



December 29 news, the reach of large language models (LLM) has expanded from simple natural language processing to multi-modal fields such as text, audio, video, etc. One of the keys is video timing positioning (Video Grounding, VG).
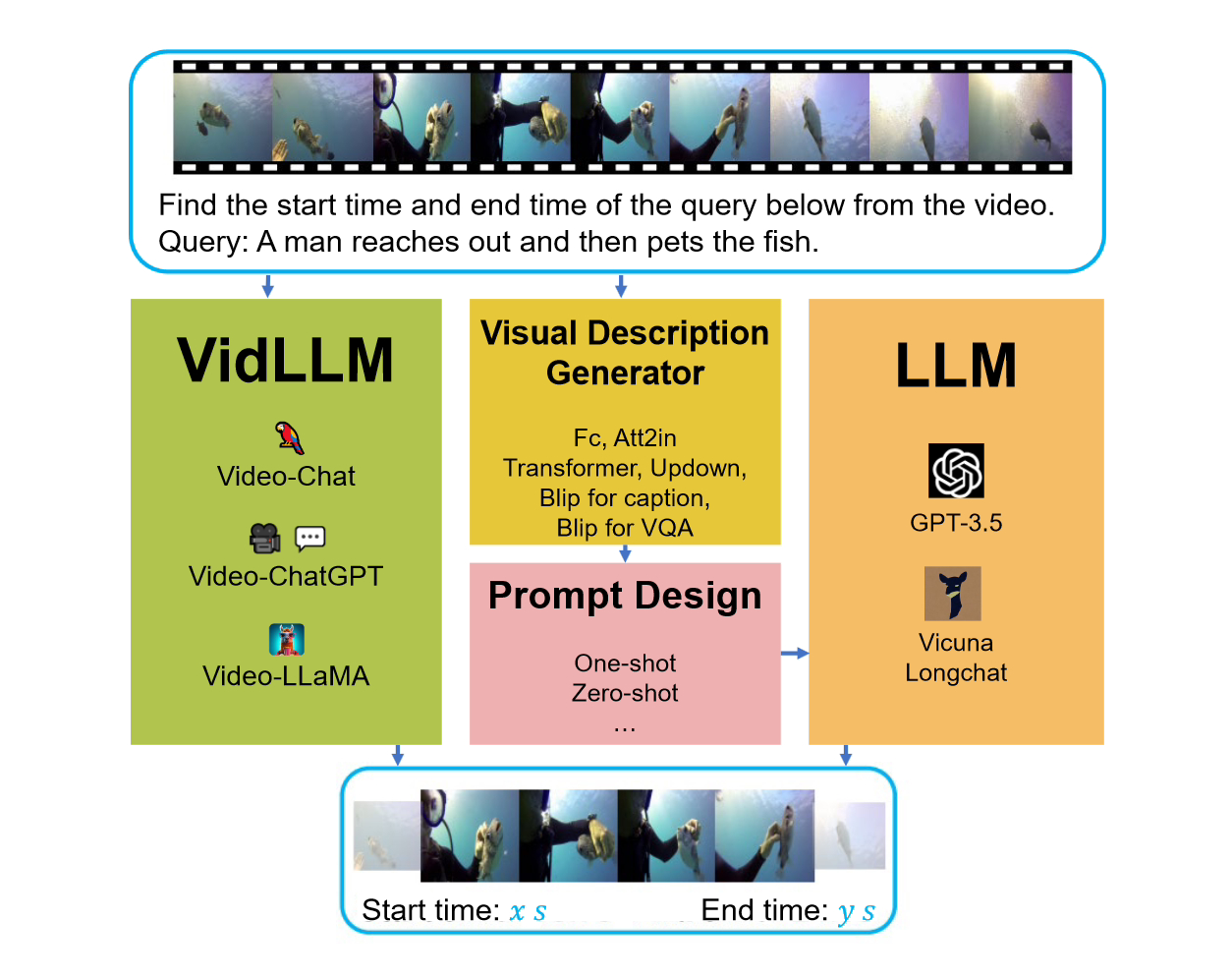
The goal of the VG task is to locate the start and end time of the target video segment based on the given query. The core challenge of this task is to accurately determine the time boundaries.
The Tsinghua University research team recently launched the “LLM4VG” benchmark, which is specially designed to evaluate the performance of LLM in VG tasks.
When considering this benchmark, two main strategies were considered. The first strategy is to train a video language model (LLM) directly on the text video dataset (VidLLM). This method learns the association between video and language by training on a large-scale video data set to improve the performance of the model. The second strategy is to combine a traditional language model (LLM) with a pre-trained vision model. This method is based on a pre-trained visual model that combines the visual characteristics of the video. In one strategy, the VidLLM model directly processes the video content and VG task instructions, and performs Its training output predicts text-video relationships.
The second strategy is more complex and involves the use of LLM (Language and Vision Models) and visual description models. These models are able to generate textual descriptions of video content combined with VG (Video Game) task instructions, and these descriptions are implemented with carefully designed prompts. 
The second strategy is better than VidLLM, pointing out a promising direction for future research. This strategy is mainly limited by the limitations of the visual model and the design of the cue words, so being able to generate detailed and accurate video descriptions, a more refined graphical model can significantly improve the VG performance of LLM.

In summary, this study provides a groundbreaking evaluation of the application of LLM to VG tasks, highlighting the need for more sophisticated methods in model training and cue design.
The reference address of the paper is attached to this site: 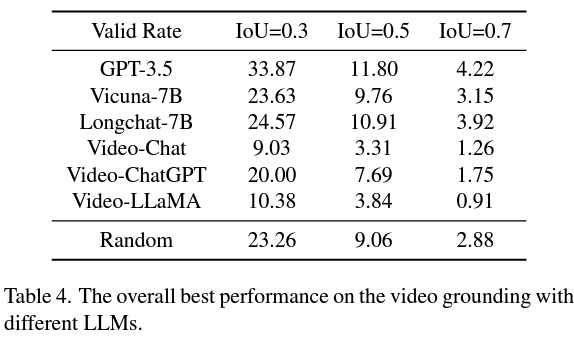
The above is the detailed content of Evaluate the performance of the LLM4VG benchmark developed by Tsinghua University in video timing positioning. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 What does class mean in c language?
What does class mean in c language?
 C language data structure
C language data structure
 How to solve Permission denied
How to solve Permission denied
 Association rules apriori algorithm
Association rules apriori algorithm
 What is the name of the telecommunications app?
What is the name of the telecommunications app?
 What are the advantages and disadvantages of decentralization
What are the advantages and disadvantages of decentralization








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



