



Re-formatted| It’s Hu Haozhe, a master’s student
 Paper link: https://doi.org/10.1007/s10489-023-05048-8
Paper link: https://doi.org/10.1007/s10489-023-05048-8
When tested on three major reaction prediction data sets, testing on the retrosynthetic and forward reaction prediction tasks, and comprehensive ablation experiments on the above modules, we demonstrate that BiG2S is able to handle both retrosynthetic and forward reactions with a single model at appropriate parameter scales. Response prediction task. Compared with existing template-free methods based on pre-training and data enhancement, the overall prediction ability of BiG2S is equally excellent
Research backgroundRetrosynthesis and forward Synthesis is a fundamental challenge in the fields of organic chemistry, computer-aided synthesis planning (CASP), and computer-aided drug design (CADD)When rewriting the content, the original text needs to be rewritten into Chinese while maintaining the original meaning.
Early retrosynthetic planning systems directly relied on reaction rules pre-coded by domain experts, or calculations based on physical chemistry, but with the rapid development of deep learning. The current mainstream method in the field is to build a task-specific neural network framework to complete the reaction prediction task from a data-driven perspective. Among them, the template-free method, which does not rely on specific prior chemical knowledge, has gradually become one of the mainstream development directions in the field through its simplicity and flexibility similar to end-to-end machine translation.
Currently, the input and output of most template-free retrosynthetic models are SMILES strings of molecules, that is, using the sequence-to-sequence (Seq2Seq) process. This method can make good use of the existing model framework in the field of natural language processing, as well as the mature data processing flow for the SMILES representation method
However, since SMILES as a one-dimensional string sequence cannot be easily To better characterize and utilize the two-dimensional/three-dimensional structural information contained in molecular graphs, the graph-to-sequence (Graph2Seq) method that uses molecular graphs instead of SMILES as model input has gradually emerged in this field, or the additional structural information of molecular graphs has gradually emerged. Sequence-to-sequence methods embedded in SMILES sequences. Both methods can make good use of the rich structural features from molecular graphs
Based on this, this paper is based on the emerging graph-to-sequence method and combines retrosynthesis and forward reaction in the original SMILES-based model. Based on the related exploration benchmark of simultaneous training of prediction tasks, we further comprehensively explore the construction and experiment of this type of dual-task model, and also preliminarily explore and analyze the difficulty imbalance and Top-k matching displayed by the model during the training process. The problem of rate fluctuation; the BiG2S model built on this basis can better handle the retrosynthesis and forward reaction prediction tasks in mainstream data sets, and achieve results consistent with other template-free retrosynthesis models without using data enhancement. Response prediction ability
The overall framework needs to be rewrittenThe overall structure of BiG2S is an end-to-end encoder-decoder, as shown in Figure 1. The encoder side uses a local directed message passing graph network and a global graph Transformer that incorporates graph structure bias information to generate the final molecular graph node representation. The decoder uses a standard Transformer decoder to generate the SMILES sequence of the target molecule in an autoregressive mannerIt should be noted that in order to learn retrosynthesis and forward reaction prediction at the same time, the input to the decoder additionally contains Dual-task labeling of location information. At the same time, the normalization layer and the final linear layer on the decoder side have two sets of parameters, which are used to learn the retrosynthesis task and the forward reaction prediction task respectively
Figure 1: BiG2S overall framework diagram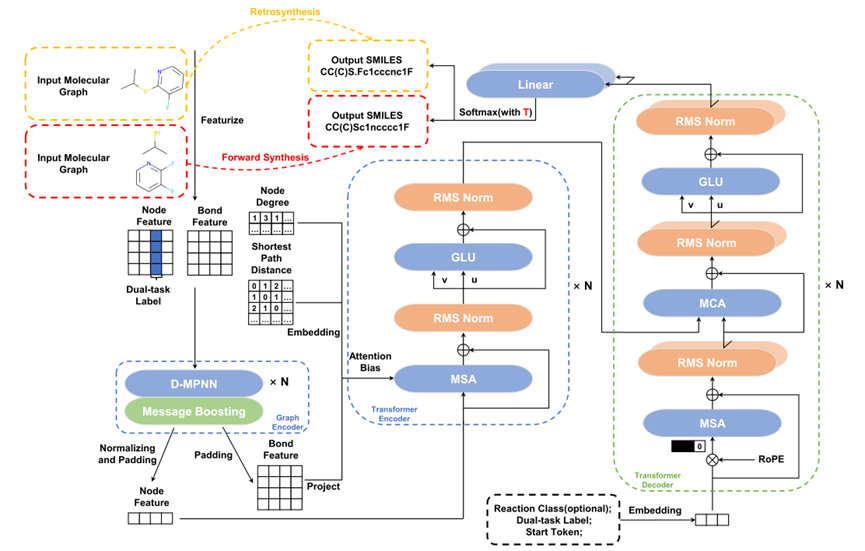
Retrosynthesis and forward reaction prediction are two related tasks. The retrosynthesis task uses products as input and reactants as target output, while the forward reaction prediction task does the opposite. There is a close connection between these two tasks, as they can be transformed into a forward reaction prediction task by exchanging the input and target output of the retrosynthesis task
Therefore, some template-free models based on SMILES have An attempt was made to improve the understanding of chemical reactions by using reverse synthesis and forward reaction prediction as training objectives, and achieved certain results. Based on this idea, the author further tried to introduce dual-task training into the graph-to-sequence model
Specifically, the author based on the parameter sharing strategy previously used on other methods, in the normalization layer of the decoder and Two sets of task-specific parameters are constructed within the final linear layer. In other modules, the two types of tasks share a set of parameters. At the same time, additional dual-task labels are added to the input molecular graph nodes and the initial input sequence of the decoder. In this way, even while controlling the overall model size, the model is able to distinguish between the two types of tasks and learn their different data distributions
Requires training and inference optimization
In During the training process, the author further recorded and analyzed two types of problems reflected by the model during the training process
First, the author recorded the frequency of occurrence of different SMILES characters in USPTO-50k and their corresponding ones during training The prediction accuracy is shown in Figure 2. During the training process, for S and Br, which accounted for 0.4% and 0.3% respectively in the training set, the absolute difference in overall prediction accuracy reached 8%. This initially shows that there are obvious differences in the difficulty of prediction between different molecular structures/fragments. Therefore, the author alleviates such problems by introducing an unbalanced loss function (such as Focal Loss), so that the model can pay more attention to the accuracy during training. Lower molecular fragments
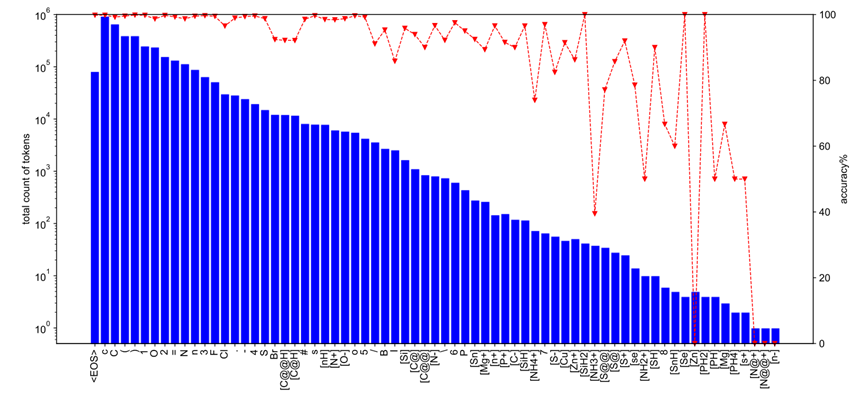
Figure 2: In the USPTO-50k training set, the frequency of occurrence of different SMILES characters and their overall prediction accuracy during training
In addition, the author also recorded the quality changes of the model's prediction results on the validation set during training, as shown in Figure 3. The author found that in the middle and late training stages of the USPTO-50k data set, the Top-1 accuracy of the model on the validation set was still improving, but there was a decline in the prediction quality of Top-3, Top-5, and Top-10 Significant decrease
In order to improve the top-1 prediction quality of the model while maintaining the overall quality of the model's top ten reactant generation results, we additionally constructed a type of model integration strategy based on custom evaluation indicators. Specifically, we build a queue to store models and sort the stored models according to predefined evaluation indicators (such as Top-1 accuracy, weighted Top-k accuracy, etc.). Throughout the training process, we dynamically store candidate models and automatically generate ensemble models based on the top 3-5 in the queue, thereby retaining the Top-k models with the highest prediction quality. In the inference stage, we also rebuilt a beam search strategy based on the new framework that focuses more on search breadth to improve the overall quality of the results generated by the model Top-k
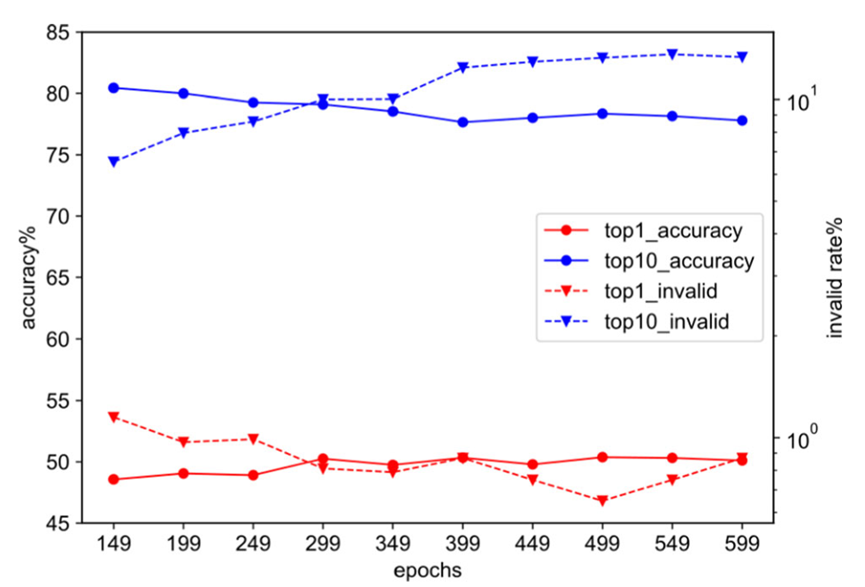
Requires a benchmark data set for dual-task experiments
The author conducted experiments in the retrosynthesis task and the forward reaction prediction task, using the data sets USPTO-50k and USPTO-MIT containing 50,000, 500,000, and 1 million chemical reaction data. , USPTO-full. In the experiment, the performance of the dual-task model and the single-task model were compared. According to the test results in Figure 4,
In the small-scale data set, BiG2S achieved leading prediction accuracy in the retrosynthesis task based on dual-task training, while also maintaining a high forward reaction prediction accuracy; however, In the USPTO-MIT data set that is biased towards forward response prediction and the large-scale data set USPTO-full, due to the limitation of the overall parameter amount of the model, the performance of the model after dual-task training has decreased. Nonetheless, the ability to simultaneously process the retrosynthesis task and the forward reaction prediction task was obtained from the dual-task model with almost the same number of parameters and a small reduction in response prediction ability (the absolute difference in Top-k accuracy is around 0.5%). From the perspective of capabilities, the BiG2S model has achieved the expected goals
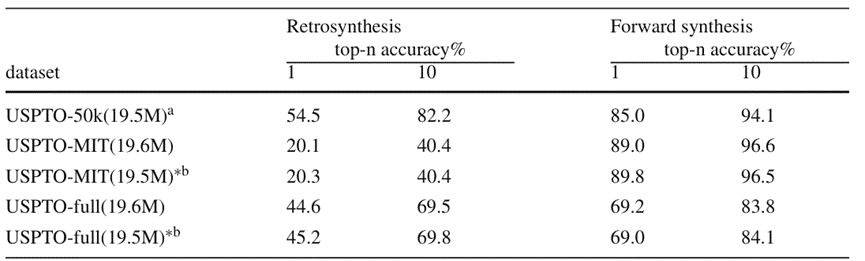
Reanalyze the ablation experiment
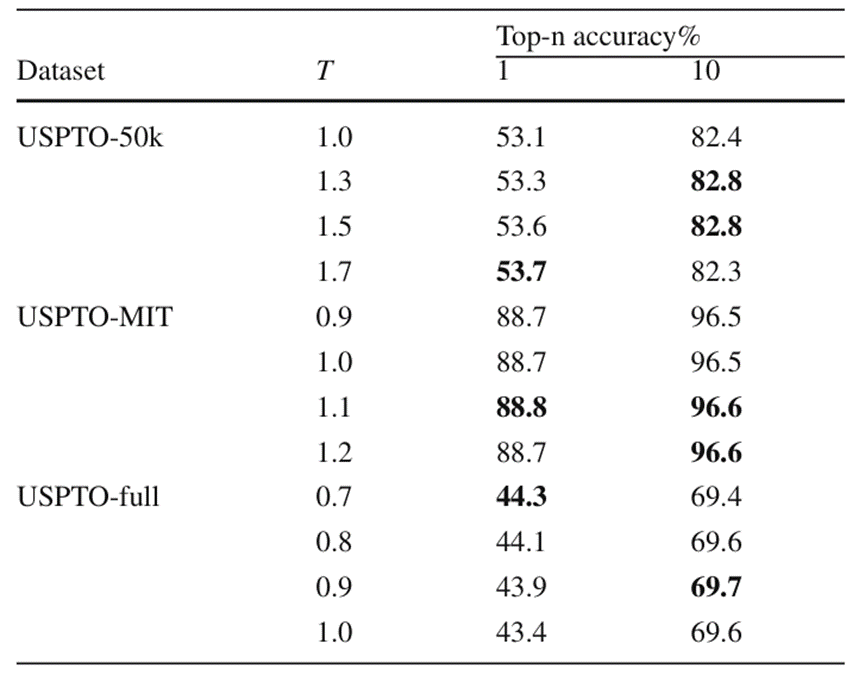
The author further verified the new beam search algorithm and the optimal temperature hyperparameters of BiG2S when predicting in different data sets after using imbalance loss through ablation experiments. The temperature hyperparameter here refers to the temperature parameter T used in Softmax to control the output probability distribution. The experimental results are shown in Figure 5 and Figure 6
In the experiment on the beam search algorithm, it can be observed that OpenNMT expanded the search width to 3 times while the search time only expanded to 1.74 times, while the new When the top-1 accuracy of the beam search algorithm is consistent with OpenNMT, the overall search time increases by 1-2 times; but in terms of the quality of the top-10 prediction results, the new beam search algorithm has at least 3% improvement compared to OpenNMT. The absolute accuracy advantage and the effective molecule proportion advantage of 2%. It can be said that the new beam search algorithm has significantly improved the quality of the overall Top-k search results of the model at the cost of search time.
In terms of temperature When conducting experiments on hyperparameters, the researchers found that using larger temperature parameters on small-scale data sets can significantly improve the overall Top-k prediction accuracy. In larger data sets, since the BiG2S model size cannot fully adapt to all reaction data, choosing smaller temperature parameters at this time often helps model search

The conclusion of the study shows...
In this article, the author proposes a template-free reaction prediction model called BiG2S, which can handle both retrosynthesis tasks and forward reaction prediction tasks. By adopting appropriate parameter sharing strategies and additional dual-task labels, BiG2S can complete retrosynthesis tasks and reaction prediction tasks on data sets of different sizes with a smaller number of parameters, and its overall prediction ability is comparable to mainstream models
In order to solve the problem of uneven prediction difficulty of different SMILES characters and fluctuation of Top-k prediction accuracy in model training, the author introduced imbalance loss, automatic model integration strategy based on custom evaluation indicators and beam search algorithm based on new framework To alleviate these problems
BiG2S has shown good dual-task prediction capabilities on three mainstream data sets of different sizes, and further ablation experiments also proved the effectiveness of the additionally introduced training and inference strategies. sex
The above is the detailed content of End-to-end template-free response prediction model based on dual tasks. For more information, please follow other related articles on the PHP Chinese website!
 Computer 404 error page
Computer 404 error page
 Solution to the Invalid Partition Table prompt when Windows 10 starts up
Solution to the Invalid Partition Table prompt when Windows 10 starts up
 How to solve the problem of missing ssleay32.dll
How to solve the problem of missing ssleay32.dll
 How to set IP
How to set IP
 How to open state file
How to open state file
 Why is the mobile hard drive so slow to open?
Why is the mobile hard drive so slow to open?
 What are the basic units of C language?
What are the basic units of C language?
 What platform is Kuai Tuan Tuan?
What platform is Kuai Tuan Tuan?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



