



In daily life, OCR (Optical Character Recognition) technology is widely used in screenshot extraction and photo search. , this is a very important technology in the field of text recognition
OCR (Optical Character Recognition) is a computer text recognition method that uses optical and computer technology to convert printed or handwritten text images into an accurate and readable text format for computers. Identify and apply. OCR recognition technology is increasingly widely used in various industries of modern life. It is the key technology to quickly input text content into the computer
OCR technology is mainly divided into two schools: traditional OCR and deep learning OCR.
In the early days of the development of OCR technology, technicians used image processing techniques such as binarization, connected domain analysis and projection analysis, combined with statistical machine learning (such as Adaboost and SVM) to extract images We classify text content as traditional OCR. Its main feature is that it relies on complex data preprocessing operations to correct and reduce noise on the image. The importance of adaptability to complex scenes cannot be ignored. Adaptability is a critical capability in a changing environment. A person with good adaptability can adapt to new situations and requirements, adapt quickly to changes, and find solutions to problems. Adaptability is also one of the key factors for success in one's personal and professional life. Therefore, we should strive to cultivate and improve our adaptability to cope with a changing world with poor accuracy and response speed.
Thanks to the continuous development of AI technology, OCR technology based on end-to-end deep learning has gradually matured. The advantage of this method is that it does not need to explicitly introduce the text cutting link in the image pre-processing stage. It converts text recognition into a sequence learning problem and integrates text segmentation into deep learning, which is of great significance to the improvement of OCR technology and future development direction.
The traditional OCR technology processing flow chart is as follows:

Image preprocessing: The text image enters the preprocessing stage after being scanned by the device. Due to the existence of various text media Interfering factors, such as the smoothness and printing quality of the paper, the light and darkness of the screen, etc., will cause text distortion. Therefore, preprocessing methods such as brightness adjustment, image enhancement, and noise filtering are required for the image.
Text area positioning: For positioning and extraction of text areas, the methods mainly include connected domain detection and MSER detection.
Text image correction: Correct slanted text to ensure it is horizontal. Correction methods mainly include horizontal correction and perspective correction.
Line and row single character segmentation: Traditional text recognition is based on single character recognition. The segmentation method mainly uses connected domain contours and vertical Projection cutting.
Classifier character recognition: Use feature extraction algorithms such as HOG and Sift to extract vector information from characters, and use SVM algorithm and logistic regression , support vector machine, etc. for training.
Post-processing: Since the classification of the classifier may not be completely correct, or there may be errors in the character cutting process, it needs to be based on statistics A language model (such as a hidden Markov chain, HMM) or a language rule model designed by human extraction rules to perform semantic error correction on the text results.
 Picture
Picture
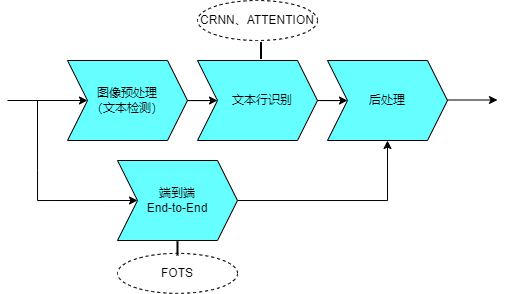
The current mainstream deep learning OCR The algorithm models the two stages of text detection and text recognition separately.
Text detection can be divided into regression-based and segmentation-based methods. Regression methods include algorithms such as CTPN, Textbox, and EAST, which can detect directional text in images, but will be affected by irregularities in the text area. Segmentation methods such as the PSENet algorithm can handle text of various shapes and sizes, but closer text is prone to sticking problems. Different methods have their own advantages and disadvantages
The text recognition stage mainly uses two major technologies, CRNN and ATTENTION, to transform text recognition into a sequence learning problem. The two technologies are in their feature learning stage Both use the network structure of CNN RNN. The difference lies in the final output layer (translation layer), that is, how to convert the sequence feature information learned by the network into the final recognition result.
In addition, there is a latest end-to-end algorithm that directly integrates text detection and text recognition into a single network model for learning. For example, algorithms such as FOTS and Mask TextSpotter. Compared with independent text detection and text recognition methods, this algorithm has faster recognition speed but weaker relative accuracy
#Traditional identification |
Artificial intelligence deep learning recognition technology |
|
|
Underlying layer Algorithm |
Text detection and recognition are divided into multiple stages and sub-processes, using different algorithm combinations |
The goal of this model is to fuse the detection and recognition processes to achieve end-to-end |
| ##Stability
|
The overall stability of multiple stages is poor
|
After the end With end-to-end optimization, the stability of the system has been significantly improved
|
| Identification Accuracy
|
Traditional scenarios with small samples have certain advantages when the accuracy is not high
|
The accuracy is higher, the deeper the degree of fusion, the accuracy gradually decreases
|
|
speed
| Slower recognition||
|
Scenario The importance of adaptability cannot be ignored. Adaptability is a critical capability in a changing environment. A person with good adaptability can adapt to new situations and requirements, adapt quickly to changes, and find solutions to problems. Adaptability is also one of the key factors for success in one's personal and professional life. Therefore, we should strive to cultivate and improve our adaptability to cope with the ever-changing world |
Weak, applicable standard printing format |
Strong, compatible with complex scenarios, dependent on model training |
Anti-interference ability |
Weak, higher requirements for input images |
##Strong, dependent on model training |
Recall rate: refers to the ratio of the number of characters correctly recognized by the OCR system to the actual number of characters. It is used to measure whether the system has missed recognizing some characters. The higher the value, the better the system's ability to cover characters.
Accuracy rate: refers to the ratio of the number of characters correctly recognized by the OCR system to the total number of characters recognized by the system. It is used to measure how many of the recognition results of the system are truly correct. The higher the value, the more reliable the recognition results of the system are.
F1 value: A comprehensive evaluation index of recall rate and precision rate. The F1 value is between 0 and 1. The higher the value, the better the system is between precision rate and recall rate. A better balance has been achieved.
Average Edit Distance (Average Edit Distance) is an indicator used to evaluate the degree of difference between OCR recognition results and real text
OCR, as one of the main branches in the field of text recognition, still has a broad research direction and development space in the future. . In terms of recognition accuracy, it is still urgent to study smarter image processing technology and more powerful deep learning models; it requires recognition to be more universal in covering multiple languages and fonts, and to enhance the ability to adapt to complex scenes; in real-time recognition In terms of technology, we are looking for more application points that are combined with virtual reality technology and augmented reality technology, such as AR translation, automatic error correction of text data, and data correction.
The above is the detailed content of Explore the principles and application scenarios of OCR recognition. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Introduction to the usage of vbs whole code
Introduction to the usage of vbs whole code
 What are the differences between Eclipse version numbers?
What are the differences between Eclipse version numbers?
 cdn server security protection measures
cdn server security protection measures
 How to undo after gitcommit
How to undo after gitcommit
 microsoft project
microsoft project
 Recommended hard drive detection tools
Recommended hard drive detection tools








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



