


Another Alibaba paper called "Dance Whole Job" caused a sensation after AnimateAnyone
Now, just upload a photo of your face and describe it with a simple sentence, you can be anywhere Let’s dance!
For example, the dance video of "Cleaning the Glass" below:
 Picture
Picture
All you need to do is upload a portrait photo , and fill in the corresponding prompt information
In the golden leaves of autumn, a girl is smiling and dancing in a light blue dress
As the prompts change, the background and clothes of the character will also Change accordingly. For example, we can change a few more sentences:
A girl is smiling and dancing in a wooden house. She is wearing a sweater and trousers
A girl is smiling and dancing in Times Square, Wearing a dress-like white shirt, long sleeves, and long pants.
 Picture
Picture
This is Ali's latest research - DreaMoving, which focuses on letting anyone dance at any time and anywhere.
 Pictures
Pictures
And not only real people, but also cartoon and animation characters can be held~
 Picture
Picture
As soon as the project came out, it also attracted the attention of many netizens. Some people called "Unbelievable" after seeing the effect~
 Picture
Picture
So how is this result achieved? How was this research conducted?
Although the advent of text-to-video (T2V) models such as Stable Video Diffusion and Gen2, has made great progress in the field of video generation A major breakthrough, but there are still many challenges
For example, in terms of data sets, there is currently a lack of open source human dance video data sets and difficulty in obtaining corresponding precise text descriptions, which makes it difficult for models to generate diverse Sexuality, frame consistency, and longer videos have become challenges
And in the field of human-centered content generation, the personalization and controllability of the generated results are also key factors.
 Picture
Picture
In order to deal with these two challenges, the Alibaba team first started to process the data set
The researchers first collected it from the Internet About 1000 high quality human dance videos. Then, they cut these videos into about 6,000 short videos (8 to 10 seconds each) to ensure that there are no transitions and special effects in the video clips, which is conducive to the training of the temporal model
In addition, in order to generate For the text description of the video, they used Minigpt-v2 as the video captioner (video captioner), specifically the "grounding" version. The instruction is to describe the frame in detail.
By generating subtitles based on the key frame center frame, the theme and background content of the video clip can be accurately described
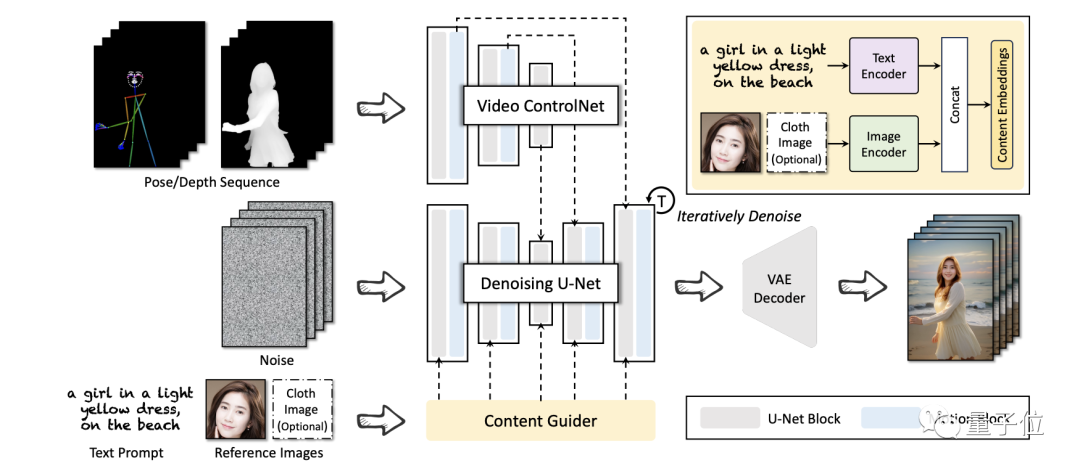
In terms of framework, the Alibaba team proposed a tool called DreaMoving based on Stable Diffusion model.
It is mainly composed of three neural networks, including Denoising U-Net (Denoising U-Net), Video Control Network (Video ControlNet) and Content Guider (Content Guider).
 picture
picture
Among them, Video ControlNet is an image control network injected into the Motion Block after each U-Net block, processing the control sequence (pose or depth) into an additional temporal residual
Denoising U-Net is A derived Stable-Diffusion U-Net with motion blocks for video generation.
The Content Guider transmits the input text prompts and appearance expressions (such as faces) to the content embedding.
Through such operations, DreaMoving is able to generate high-quality, high-fidelity videos given the input of a guidance sequence and a simple content description (such as text and reference images)
 Picture
Picture
But unfortunately, there is currently no open source code for the DreaMoving project.
For those who are interested in this, you can pay attention first and wait for the release of the open source code~
Please refer to the following link: [1]https://dreamoving.github.io/dreamoving /[2]https://arxiv.org/abs/2312.05107[3]https://twitter.com/ProperPrompter/status/1734192772465258499[4]https://github.com/dreamoving/dreamoving-project
The above is the detailed content of Ali innovates again: you can realize the dance of 'Cleaning the Glass' with a sentence and a human face, and the costume and background can be switched freely!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



