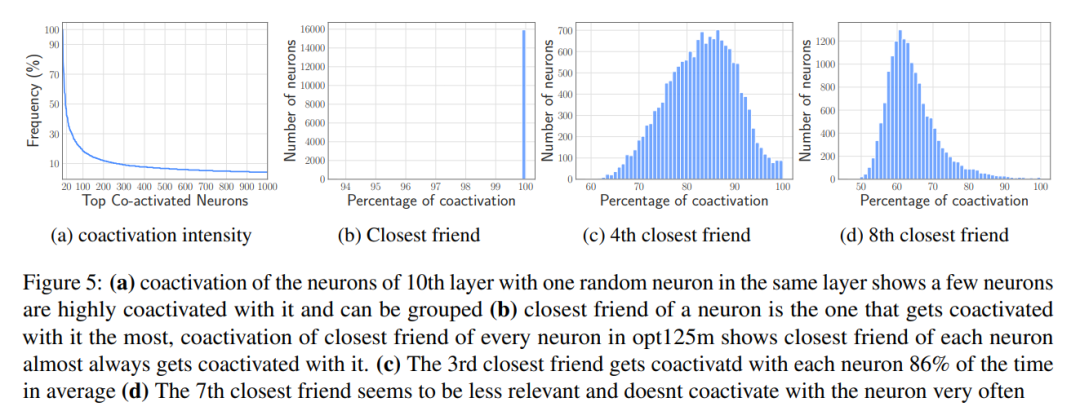
Co-activation-based bundling
3. Effective management of loaded data: Simplify the management of data after it is loaded into memory to maximize Reduce expenses significantly.
Although transferring data in DRAM is more efficient than accessing flash memory, it incurs a non-negligible cost. When introducing data for new neurons, re-allocating matrices and adding new matrices can incur significant overhead due to the need to rewrite existing neuron data in DRAM. This is especially costly when a large portion (~25%) of the feedforward network (FFN) in DRAM needs to be rewritten.
In order to solve this problem, the researchers adopted another memory management strategy. This strategy involves pre-allocating all necessary memory and establishing corresponding data structures for efficient management. As shown in Figure 6, the data structure includes elements such as pointers, matrices, offsets, used numbers, and last_k_active
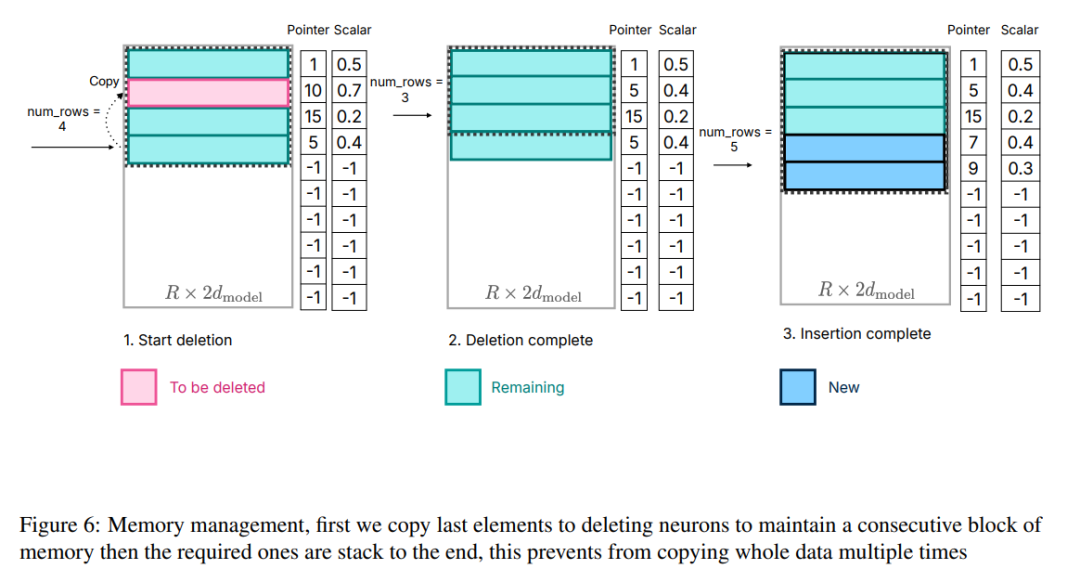
Figure 6: Memory Management , first copy the last element to the delete neuron to maintain the continuity of the memory block, and then stack the required elements to the end, which avoids copying the entire data multiple times.
It should be noted that the focus is not on the calculation process, because it has nothing to do with the core work of this article. This division allows researchers to focus on optimizing flash interaction and memory management to achieve efficient inference on memory-limited devices
requires rewriting of experimental results
OPT 6.7B Model Results
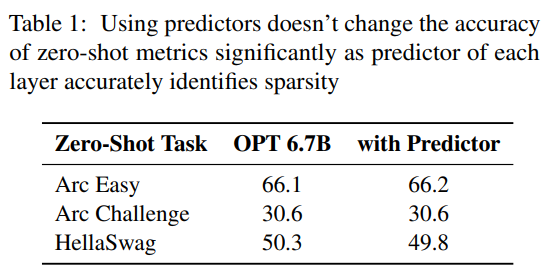
Predictor. As shown in Figure 3a, our predictor can accurately identify most activated neurons, but occasionally misidentifies non-activated neurons with values close to zero. It is worth noting that after these false negative neurons with close to zero values are eliminated, the final output result will not be significantly changed. Furthermore, as shown in Table 1, this level of prediction accuracy does not adversely affect the model's performance on the zero-shot task.
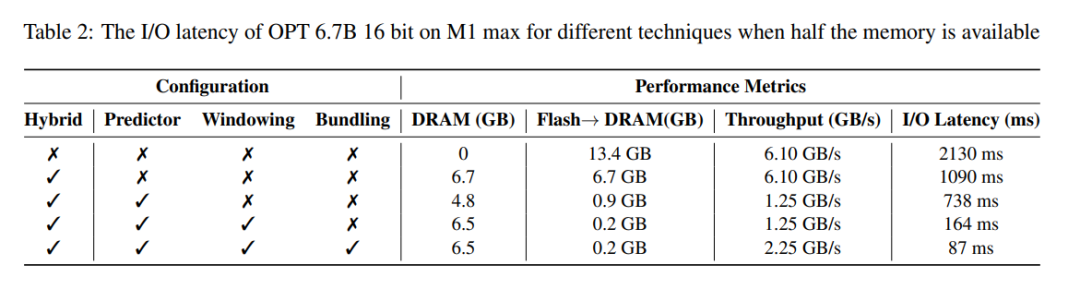
Delay analysis. When the window size is 5, each token needs to access 2.4% of the feedforward network (FFN) neurons. For the 32-bit model, the data block size per read is 2dmodel × 4 bytes = 32 KiB since it involves concatenation of rows and columns. On the M1 Max, the latency for flash loading per token is 125 milliseconds, and the latency for memory management (including deletion and addition of neurons) is 65 milliseconds. Therefore, the total memory-related latency is less than 190 milliseconds per token (see Figure 1). In comparison, the baseline approach requires loading 13.4GB of data at 6.1GB/s, resulting in a latency of approximately 2330 milliseconds per token. Therefore, our method is greatly improved compared to the baseline method.
For the 16-bit model on a GPU machine, flash load time is reduced to 40.5 milliseconds and memory management time is 40 milliseconds, with a slight increase in time due to the additional overhead of transferring data from the CPU to the GPU. Despite this, the I/O time of the baseline method is still over 2000 ms.
Table 2 provides a detailed comparison of the performance impact of each method.
Results for Falcon 7B model
Delay analysis. Using a window size of 4 in our model, each token needs to access 3.1% of the feedforward network (FFN) neurons. In the 32-bit model, this equates to a block size of 35.5 KiB per read (calculated as 2dmodel × 4 bytes). On an M1 Max device, flash loading this data takes about 161 milliseconds, and the memory management process adds another 90 milliseconds, so the total latency per token is 250 milliseconds. In comparison, with a baseline latency of about 2330 milliseconds, our method is approximately 9 to 10 times faster.
The above is the detailed content of Model inference acceleration: CPU performance is increased by 5 times. Apple uses flash memory for large-scale inference acceleration. Is Siri 2.0 about to debut?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



