


Large-scale language models (LLMs) have made tremendous progress in both academia and industry. But training and deploying LLM is very expensive and requires a lot of computing resources and memory, so researchers have developed many open source frameworks and methods for accelerating LLM pre-training, fine-tuning, and inference. However, the runtime performance of different hardware and software stacks can vary significantly, making it difficult to choose the best configuration.
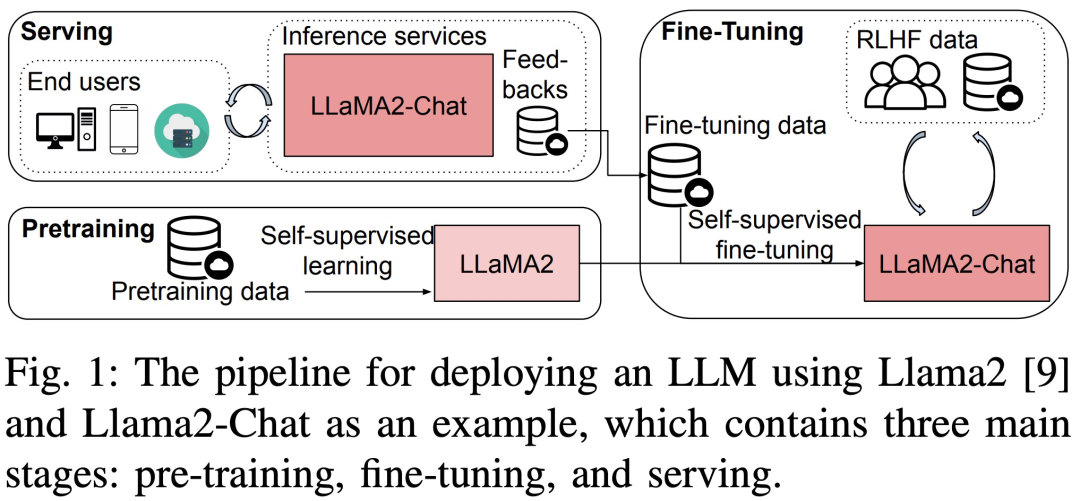
Recently, a new paper titled "Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models" The runtime performance of LLM training, fine-tuning, and inference is analyzed in detail from macro and micro perspectives.

Please click the following link to view the paper: https://arxiv.org/pdf/2311.03687.pdf
Specifically, this study first conducted a full-process performance benchmark test on LLM of different sizes (7B, 13B and 70B parameters) on three 8-GPUs for pre-training, fine-tuning and service without changing the original meaning. . The tests covered platforms with and without individual optimization technologies, including ZeRO, Quantize, Recalculate, and FlashAttention. The study then further provides a detailed runtime analysis of sub-modules of computation and communication operators in LLM
The study The benchmark test adopts a top-down approach, covering the end-to-end step time performance, module-level time performance and operator time performance of Llama2 on three 8-GPU hardware platforms, as shown in Figure 3.
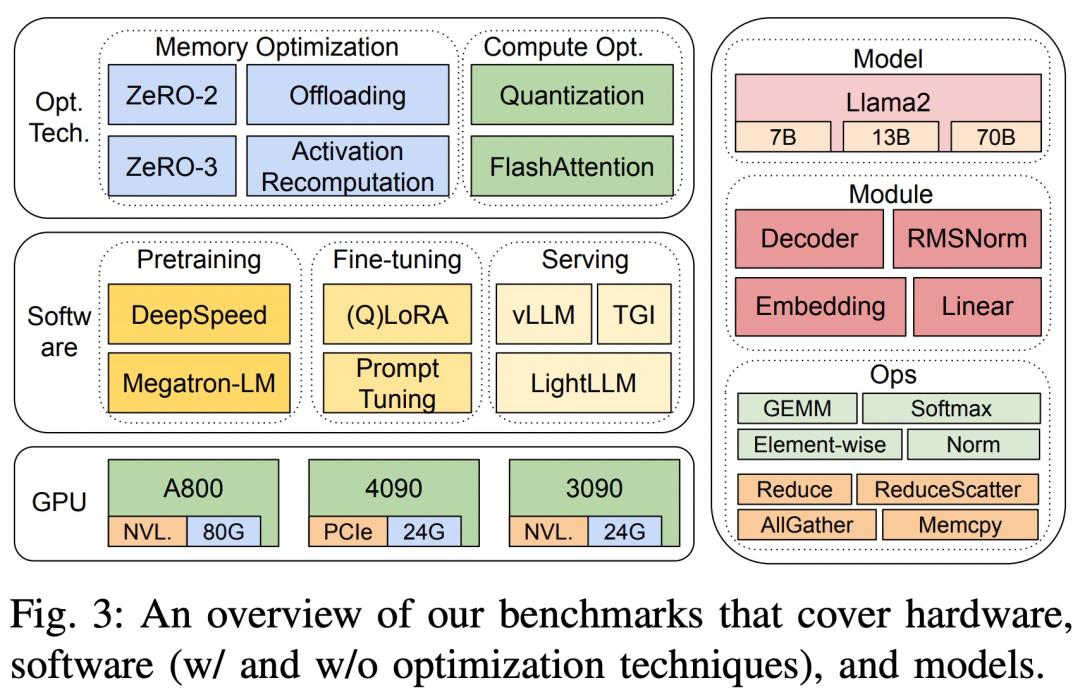
The three hardware platforms are RTX4090, RTX3090 and A800. The specific specifications are shown in Table 1 below.
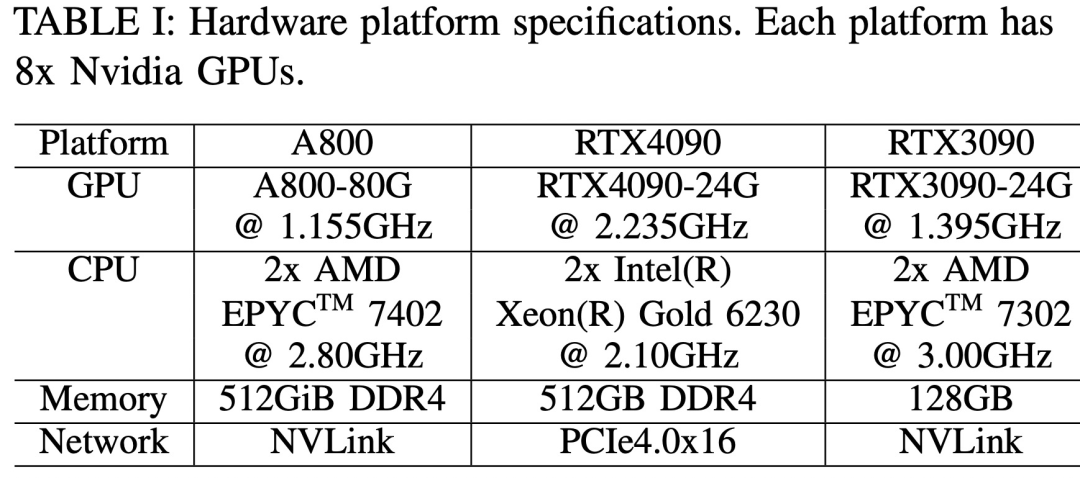
On the software side, the study compares DeepSpeed and Megatron-LM end-to-end in terms of pre-training and fine-tuning step time. To evaluate optimization techniques, the study used DeepSpeed to enable the following optimizations one by one: ZeRO-2, ZeRO-3, offloading, activation recomputation, quantization, and FlashAttention to measure performance improvements and reductions in time and memory consumption.
In terms of LLM services, there are three highly optimized systems, vLLM, LightLLM and TGI, and this study compared their performance (latency and throughput) on three test platforms .
In order to ensure the accuracy and reproducibility of the results, this study calculated the average length of instructions, inputs and outputs of the commonly used LLM data set alpaca, that is, 350 tokens per sample, And randomly generate strings to achieve a sequence length of 350.
In the inference service, in order to comprehensively utilize computing resources and evaluate the robustness and efficiency of the framework, all requests are scheduled in burst mode. The experimental data set consists of 1000 synthetic sentences, each sentence contains 512 input tokens. This study always maintains the "maximum generated token length" parameter in all experiments on the same GPU platform to ensure the consistency and comparability of results.
No need to change the original meaning, the whole process performance
This study passed pre-training and fine-tuning And infer the step time, throughput and memory consumption of Llama2 models of different sizes (7B, 13B and 70B) to measure the full performance on the three test platforms without changing the original meaning. Three widely used inference serving systems: TGI, vLLM, and LightLLM are also evaluated, focusing on metrics such as latency, throughput, and memory consumption.
Module Level Performance
LLM usually consists of a series of modules (or layers) , these modules may have unique computing and communication characteristics. For example, the key modules that make up the Llama2 model are Embedding, LlamaDecoderLayer, Linear, SiLUActivation, and LlamaRMSNorm.
In the pre-training experiment session, the researcher first analyzed the pre-training of different size models (7B, 13B and 70B) on three test platforms performance (iteration time or throughput, memory consumption), and then micro-benchmarks at module and operational levels were conducted.
No need to change the original meaning, the whole process performance
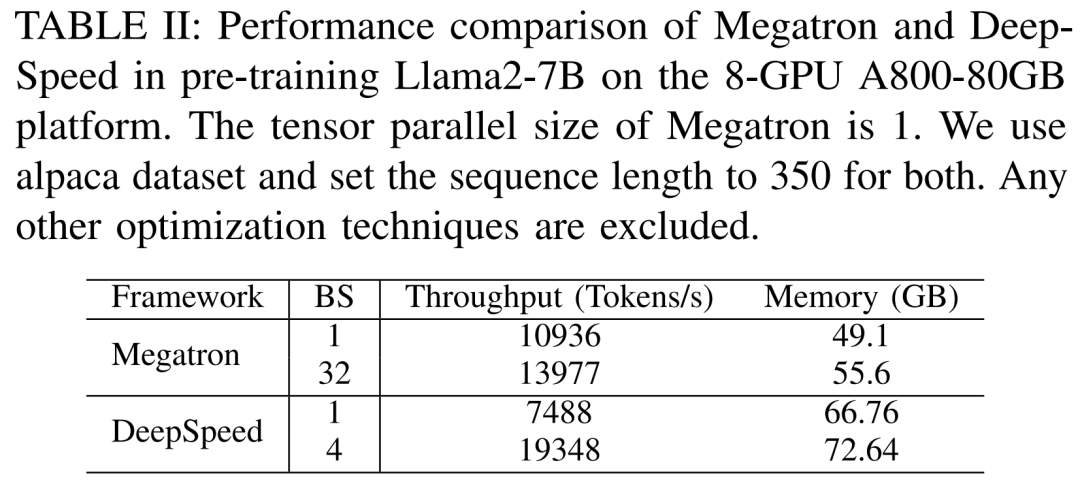
The researchers first conducted experiments to compare The performance of Megatron-LM and DeepSpeed, both of which did not use any memory optimization technology (such as ZeRO) when pre-training Llama2-7B on the A800-80GB server.
They used a sequence length of 350 and provided two sets of batch sizes for Megatron-LM and DeepSpeed, from 1 to the maximum batch size. The results are shown in Table II below, benchmarked against training throughput (tokens/second) and consumer GPU memory (in GB).
The results show that when the batch size is 1, Megatron-LM is slightly faster than DeepSpeed. However, DeepSpeed is the fastest in training speed when the batch size reaches its maximum. When the batch sizes are the same, DeepSpeed consumes more GPU memory than the tensor parallel-based Megatron-LM. Even with small batch sizes, both systems consumed significant amounts of GPU memory, causing memory overflow on the RTX4090 or RTX3090 GPU servers.
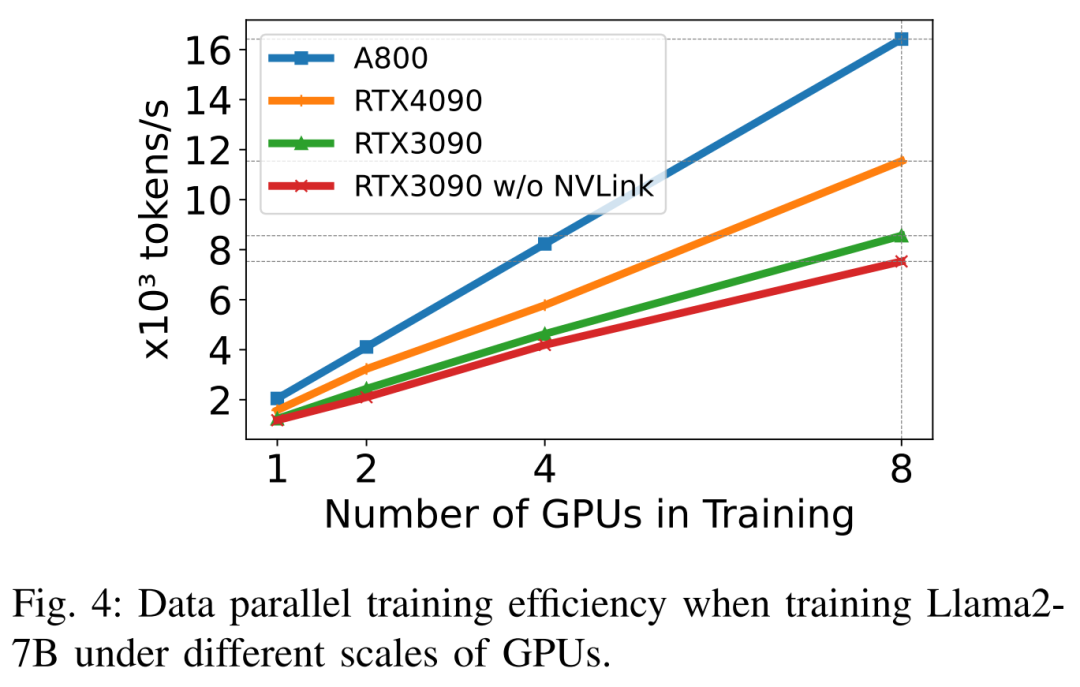
When training Llama2-7B (sequence length 350, batch size 2), the researcher used DeepSpeed with quantization to study Scaling efficiency on different hardware platforms. The results are shown in Figure 4 below. The A800 scales almost linearly, and the scaling efficiency of RTX4090 and RTX3090 is slightly lower, at 90.8% and 85.9% respectively. On the RTX3090 platform, NVLink connections are 10% more efficient than without NVLink.
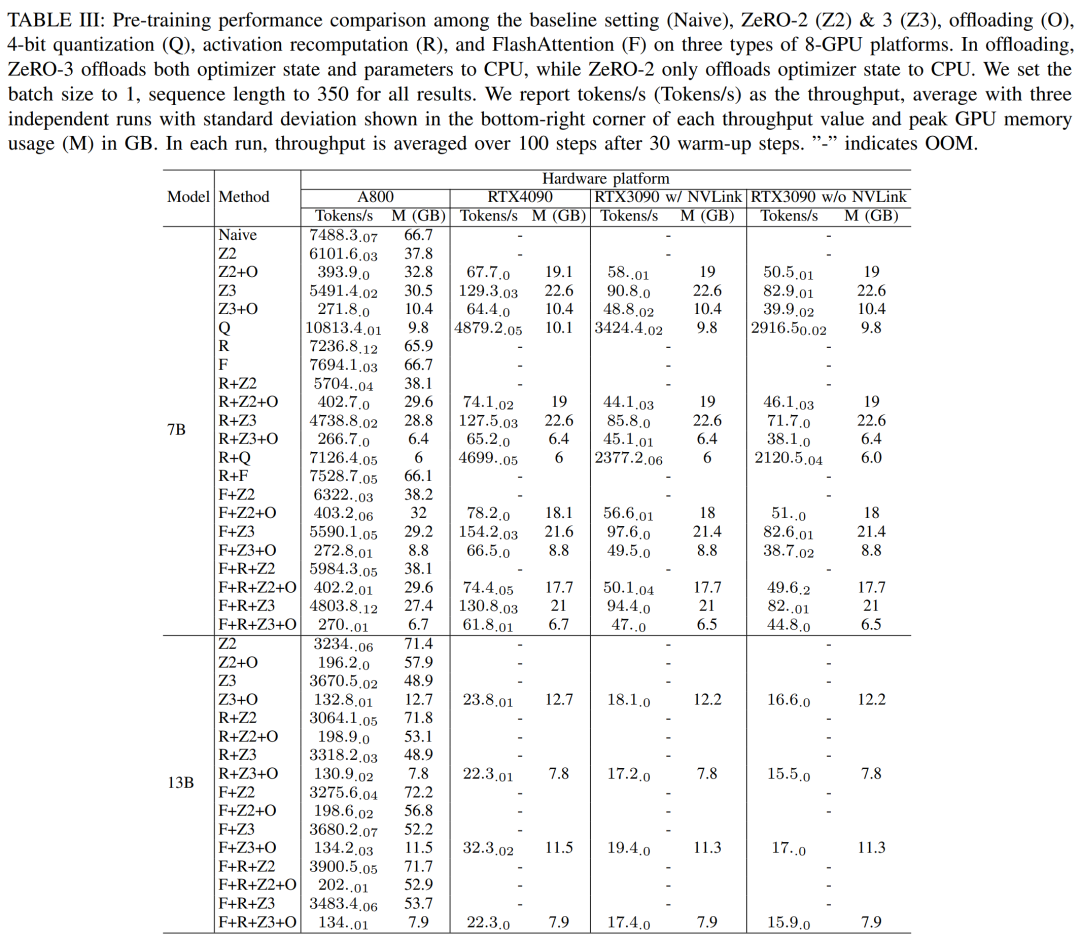
Researchers used DeepSpeed to evaluate training performance under different memory and computationally efficient methods. For fairness, all evaluations are set to a sequence length of 350, a batch size of 1, and a default loaded model weight of bf16.
For ZeRO-2 and ZeRO-3 with offloading capabilities, they offload the optimizer state and optimizer state model to CPU RAM respectively. For quantization, they used a 4bits configuration with dual quantization. Also reported is the performance of the RTX3090 when NVLink is disabled (i.e. all data is transferred over the PCIe bus). The results are shown in Table III below.
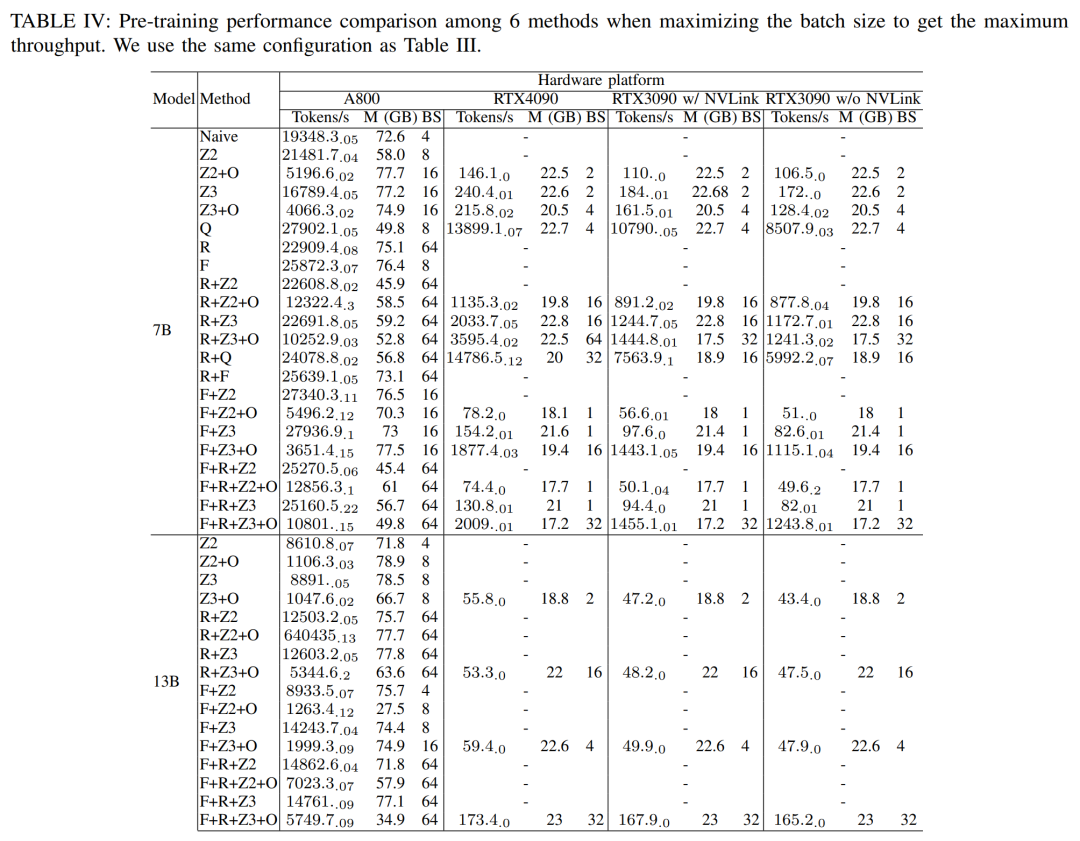
#To obtain maximum throughput, the researchers further utilized the computing power of different GPU servers by maximizing the batch size for each method. The results are shown in Table IV, showing that increasing the batch size can easily improve the training process. Therefore, GPU servers with high bandwidth and large memory are more suitable for full-parameter mixed precision training than consumer-grade GPU servers
Module level analysis
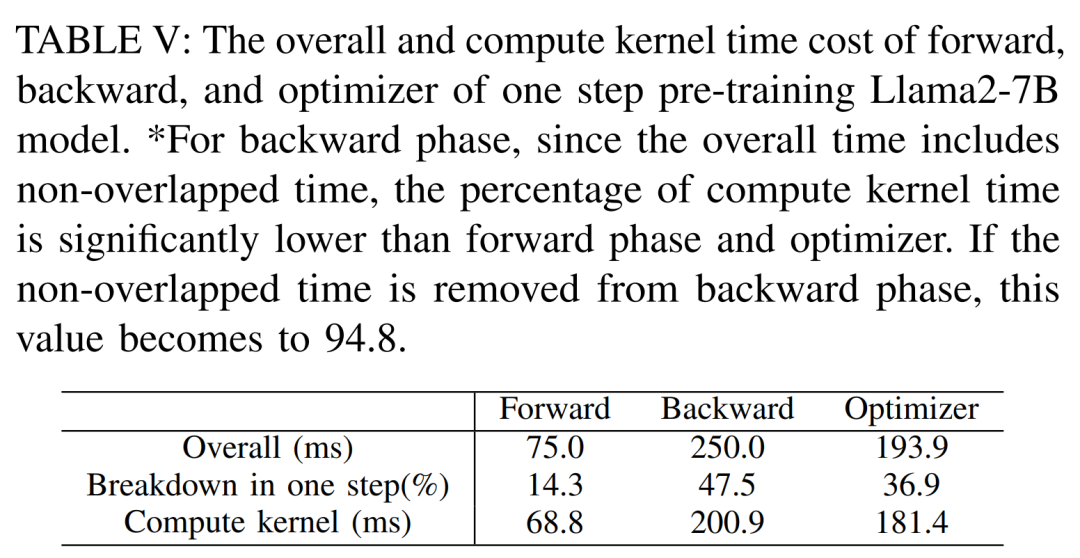
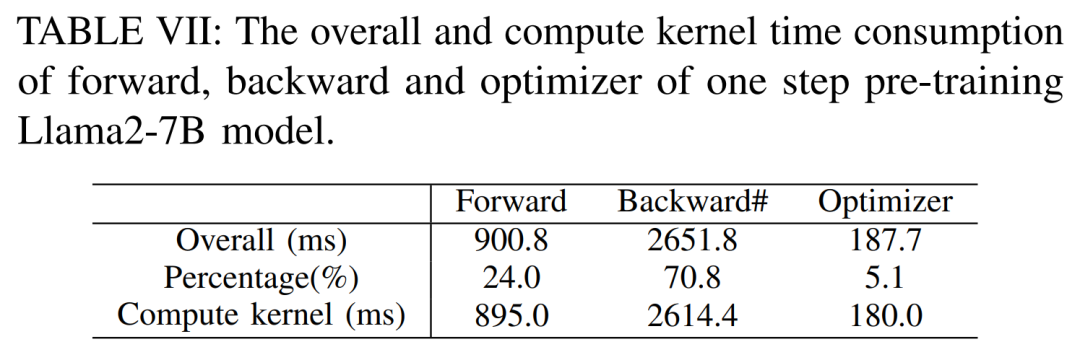
Table V below shows the overall and computational core time of the forward, backward and optimizer of the single-step pre-trained Llama2-7B model cost. For the backward phase, since the total time includes non-overlapping time, the computational core time is much smaller than the forward phase and optimizer. If the non-overlapping time is removed from the backward phase, the value becomes 94.8.
##Need to recalculate and re-evaluate the impact of FlashAttention
Techniques for accelerating pre-training can be roughly divided into two categories: saving memory, increasing batch size, and accelerating computing cores. As shown in Figure 5 below, the GPU spends 5-10% of its time idle during the forward, backward, and optimizer phases.
The researchers believed this idle time was due to smaller batch sizes, so they tested all techniques with the largest batch sizes available. Ultimately, they used recalculation to increase the batch size and used FlashAttention to speed up core analysis
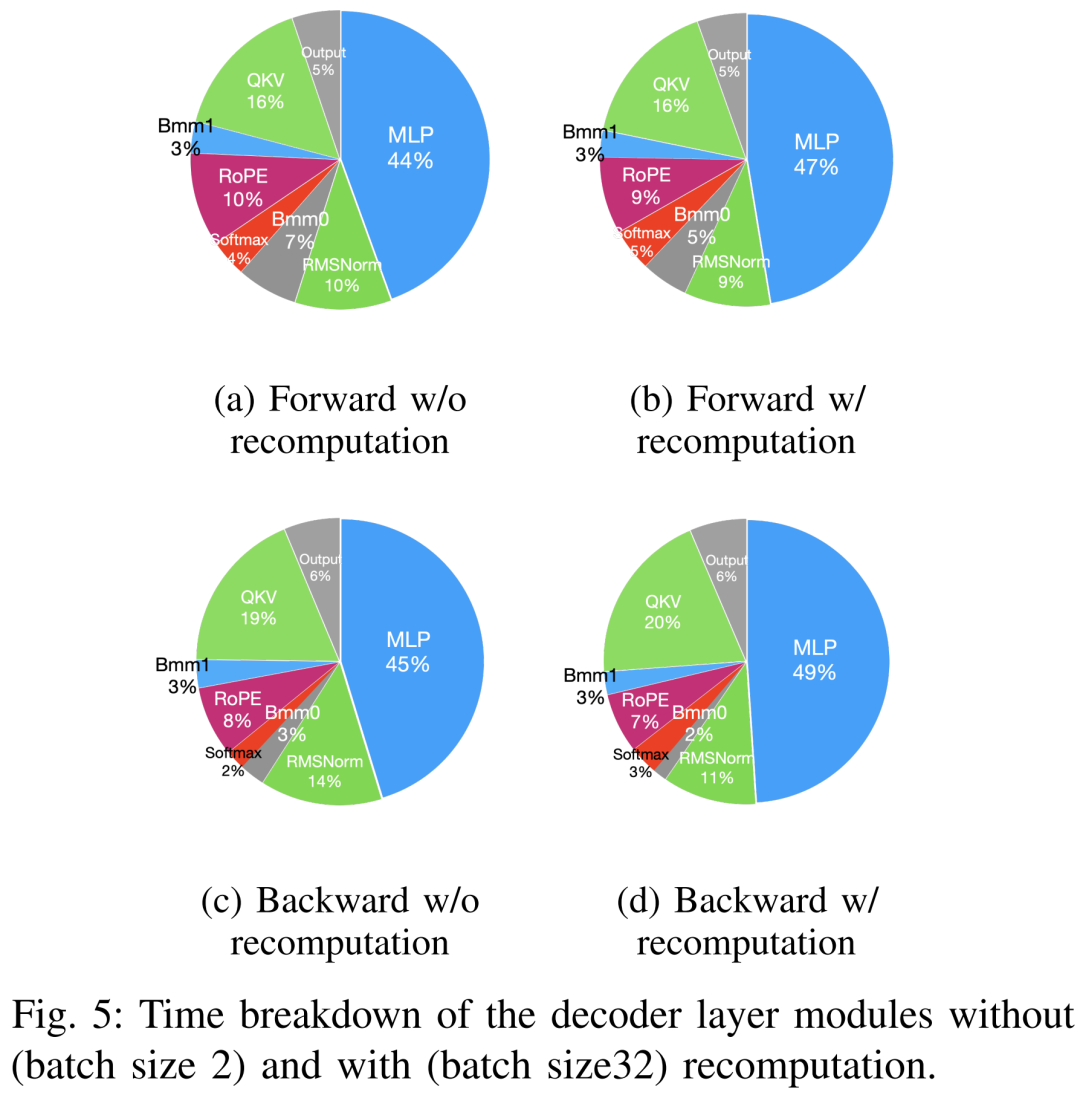
As shown in Table VII below, as the batch size increases, the time of the forward and backward phases increases significantly, leaving almost no GPU idle time.
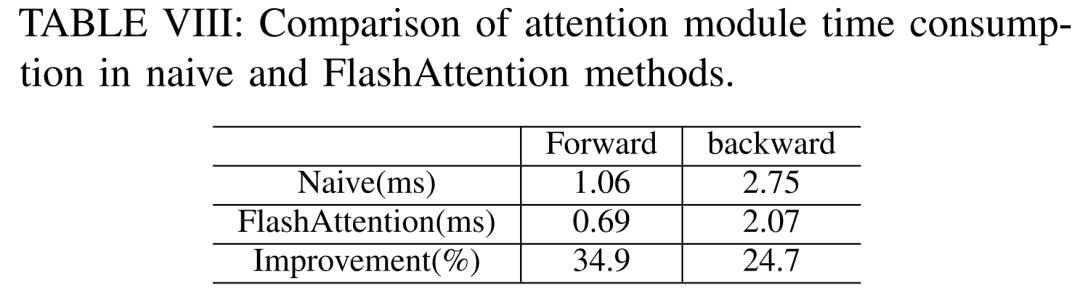
According to Table VIII below, FlashAttention can accelerate the forward and backward attention modules by 34.9% and 24.7% respectively
In the fine-tuning session, the researchers mainly discussed the parameter efficient fine-tuning method (PEFT) and demonstrated LoRA and QLoRA Fine-tuned performance under various model sizes and hardware settings. Use a sequence length of 350, a batch size of 1, and load the model weights into bf16 by default.
According to the results in Table IX below, the performance trends after fine-tuning Llama2-13B using LoRA and QLoRA are consistent with Llama2-7B. Compared with Llama2-7B, the throughput of fine-tuned Llama2-13B dropped by about 30%
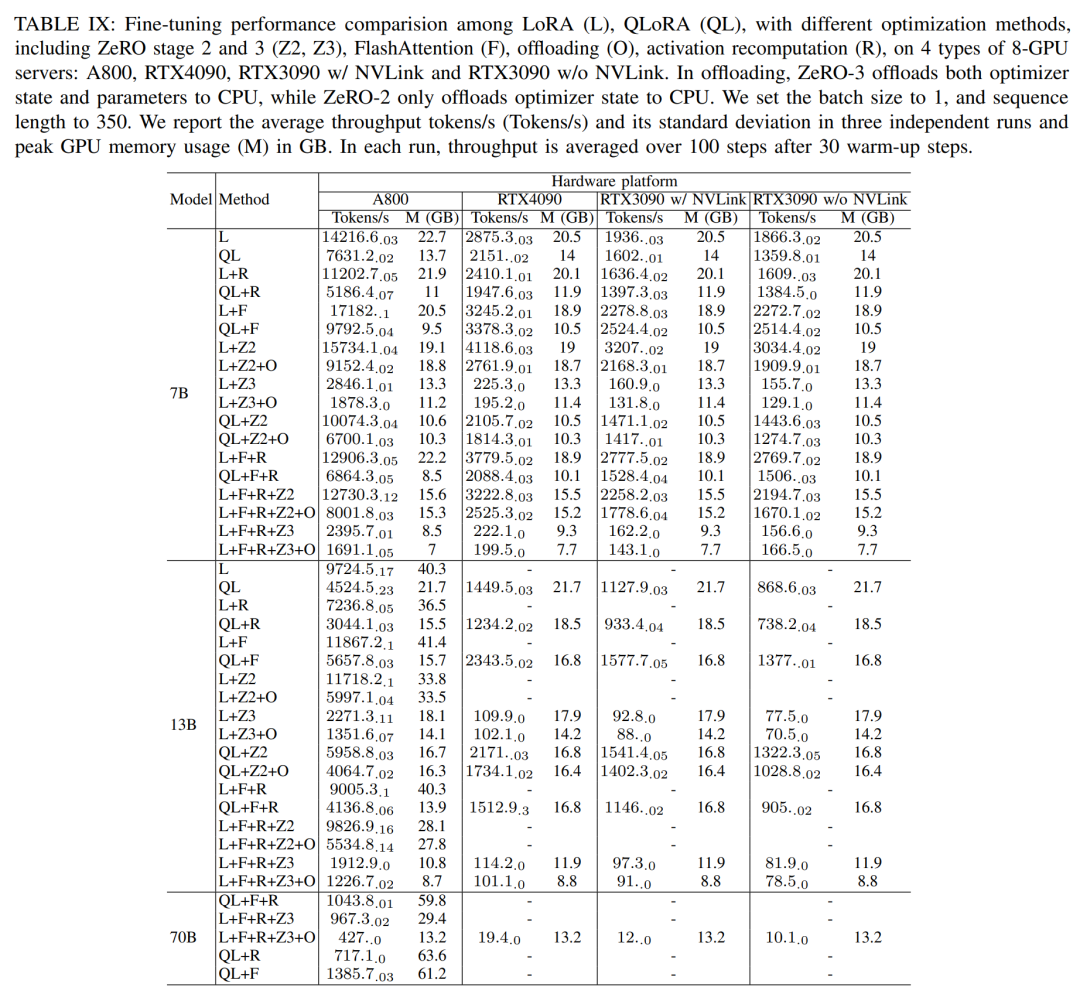
However, when all optimization techniques are combined, Even RTX4090 and RTX3090 can fine-tune Llama2-70B to achieve a total throughput of 200 tokens/second.
No need to change the original meaning, full performance
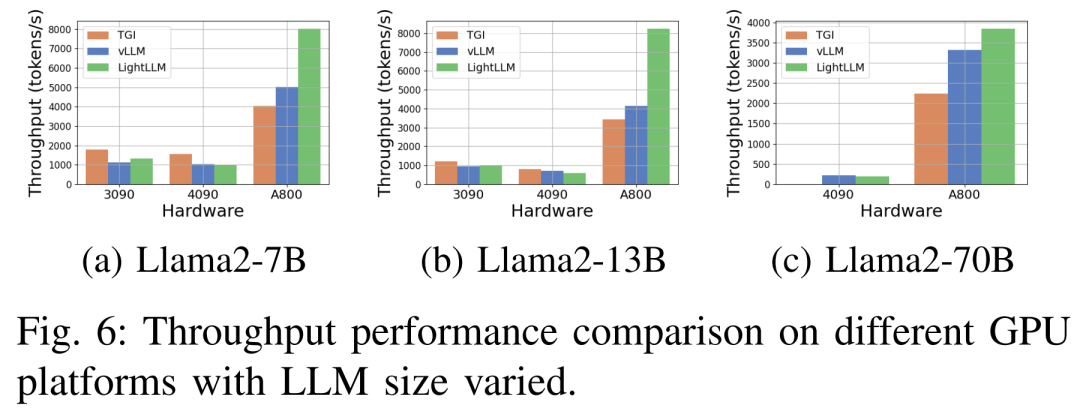
Figure 6 below shows a comprehensive analysis of throughput under various hardware platforms and inference frameworks, in which the relevant inference data of Llama2-70B is omitted. Among them, the TGI framework demonstrated excellent throughput, especially on GPUs with 24GB of memory such as the RTX3090 and RTX4090. In addition, LightLLM significantly outperforms TGI and vLLM on the A800 GPU platform, with throughput almost doubling.
These experimental results show that the TGI inference framework has excellent performance on the 24GB memory GPU platform, while the LightLLM inference framework exhibits the highest throughput on the A800 80GB GPU platform. This finding suggests that LightLLM is optimized specifically for the A800/A100 series of high-performance GPUs.
The delay performance is shown in Figures 7, 8, 9 and 10 under different hardware platforms and reasoning frameworks
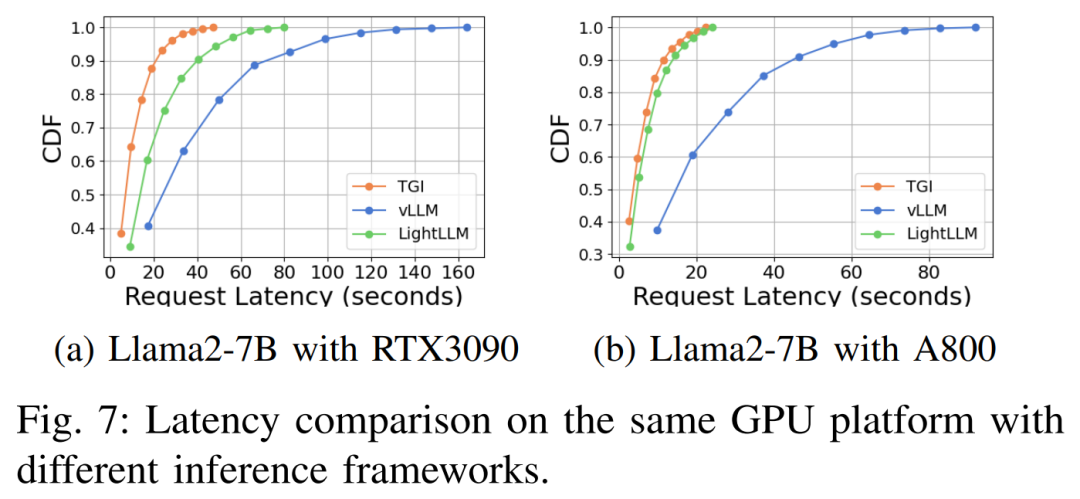
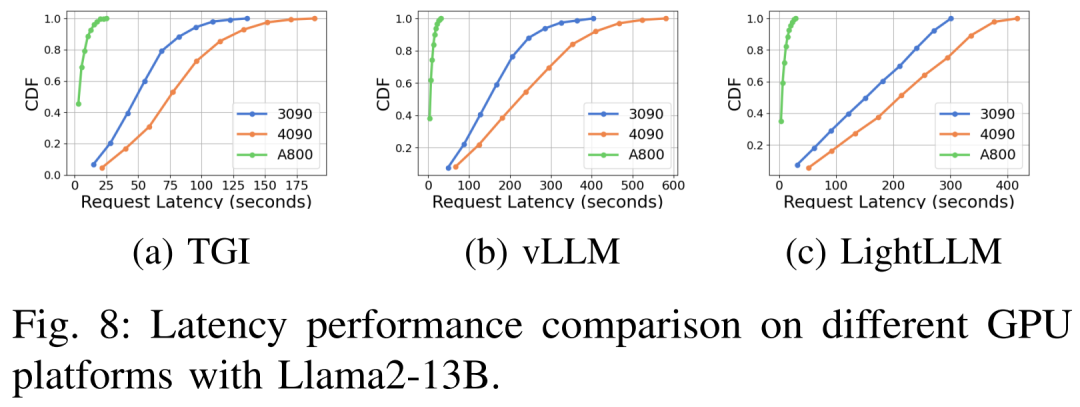
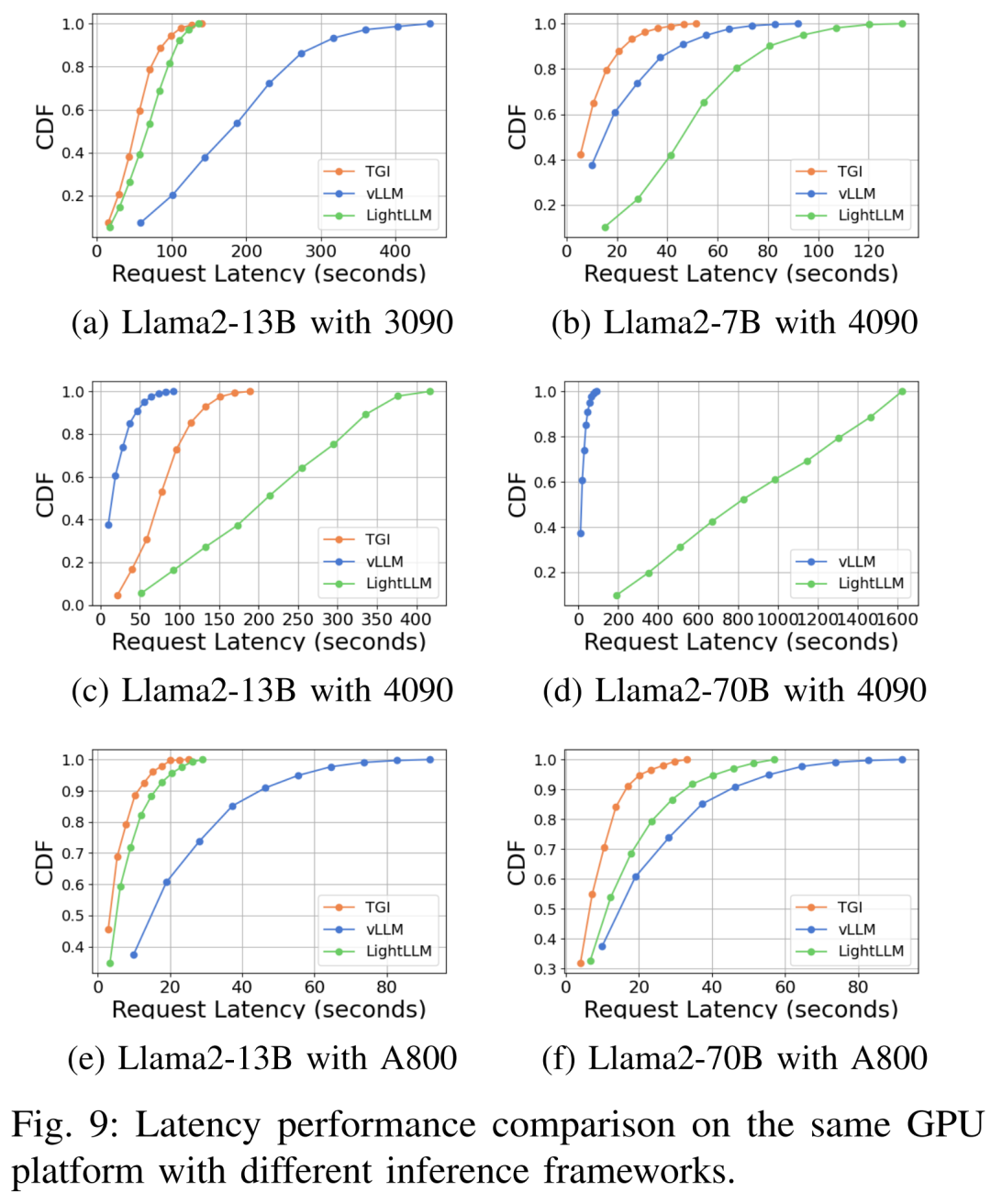
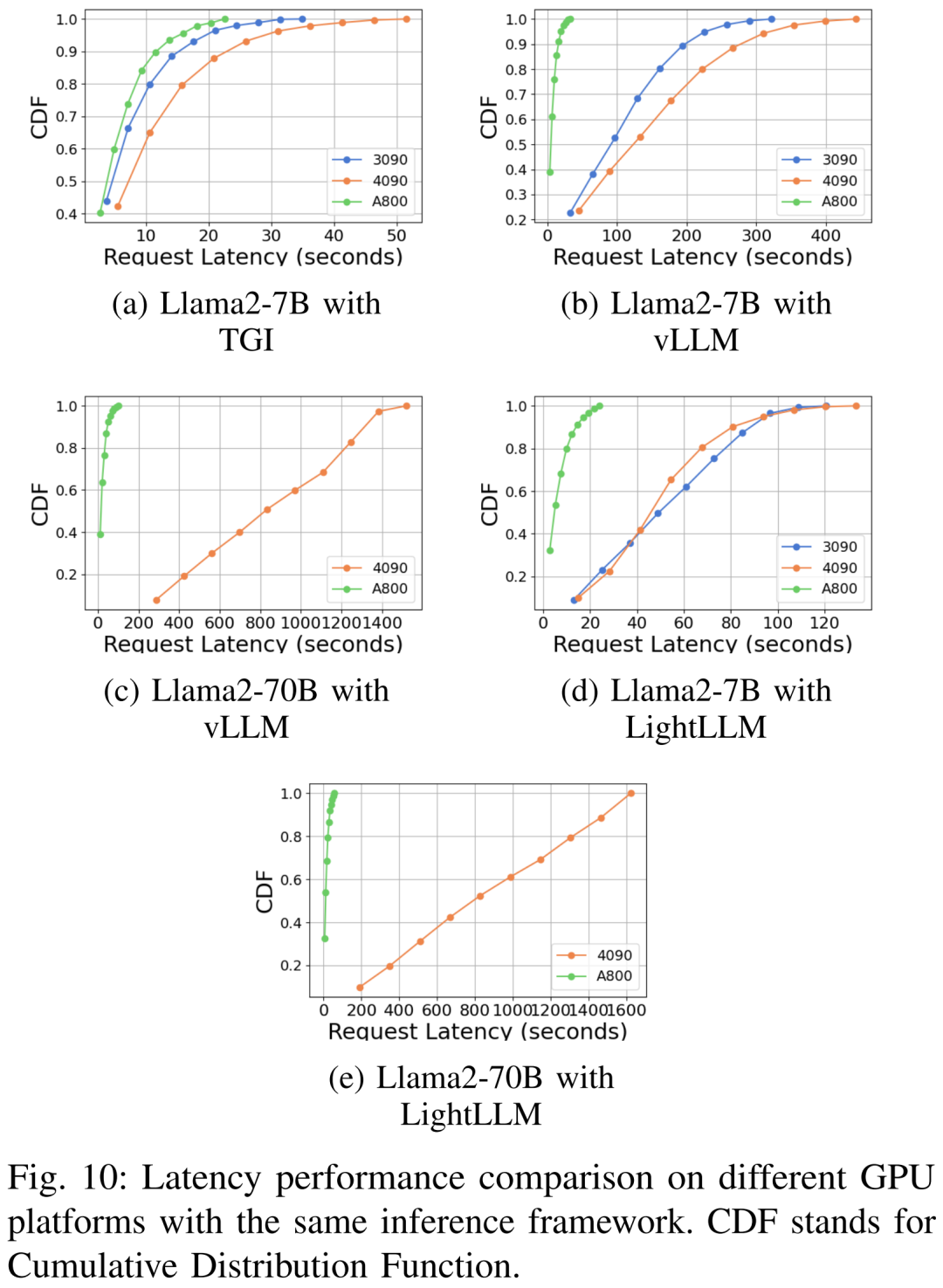
#As shown above, the A800 platform is significantly better than the two consumer-grade platforms RTX4090 and RTX3090 in terms of throughput and latency. And among the two consumer-grade platforms, the RTX3090 has a slight advantage over the RTX4090. The three inference frameworks TGI, vLLM, and LightLLM show no substantial difference in throughput when running on consumer-grade platforms. In comparison, TGI consistently outperforms the other two in terms of latency. On the A800 GPU platform, LightLLM performs best in terms of throughput and its latency is also very close to the TGI framework.
Please refer to the original text for more experimental results
The above is the detailed content of A800 significantly surpasses Llama2 inference RTX3090 and 4090, performing excellent latency and throughput. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



