Recently, a speech synthesis system based on the Schrödinger Bridge [1] released by Professor Zhu Jun’s research group from the Department of Computer Science at Tsinghua University, relies on its “data-to-data” generation paradigm, defeating both in terms of sample quality and sampling speed. The "noise-to-data" paradigm of diffusion models. 
Paper link: https://arxiv.org/abs/2312.03491Project website: https://bridge-tts.github.io/ Code implementation: https://github.com/thu-ml/Bridge-TTSSince 2021, diffusion models have begun to become one of the core generation methods in the field of text-to-speech synthesis (TTS). First, methods such as Grad-TTS [2] proposed by Huawei's Noah's Ark Laboratory and DiffSinger [3] proposed by Zhejiang University have achieved high generation quality. Since then, many research works have effectively improved the sampling speed of diffusion models, such as through prior optimization [2, 3, 4], model distillation [5, 6], residual prediction [7] and other methods. However, as shown in this study, because the diffusion model is limited to the generation paradigm of "noise to data", its prior distribution always provides limited information for the generation target and cannot fully utilize the conditional information.
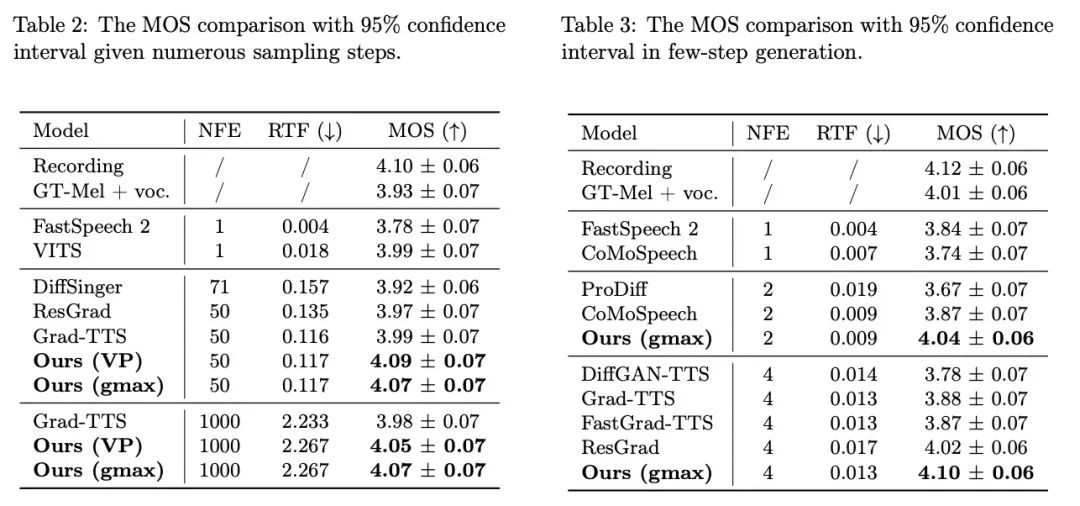
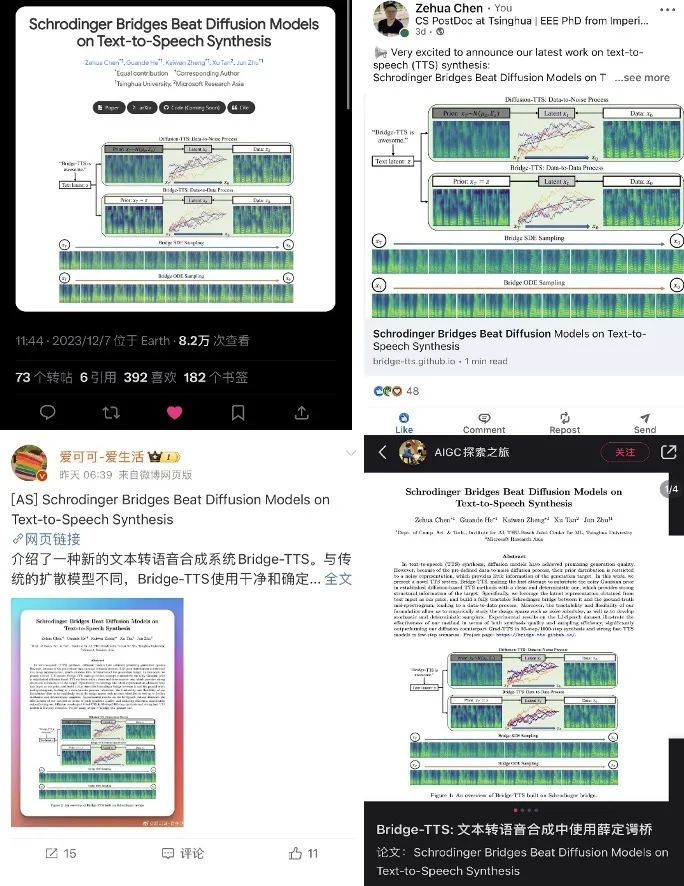
The latest research work in the field of speech synthesis, Bridge-TTS, relies on its generation framework based on Schrödinger bridge to realize the generation process of "data to data". For the first time, the priori speech synthesis Information is modified from noise to clean data, and is modified from distribution to deterministic representation. The main architecture of this method is shown in the figure above. The input text is first extracted through the text encoder to extract the latent space representation of the generated target (mel-spectrogram, mel spectrum). Thereafter, unlike the diffusion model that incorporates this information into the noise distribution or uses it as conditional information, the Bridge-TTS method supports directly using it as prior information and supports random or deterministic sampling, High Quality , quicklygenerate targets. In verifying the quality of speech synthesis On the standard data set LJ-Speech, the research team compared Bridge-TTS with 9 high-quality speech synthesis systems and accelerated sampling methods of diffusion models. As shown below, this method beats high-quality diffusion model-based TTS systems [2,3,7] in sample quality (1000 steps, 50 steps sampling) and in sampling speed, without any post-processing such as additional model distillation, it surpasses many acceleration methods, such as residual prediction, progressive distillation, and the latest consistency distillation [5, 6, 7]. The following are examples of the generation effects of Bridge-TTS and the diffusion model-based method. For more generation sample comparisons, please visit the project website: https://bridge-tts.github. io/-
1000 step synthesis effect comparison
Enter text: "Printing, then, for our purpose, may be considered as the art of making books by means of movable types." 
-
4 Step Synthesis Effect Comparison
Input text: "The first books were printed in black letter, i.e. the letter which was a Gothic development of the ancient Roman character,」
- ## 2 Comparison of step synthesis effects
Enter text: "The prison population fluctuated a great deal,"
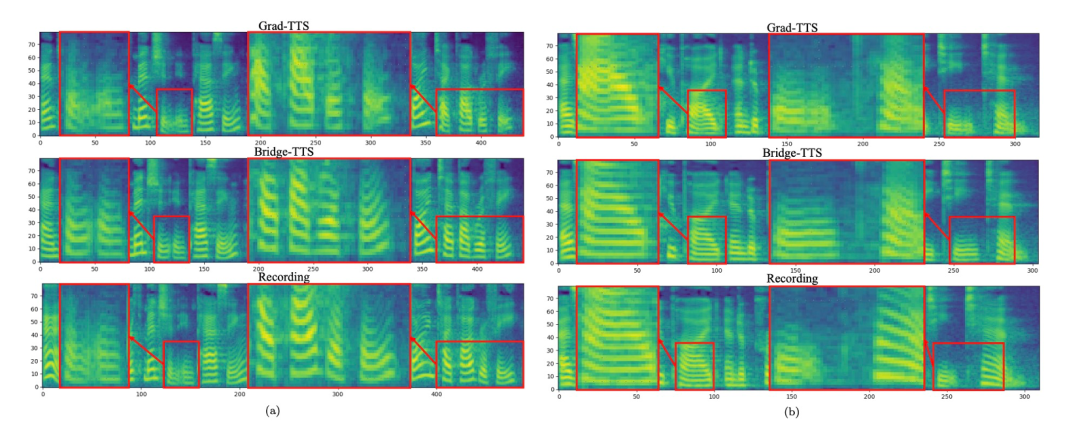
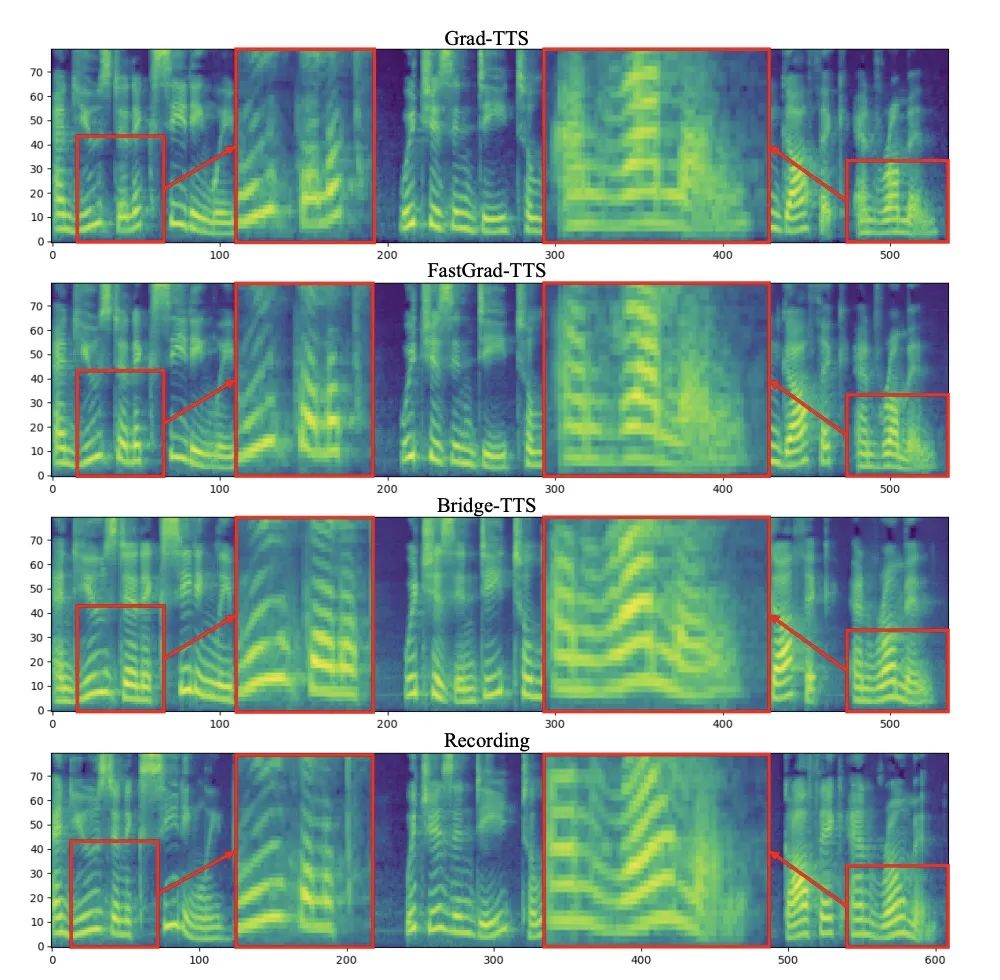
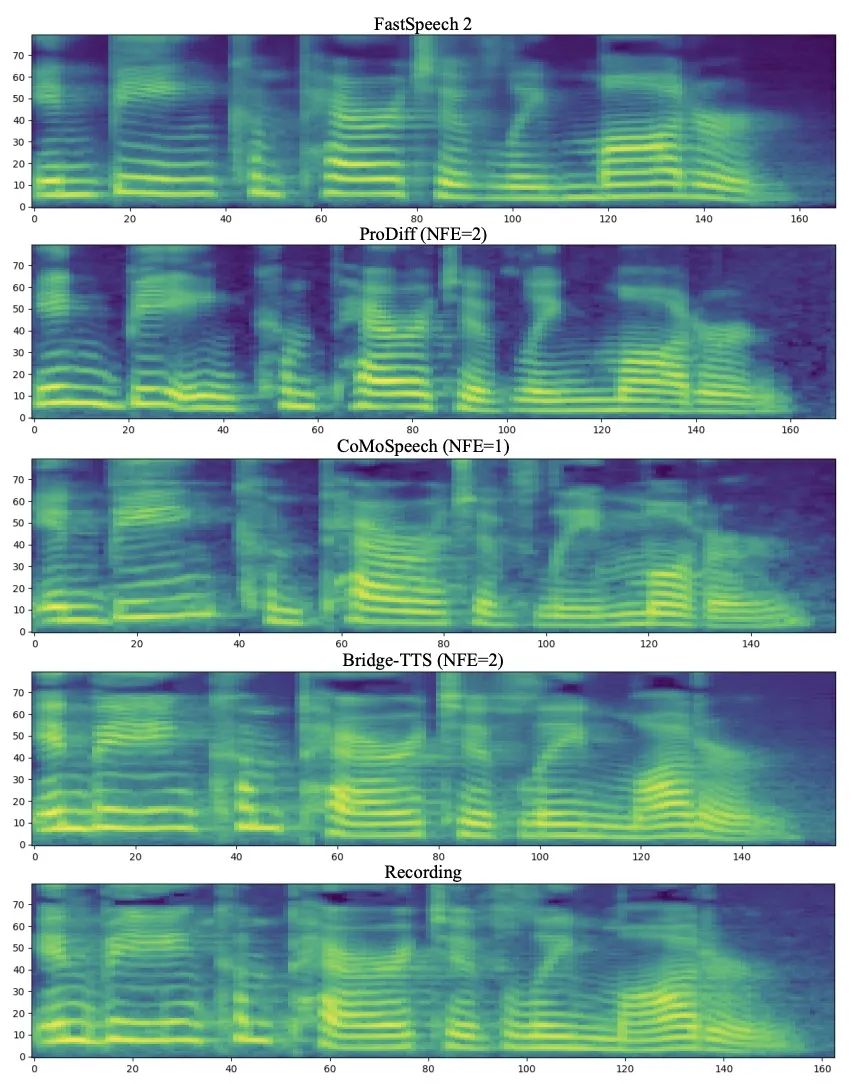
In the frequency domain, more generated samples are shown below. In 1000 steps of synthesis, this method generates higher quality mel compared to the diffusion model. Spectrum, when the number of sampling steps drops to 50, the diffusion model has sacrificed some sampling details, while the method based on Schrödinger bridge still maintains high-quality generation effects. In 4-step and 2-step synthesis, this method does not require distillation, multi-stage training, and adversarial loss functions, and still achieves high-quality generation effects.
##Comparison of the mel spectra of Bridge-TTS and the diffusion model-based method in 1000 steps of synthesis 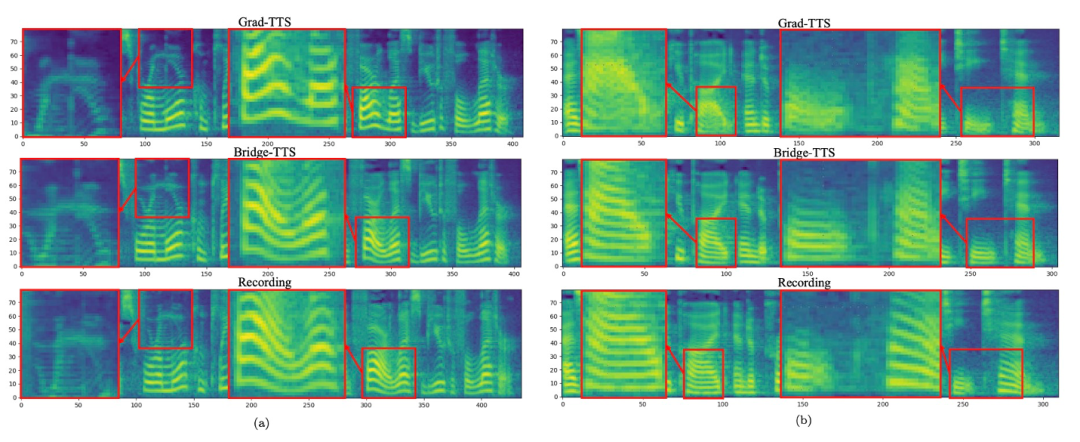
Comparison of Mel spectra between Bridge-TTS and diffusion model-based methods in 50-step synthesis
Comparison of Mel spectra between Bridge-TTS and diffusion model-based methods in 4-step synthesis Comparison of Mel spectra between Bridge-TTS and diffusion model-based methods in 2-step synthesis Once Bridge-TTS was released, it attracted enthusiastic attention on Twitter with its novel design and high-quality synthesis effects in speech synthesis. , received more than a hundred retweets and hundreds of likes, was selected into Huggingface’s Daily Paper on 12.7 and won the first place in the support rate on that day, and was also featured in LinkedIn, Weibo, Zhihu, Xiaohongshu and other domestic It was followed and reported on external platforms. Many foreign language websites also reported and discussed: ##Schrodinger Bridge is a type of deep
generative model that has recently emerged following the diffusion model, has preliminary applications in image generation, image translation and other fields [8,9]. Unlike the diffusion model, which establishes a transformation process between data and Gaussian noise, the Schrödinger bridge supports transformation between any two boundary distributions. In the study of Bridge-TTS, the authors proposed a speech synthesis framework based on the Schrödinger bridge between paired data, which flexibly supports a variety of forward processes, prediction targets, and sampling processes. An overview of its method is shown in the figure below: 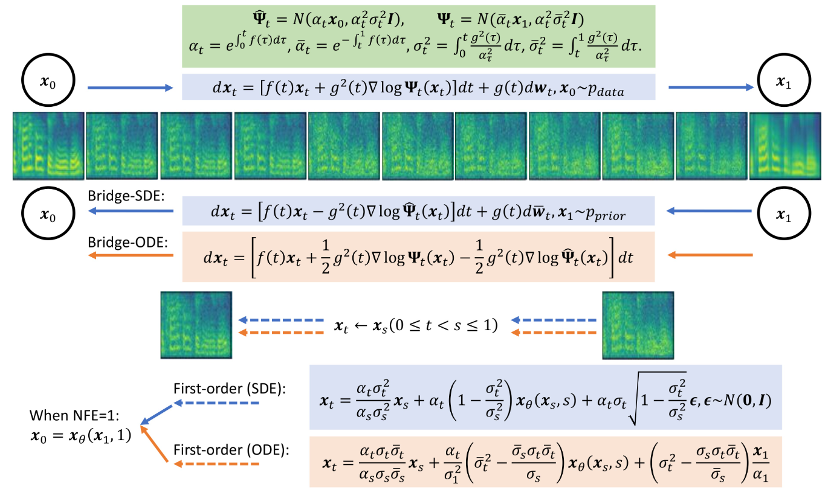
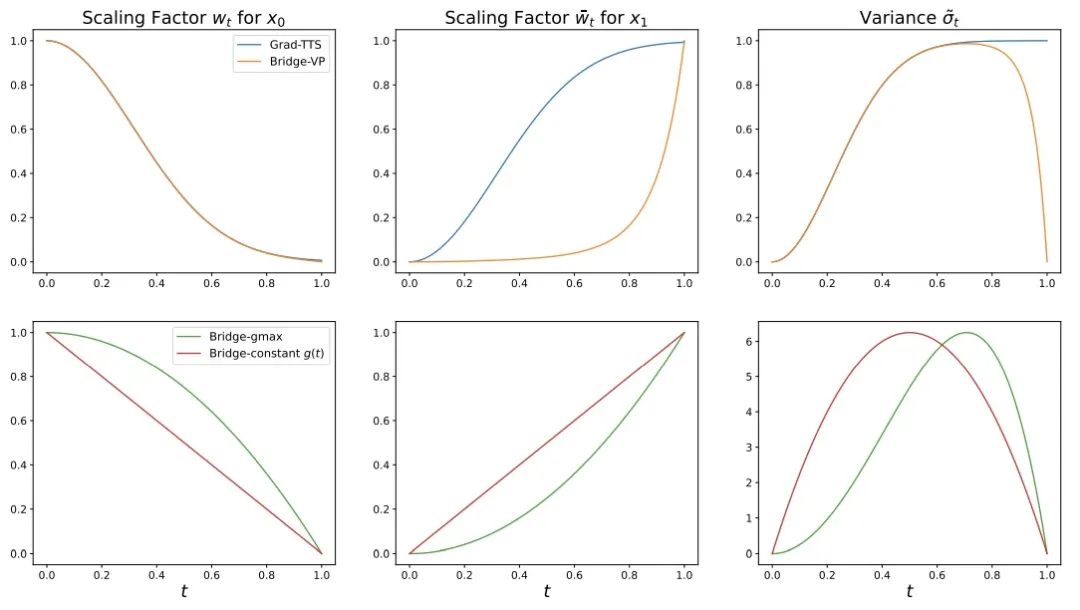
- Forward process: This study combines strong information priors and generation goals A fully solvable Schrödinger bridge is built between them, supporting flexible forward process selection, such as symmetric noise strategy:, constant
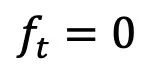 , and
, and 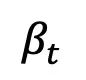 asymmetric noise strategy: , linear
asymmetric noise strategy: , linear  , and
, and  variance-preserving (VP) noise strategies that correspond directly to diffusion models. This method found that in speech synthesis tasks, asymmetric noise strategies: linear (gmax) and VP processes have better generation effects than symmetric noise strategies.
variance-preserving (VP) noise strategies that correspond directly to diffusion models. This method found that in speech synthesis tasks, asymmetric noise strategies: linear (gmax) and VP processes have better generation effects than symmetric noise strategies. 

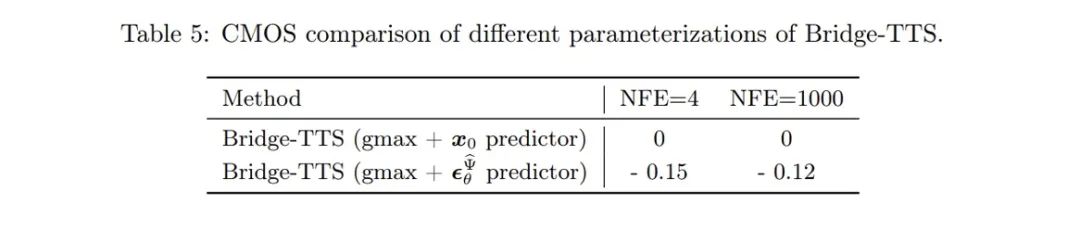
- Model training: This method maintains many advantages of the diffusion model training process, such as single stage, single model, and single loss function. And it compares various methods of model parameterization (Model parameterization), that is, the selection of network training targets, including noise prediction (Noise), generation target prediction (Data), and flow matching technology corresponding to the diffusion model [10,11] Velocity prediction (Velocity), etc. The article found that when the generation target, that is, the mel spectrum, is used as the network prediction target, relatively better generation results can be achieved.
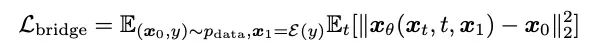
- Sampling process: Thanks to the fact that the Schrödinger bridge is completely solvable in this study By transforming the forward-backward SDE system corresponding to the Schrödinger bridge, the authors obtained Bridge SDE and Bridge ODE for inference. At the same time, due to the slow speed of direct simulation of Bridge SDE/ODE inference, in order to speed up sampling, this study used the exponential integrator commonly used in diffusion models [12,13], and gave the first-order SDE and ODE sampling forms of the Schrödinger bridge:
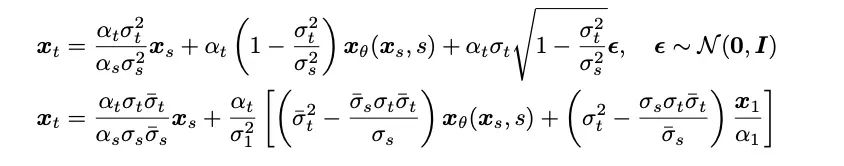
#In 1-step sampling, the sampling forms of first-order SDE and ODE jointly degenerate into single-step prediction of the network. At the same time, they are closely related to posterior sampling/diffusion model DDIM sampling, and the article gives a detailed analysis in the appendix. The article also provides the second-order sampling SDE and ODE sampling algorithms of the Schrödinger bridge. The authors found that in speech synthesis, the generation quality is similar to a first-order sampling process. In other tasks such as speech enhancement, speech separation, speech editing and other tasks where prior information is also strong, the authors expect that this research will also bring greater Value. This study has three co-first authors: Chen Zehua, He Guande and Zheng Kaiwen both belong to Zhu Jun’s research group in the Department of Computer Science at Tsinghua University. The corresponding author of the article is Professor Zhu Jun. Tan Xu, chief research manager of Microsoft Research Asia, is a project collaborator. 
# Tan Xu, Chief Research Manager, Microsoft Research Asia 
Chen Zehua is a Shuimu Scholar postdoctoral fellow in the Department of Computer Science at Tsinghua University. His main research direction is probabilistic generative models and their applications in speech, sound effects, bioelectrical signal synthesis, etc. He has interned at many companies such as Microsoft, JD.com, and TikTok, and published many papers at important international conferences in the field of speech and machine learning, such as ICML/NeurIPS/ICASSP.

He Guande is a third-year master's student at Tsinghua University. His main research direction is uncertainty estimation and generative models. He has previously participated in conferences such as ICLR and Published the paper as the first author.

Zheng Kaiwen is a second-year master's student at Tsinghua University. His main research direction is the theory and algorithm of deep generative models, and their applications in image, audio and 3D generation. He has previously published many papers at top conferences such as ICML/NeurIPS/CVPR, involving technologies such as flow matching and exponential integrators in diffusion models. [1] Zehua Chen, Guande He , Kaiwen Zheng, Xu Tan, and Jun Zhu. Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesis. arXiv preprint arXiv:2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail A. Kudinov. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In ICML, 2021. [3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism. In AAAI, 2022.[4] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon, and Tie-Yan Liu. PriorGrad : Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior. In ICLR, 2022.##[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu , Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2022.[6 ] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In ACM Multimedia, 2023.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian, and Danilo P. Mandic. ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech. arXiv preprint arXiv:2212.14518, 2022.##[8] Yuyang Shi, Valentin De Bortoli, Andrew Campbell , and Arnaud Doucet. Diffusion Schrödinger Bridge Matching. In NeurIPS 2023.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A . Theodorou, Weili Nie, and Anima Anandkumar. I2SB: Image-to-Image Schrödinger Bridge. In ICML, 2023.##[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling. In ICLR, 2023.##[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs. In ICML, 2023.##[12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. In NeurIPS, 2022. [13] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics. In NeurIPS, 2023.The above is the detailed content of With the help of Schrödinger Bridge, Zhu Jun's team at Tsinghua University develops a new speech synthesis system to address proliferation challenges. For more information, please follow other related articles on the PHP Chinese website!



 The following shows Bridge- TTS A case of deterministic synthesis (ODE sampling) in steps 2 and 4. In 4-step synthesis, this method significantly synthesizes more sample details than the diffusion model, and there is no problem of residual noise. In a 2-step synthesis, this method exhibits completely pure sampling trajectories, and refines more generated details at each step.
The following shows Bridge- TTS A case of deterministic synthesis (ODE sampling) in steps 2 and 4. In 4-step synthesis, this method significantly synthesizes more sample details than the diffusion model, and there is no problem of residual noise. In a 2-step synthesis, this method exhibits completely pure sampling trajectories, and refines more generated details at each step. 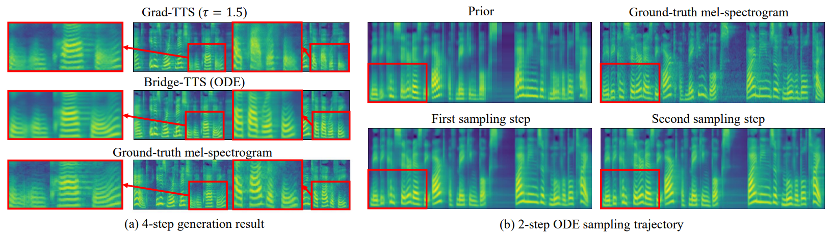
 , and
, and  variance-preserving (VP) noise strategies that correspond directly to diffusion models. This method found that in speech synthesis tasks, asymmetric noise strategies: linear (gmax) and VP processes have better generation effects than symmetric noise strategies.
variance-preserving (VP) noise strategies that correspond directly to diffusion models. This method found that in speech synthesis tasks, asymmetric noise strategies: linear (gmax) and VP processes have better generation effects than symmetric noise strategies. 















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



