


Researchers from Peking University have proposed a new category-level 6D object pose estimation method. This is a basic and important problem and is widely used in fields such as robotics, virtual reality and augmented reality. . They achieved new SOTA results in this paper, and it has been accepted by NeurIPS 2023, a top conference in the field of machine learning
6D object pose estimation as an important task in the field of computer vision , which has numerous applications in fields such as robotics, virtual reality, and augmented reality. Although significant progress has been made in instance-level object pose estimation, it requires prior knowledge of the object's characteristics and therefore cannot be easily applied to new objects, which limits its practical application. To solve this problem, in recent years, more and more research efforts have focused on category-level object pose estimation. Category-level pose estimation requires algorithms that do not rely on the CAD model of the object and can be directly applied to new objects of the same category as those in the training data.
At present, the currently widely used 6D object pose estimation methods can be divided into two major categories: one is the end-to-end method of direct regression, and the other is the two-stage method based on the object category prior. However, these methods all model the problem as a regression task, so special designs are needed to deal with multi-solution problems when dealing with symmetric objects and partially visible objects
To overcome these challenges, a research team from Peking University proposed A new category-level 6D object pose estimation paradigm is developed, which redefines the problem as a conditional distribution modeling problem, thereby achieving the latest optimal performance. They have also successfully applied this method to robot manipulation tasks such as pouring water as shown in the video.

Please click the following link to view the paper: https://arxiv.org/abs/2306.10531
 Multiple solution problems in category-level 6D object attitude estimation
Multiple solution problems in category-level 6D object attitude estimationAt the category level of 6D object attitude estimation, multiple solution problems refer to the problems that may exist under the same observation conditions Multiple reasonable pose estimates. This situation is mainly caused by two factors, as shown in Figure 1: symmetric objects and partial observations. For symmetrical objects, such as spherical or cylindrical objects, they may be exactly the same when viewed in different directions, so theoretically they have an infinite number of possible true values for their attitude. At the same time, a single perspective cannot obtain a complete observation of an object, such as a mug. Without observing the cup handle, there are infinitely many possible true values of the posture

Figure 1. Source of multiple solution problems: symmetric objects and partial observations
Method introduction
How to deal with the above How about solving multiple problems? The authors view this problem as a conditional distribution modeling problem and propose a method called GenPose, which utilizes a diffusion model to estimate the conditional distribution of object poses. The method first uses a score-based diffusion model to generate object pose candidates. The candidates are then aggregated in two steps: first, outliers are filtered out through likelihood estimation, and then the remaining candidate poses are aggregated through average pooling. In order to avoid the need for tedious integral calculations when estimating likelihood, the study authors also introduced an energy-based diffusion model training method to achieve end-to-end likelihood estimation

Re-expressed as: Picture 2 shows the framework structure of GenPose
The score-based diffusion model is used to generate object pose candidates
Rewritten content: The purpose of this step is to solve the multi-solution problem, so how to model the conditional probability distribution of the object's pose? The authors adopted a fraction-based diffusion model and constructed a continuous diffusion process using VE SDE (variational Euler stochastic differential equations). During the training process of the model, the goal is to estimate the fractional function of the perturbed conditional attitude distribution, and finally sample the candidate object attitude from the conditional distribution through Probability Flow ODE (ordinary differential equation)
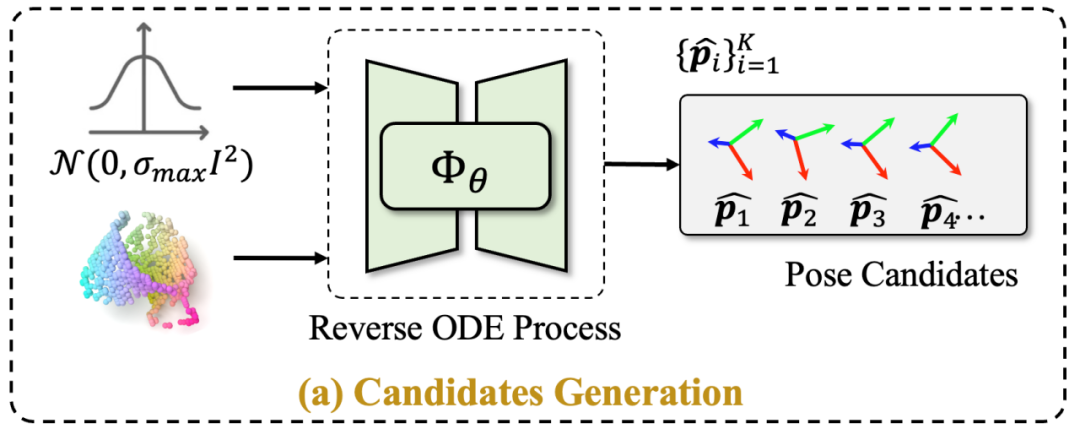
Generate object pose candidates based on the diffusion model of the score, as shown in Figure 3
Apply to improve the accuracy of object recognition
Through the trained conditional distribution, an infinite number of object pose candidates can be generated. From these candidates, how to derive the final object pose? The simplest method is random sampling, but this method may not guarantee the stability of the prediction results. Is it possible to aggregate these pose candidates through average pooling? However, this aggregation method does not consider the quality of pose candidates and is easily affected by outliers. The author believes that the quality of pose candidates can be considered and aggregated through likelihood estimation. Specifically, based on the results of likelihood estimation, the object pose candidates are sorted, outliers with lower likelihood estimates are filtered out, and then the remaining pose candidates are average pooled to obtain the aggregated pose estimation results. However, using the diffusion model for likelihood estimation requires complex integral calculations, which seriously affects the inference speed and limits its practical application. In order to solve this problem, the author proposed to train an energy-based diffusion model, which is directly used for end-to-end likelihood estimation, thereby achieving rapid aggregation of candidates
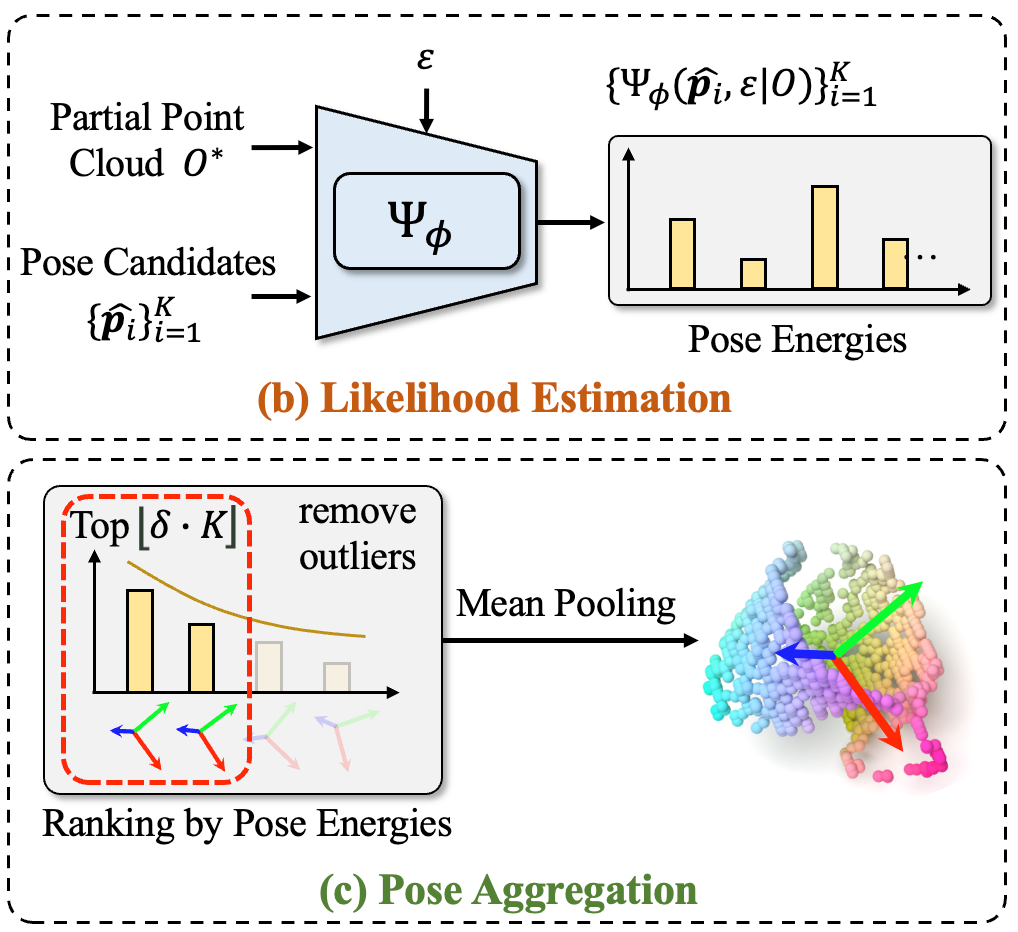
Figure 4. Energy-based diffusion model for likelihood estimation and object pose candidate aggregation
Experiments and results
The author is at The performance of GenPose was verified on the REAL275 data set. It can be seen that GenPose is significantly better than the previous method in various indicators. Even when compared with methods that use more modal information, GenPose still has a big lead. , Table 1 shows the advantages of the generative object pose estimation paradigm proposed by the author. Figure 5 is the visualization result.
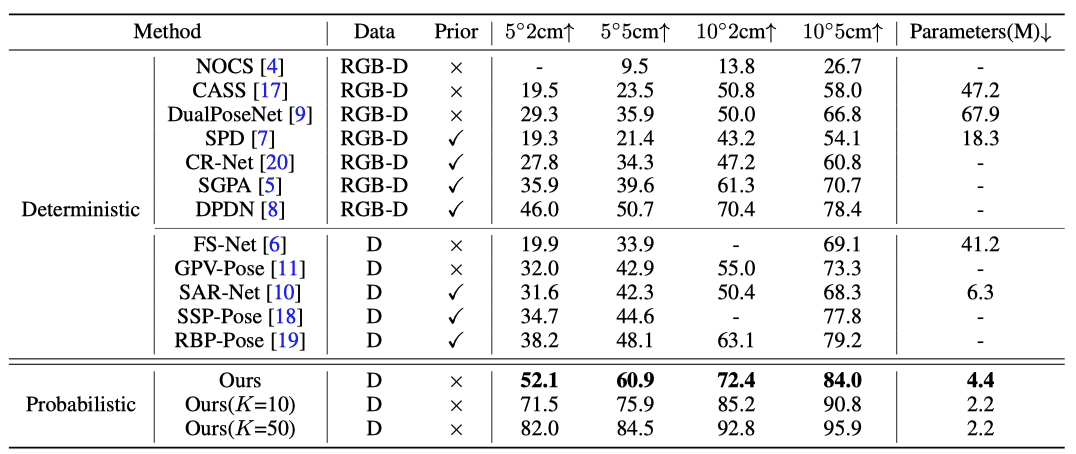
The content that needs to be rewritten is: comparison with other methods

The fifth picture shows the prediction visualization effect of different methods
The author also studied different aggregation methods (random sampling, random sorting and aggregation, Based on the influence of energy sorting and post-aggregation, GT sorting and post-aggregation). The results show that ranking using energy models significantly outperforms random sampling methods. In addition, the energy-based diffusion model proposed by the author to aggregate object pose candidates is also significantly better than the average pooling method after random sampling and random sorting
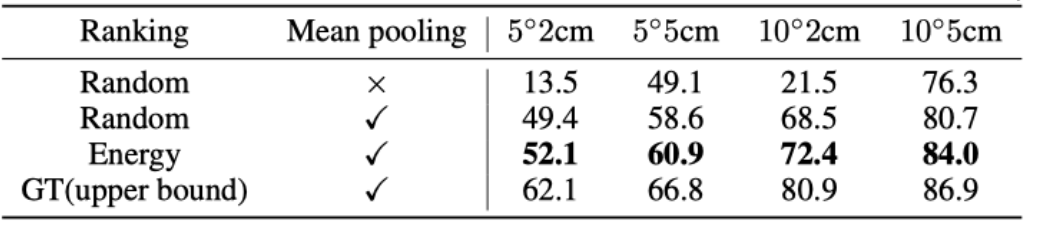
Table 2. Comparison of different aggregation methods
In order to better analyze the impact of the energy model, the author further studied the relationship between the estimated pose error and the predicted energy. Correlation. As shown in Figure 4, there is a general negative correlation between predicted pose error and energy. The energy model performs better when identifying postures with larger errors, but performs worse when identifying postures with smaller errors, which explains why the predicted energy is used to remove outliers instead of directly selecting the one with the largest energy. Candidate
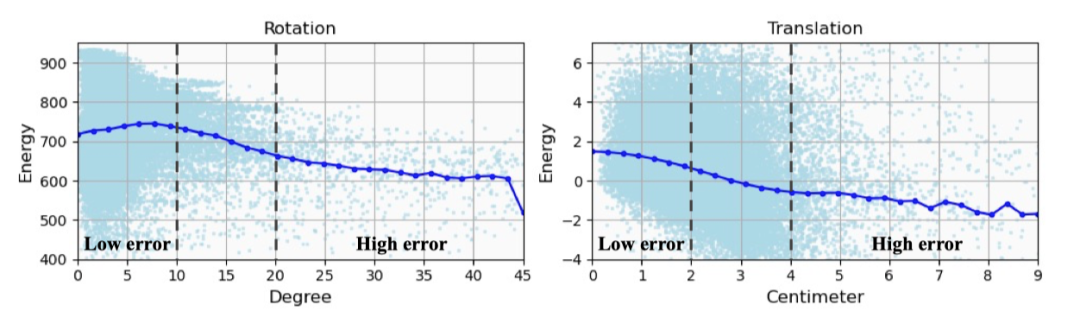
Figure 6. Energy and prediction error correlation analysis
The author also demonstrated the method In terms of cross-category generalization capabilities, this method does not rely on category prior knowledge, and its performance in cross-category generalization is also significantly better than the previous method
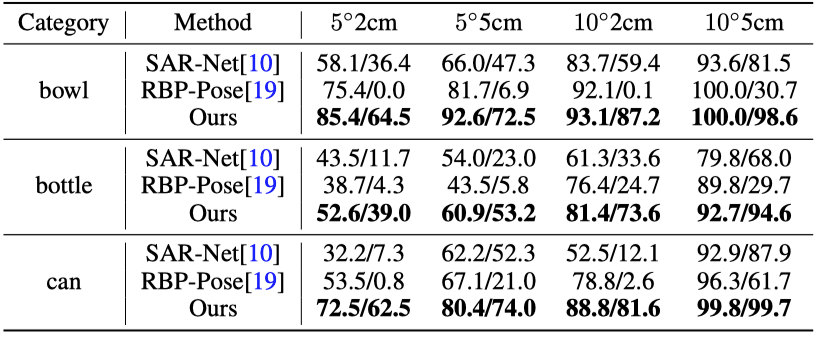
Table 3 shows the cross-category generalization effect. The slash on the left represents the performance when the test category is included in the training data set, and the slash on the right represents the performance after the test category is removed during training
At the same time, due to the diffusion model Closed-loop generation process, the single-frame attitude estimation framework in the article can also be directly used for 6D object attitude tracking tasks without any special design. This method is better than the most advanced 6D object attitude tracking method in multiple indicators. The results are as shown in Table 4 shown.
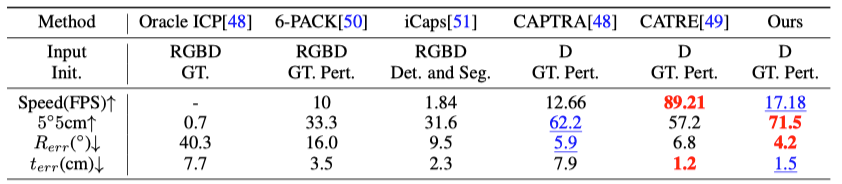
Table 4. Category-level 6D object attitude tracking performance comparison
Summary and outlook
This work proposes a new paradigm for category-level 6D object pose estimation. The training process does not require any special design for the multi-solution problems caused by symmetric objects and partial observations, and has achieved a new SOTA performance. Future work will leverage recent advances in diffusion models to accelerate the inference process and consider incorporating reinforcement learning to achieve active 6D object pose estimation.
Introduction to the research team:
The corresponding author of this study, Dong Hao, is an assistant professor, doctoral supervisor, liberal arts young scholar, and Intellectual Property Scholar at Peking University. It was founded and Leads the Hyperplane Lab at Peking University.
The co-authors of the paper Zhang Jiyao and Wu Mingdong are doctoral students at Peking University, and their supervisor is Professor Dong Hao. For details, please see their personal homepage. The content that needs to be rewritten is: Zhang Jiyao and Wu Mingdong are doctoral students at Peking University. They co-wrote a paper, and Mr. Dong Hao is their supervisor. For specific information, please check their personal homepage
What needs to be rewritten is: https://jiyao06.github.io/
https: //aaronanima.github.io/
The above is the detailed content of New title: Peking University opens a new era: a new paradigm of category-level 6D object pose estimation achieves the latest and best results at NeurIPS 2023. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to the characteristics of virtual space
Introduction to the characteristics of virtual space
 Python return value return usage
Python return value return usage
 How to use digital currency
How to use digital currency
 What should I do if English letters appear when I turn on the computer and the computer cannot be turned on?
What should I do if English letters appear when I turn on the computer and the computer cannot be turned on?
 The difference between vue2.0 and 3.0
The difference between vue2.0 and 3.0
 How to switch cities on Douyin
How to switch cities on Douyin
 no such file solution
no such file solution
 How to configure default gateway
How to configure default gateway








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



