



The 19th century was the period when the Impressionism art movement flourished, which was influential in the fields of painting, sculpture, printmaking and other arts. Impressionism was characterized by the use of short, staccato brushstrokes with little pursuit of formal precision, which later evolved into the Impressionist art style. In short, the impressionist artist's brushstrokes are unmodified, showing obvious characteristics, not pursuing formal precision, and even being somewhat vague. Impressionist artists introduced the scientific concepts of light and color into paintings and revolutionized traditional color concepts.
In D3GA, the author has a unique goal. He hopes to create a photo-realistic performance effect by doing the opposite. In order to achieve this goal, the author creatively used Gaussian splattering technology in D3GA as a modern "segment brushstroke" to build the structure and appearance of virtual characters and achieve real-time and stable Effect.

"Sunrise·Impression" is the representative work of the famous Impressionist painter Monet.

## In order to create realistic human figures that can generate new content for animation, the construction of avatars currently requires a lot of work multi-view data. This is because monocular methods have limited accuracy. In addition, existing techniques require complex pre-processing, including accurate 3D registration. However, obtaining these registration data requires iteration and is difficult to integrate into an end-to-end process. In addition, there are methods that do not require accurate registration and are based on neural radiation fields (NeRFs). However, these methods are often slow at real-time rendering or have difficulty with clothing animation.
Kerbl et al. proposed a rendering method called 3D Gaussian Splatting (3DGS), which is improved on the basis of the classic Surface Splatting rendering method. Compared with state-of-the-art methods based on neural radiation fields, 3DGS is able to render higher quality images at faster frame rates and without the need for highly accurate 3D initialization.
However, 3DGS was originally designed for static scenes. At present, some people have proposed the Gaussian Splating method based on time conditions, which can be used to render dynamic scenes. This method can only play back what has been previously observed and is therefore not suitable for expressing new or previously unseen motion.
Based on the driven neural radiation field, the author models the appearance and deformation of 3D humans, placing them in a standardized space, but using 3D Gaussian rather than a radiation field. In addition to better performance, Gaussian Splatting eliminates the need to use the camera ray sampling heuristic.
The remaining problem is to define the signals that trigger these cage deformations. Current state-of-the-art technologies in driver-driven avatars require dense input signals, such as RGB-D images or even multiple cameras, but these methods may not be suitable for situations where transmission bandwidth is relatively low. In this study, the authors employ more compact input based on human poses, including skeletal joint angles and 3D facial keypoints in the form of quaternions.
By training individual-specific models on nine high-quality multi-view sequences, covering a variety of body shapes, movements, and clothing (not limited to intimate clothing), we can later The new posture of any subject drives the figure.
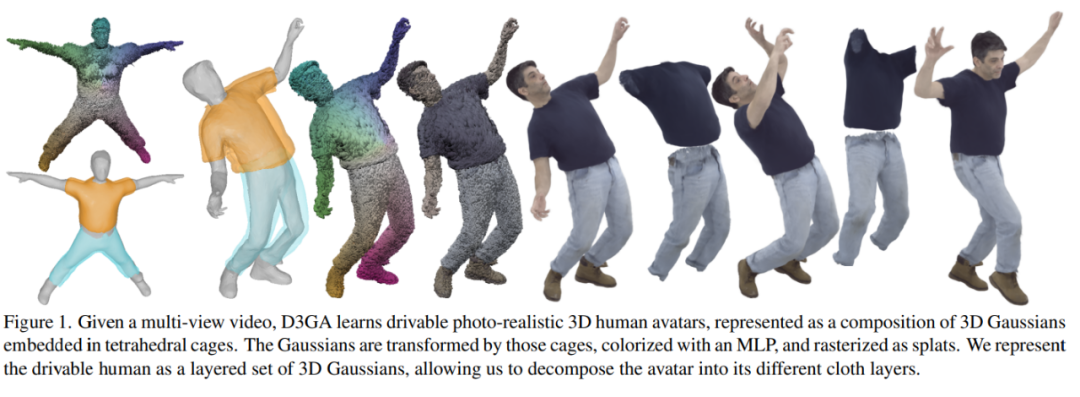


Current methods for dynamically volumetricizing virtual characters either map points from deformation space to canonical space, Or just rely on forward mapping. Methods based on back mapping tend to accumulate errors in the canonical space because they require an error-prone back pass and are problematic in modeling perspective-dependent effects.
Therefore, the author decided to adopt a forward mapping only method. D3GA is based on 3DGS and extended through neural representation and cage to model the color and geometric shape of each dynamic part of the virtual character respectively.
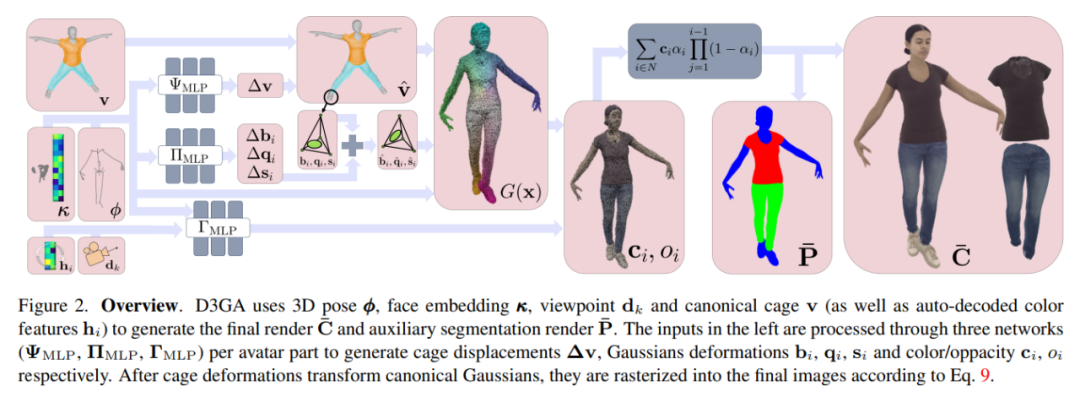
D3GA uses 3D pose ϕ, face embedding κ, viewpoint dk and canonical cage v (and automatically decoded color features hi) to generate the final Render C¯ and auxiliary segmentation render P¯. The input on the left is processed through three networks (ΨMLP, ΠMLP, ΓMLP) per virtual character part to generate cage displacement Δv, Gaussian deformations bi, qi, si, and color/transparency ci, oi.
After the cage deformation deforms the canonical Gaussian, they are rasterized into the final image via Equation 9.
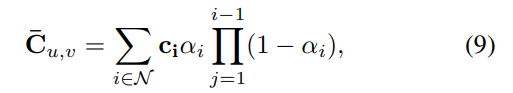
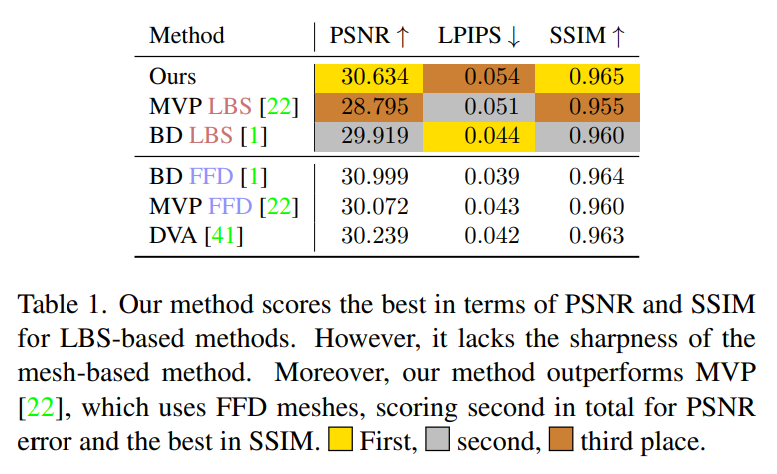
##D3GA in SSIM, PSNR and perceptual metric LPIPS Evaluate on other indicators. Table 1 shows that D3GA has the best performance in PSNR and SSIM among methods that only use LBS (that is, there is no need to scan 3D data for each frame), and outperforms all FFD methods in these indicators, second only to for BD FFD, despite its poor training signal and no test images (DVA was tested using all 200 cameras).
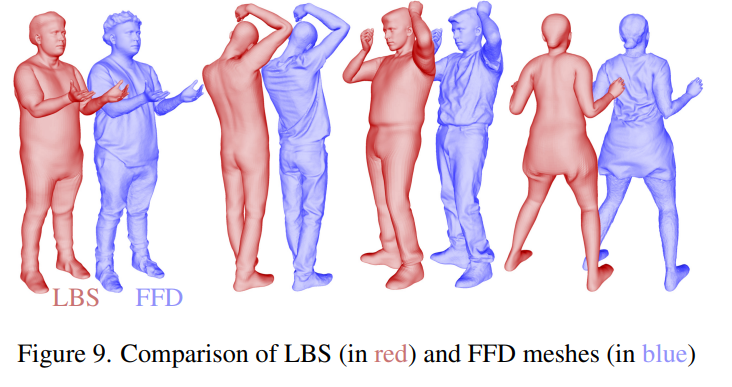
Qualitative comparison shows that D3GA can model clothing better than other state-of-the-art methods, especially Loose-fitting clothing like a skirt or sweatpants (picture 4). FFD stands for Free Deformation Mesh, which contains richer training signals than LBS meshes (Figure 9).

The above is the detailed content of Can AI research also learn from Impressionism? These lifelike people are actually 3D models. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



