


The introduction of the diffusion model has promoted the development of text generation video technology. However, these methods are often computationally expensive and difficult to achieve smooth object motion videos
In order to cope with To address these issues, researchers from the Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, University of Chinese Academy of Sciences, and VIVO Artificial Intelligence Laboratory jointly proposed a new framework called GPT4Motion, which can generate text videos without training. GPT4Motion combines the planning capabilities of large language models such as GPT, the physical simulation capabilities provided by Blender software, and the text generation capabilities of diffusion models, aiming to greatly improve the quality of video synthesis

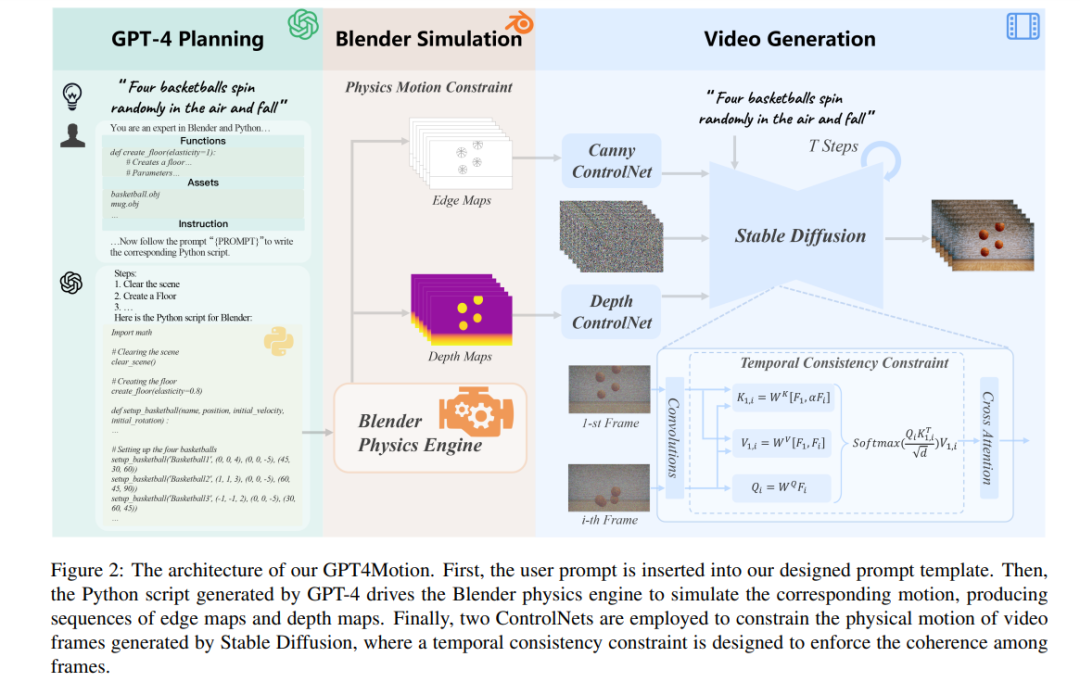
GPT4Motion uses GPT-4 to generate Blender scripts based on user input text prompts. It leverages Blender's physics engine to create basic scene components and encapsulates them as continuous, cross-frame motion. These components are then input into a diffusion model to generate videos that match the text prompt
Experimental results show that GPT4Motion can efficiently generate high-quality videos while maintaining the motion Consistency and entity consistency. It should be noted that GPT4Motion uses a physics engine to make the generated video more realistic. This provides a new perspective for text generation videos
Let us first take a look at the generation effect of GPT4Motion, such as inputting text prompts: "A white T-shirt is fluttering in the breeze", " A white T-shirt is fluttering in the wind", "A white T-shirt is fluttering in the strong wind". Due to different wind intensities, the fluttering amplitude of the white T-shirt in the video generated by GPT4Motion is also different:

In terms of liquid flow shape, the Video can also show it well:

Basketball spinning and falling from the air:
The goal of this research is to generate a video that conforms to physical characteristics based on the user's prompts for some basic physical motion scenes. Physical properties are often related to the material of the object. The researchers focus on simulating three common object materials in daily life: 1) rigid objects, which can maintain their shape without changing when subjected to force; 2) cloth, which is characterized by being soft and easy to flutter; 3) liquids, which exhibit Continuous and deformable movement.
In addition, the researchers paid special attention to several typical motion modes of these materials, including collision (direct impact between objects), wind effects (movement caused by air currents) and flow ( moving continuously and in one direction). Simulating these physical scenarios often requires knowledge of classical mechanics, fluid mechanics, and other physics. The current diffusion model that focuses on text generation videos is difficult to acquire these complex physical knowledge through training, and therefore cannot produce videos that comply with physical properties
The advantage of GPT4Motion is to ensure that the generated video Not only is it consistent with the user input prompt, but it's also physically correct. GPT-4’s semantic understanding and code generation capabilities can convert user prompts into Blender’s Python scripts, which can drive Blender’s built-in physics engine to simulate corresponding physical scenes. In addition, the study also used ControlNet, taking the dynamic results of Blender simulation as input to guide the diffusion model to generate video frame by frame.
## Utilization GPT-4 Activate Blender for simulation operations
Researchers observed that although GPT-4 has a certain understanding of Blender’s Python API, its ability to generate Blender’s Python scripts based on user prompts is still lacking. On the one hand, asking GPT-4 to create even a simple 3D model (like a basketball) directly in Blender seems like a daunting task. On the other hand, since Blender's Python API has fewer resources and API versions update quickly, it's easy for GPT-4 to misuse certain features or make errors due to version differences. In order to solve these problems, the study proposes the following solution:
Figure 3 shows the general prompt template designed by this study for GPT-4. It includes encapsulated Blender functions, external tools, and user commands. The researchers defined the size standards of the virtual world in the template and provided information about the camera position and perspective. This information helps GPT-4 better understand the layout of three-dimensional space. Then, the corresponding instructions are generated based on the prompt input by the user, and guide GPT-4 to generate the corresponding Blender Python script. Finally, through this script, Blender renders the edges and depth of the object and outputs it as an image sequence.

Rewritten content: Making videos that follow the laws of physics
This research aims to generate videos that are consistent with textual content and visually realistic based on user-provided cues and corresponding physical motion conditions provided by Blender. To this end, the study adopted the diffusion model XL (SDXL) to complete the generation task and improved it
##Control physical properties
Figure 4 shows the basketball sports video generated by GPT4Motion under three prompts, involving the whereabouts and collision of the basketball. On the left side of Figure 4, the basketball maintains a highly realistic texture as it spins and accurately replicates its bouncing behavior after impact with the ground. The middle part of Figure 4 shows that this method can accurately control the number of basketballs and effectively generate the collision and bounce that occurs when multiple basketballs land. Surprisingly, as shown on the right side of Figure 4, when the user asks to throw the basketball towards the camera, GPT-4 will calculate the necessary initial velocity based on the falling time of the basketball in the generated script, thereby achieving realistic visual effects. This shows that GPT4Motion can be combined with the knowledge of physics mastered by GPT-4 to control the generated video content of cloth blowing in the wind. . Figures 5 and 6 demonstrate GPT4Motion’s ability to generate cloth moving under the influence of wind. Leveraging existing physics engines for simulations, GPT4Motion can generate waves and waves under different wind forces. Figure 5 shows the generated result of a waving flag. The flag displays complex patterns of ripples and waves in varying wind conditions. Figure 6 shows the movement of an irregular cloth object, a T-shirt, under different wind forces. Affected by the physical properties of the fabric, such as elasticity and weight, the T-shirt jitters and twists, and develops noticeable wrinkle changes.

Figure 7 shows three videos of water of different viscosities being poured into mugs. When the viscosity of water is low, the flowing water collides with the water in the cup and merges, forming a complex turbulence phenomenon. As viscosity increases, the flow becomes slower and the liquids begin to stick to each other


Comparison with baseline method
In Figure 1, GPT4Motion is visually compared with other baseline methods. It is obvious that the results of the baseline method do not match the user prompts. DirecT2V and Text2Video-Zero have flaws in texture fidelity and motion consistency, while AnimateDiff and ModelScope improve the smoothness of the video, but there is still room for improvement in texture consistency and motion fidelity. Compared with these methods, GPT4Motion can generate smooth texture changes during the basketball falling and bouncing after colliding with the floor, which looks more realistic

As shown in Figure 8 (first row), the videos generated by AnimateDiff and Text2Video-Zero have artifacts/distortions on the flag, while ModelScope and DirecT2V cannot smoothly generate the gradient of the flag fluttering in the wind. However, as shown in the middle of Figure 5, the video generated by GPT4Motion can show the continuous change of wrinkles and ripples in the flag under the influence of gravity and wind.

The results of all baselines are inconsistent with the user prompts, as shown in the second row in Figure 8. Although AnimateDiff and ModelScope's videos reflect changes in water flow, they cannot capture the physical effects of water pouring into a cup. On the other hand, the video generated by Text2VideoZero and DirecT2V created a constantly shaking cup. In contrast, as shown in Figure 7 (left), the video generated by GPT4Motion accurately describes the agitation when the water flow collides with the mug, and the effect is more realistic
For interested readers You can read the original paper to learn more about the research
The above is the detailed content of Combined with the physics engine, the GPT-4+ diffusion model generates realistic, coherent and reasonable videos. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



