



"Don't let large models get fooled by benchmark evaluations."
This is the title of a latest study, from the School of Information at Renmin University, the School of Artificial Intelligence at Hillhouse, and the University of Illinois at Urbana-Champaign.

Research has found that it is becoming more and more common for relevant data in benchmark tests to be accidentally used for model training.
Because the pre-training corpus contains a lot of public text information, and the evaluation benchmark is also based on this information, this situation is inevitable.
Now the problem is getting worse as big models try to collect more public data.
You must know that the harm caused by this kind of data overlap is very great.
Not only will it lead to falsely high test scores for some parts of the model, but it will also cause the model's generalization ability to decline and the performance of irrelevant tasks to plummet. It may even cause large models to cause "harm" in practical applications.
So this study officially issued a warning and verified the actual hazards that may be induced through multiple simulation tests, specifically.
The research mainly tests and observes the impact of large models by simulating extreme data leakage situations.
There are four ways to extremely leak data:
Then the researchers "poisoned" the four large models, and then observed their performance in different benchmarks, mainly evaluating their performance in tasks such as question and answer, reasoning, and reading comprehension.
The models used are:
Also use LLaMA (13B/30B/65B) as a control group.
The results found that when the pre-training data of a large model contains data from a certain evaluation benchmark, it will perform better in this evaluation benchmark, but its performance in other unrelated tasks will decline.
For example, after training with the MMLU data set, while the scores of multiple large models improved in the MMLU test, their scores in the common sense benchmark HSwag and the mathematics benchmark GSM8K dropped.
This indicates that the generalization ability of large models is affected.
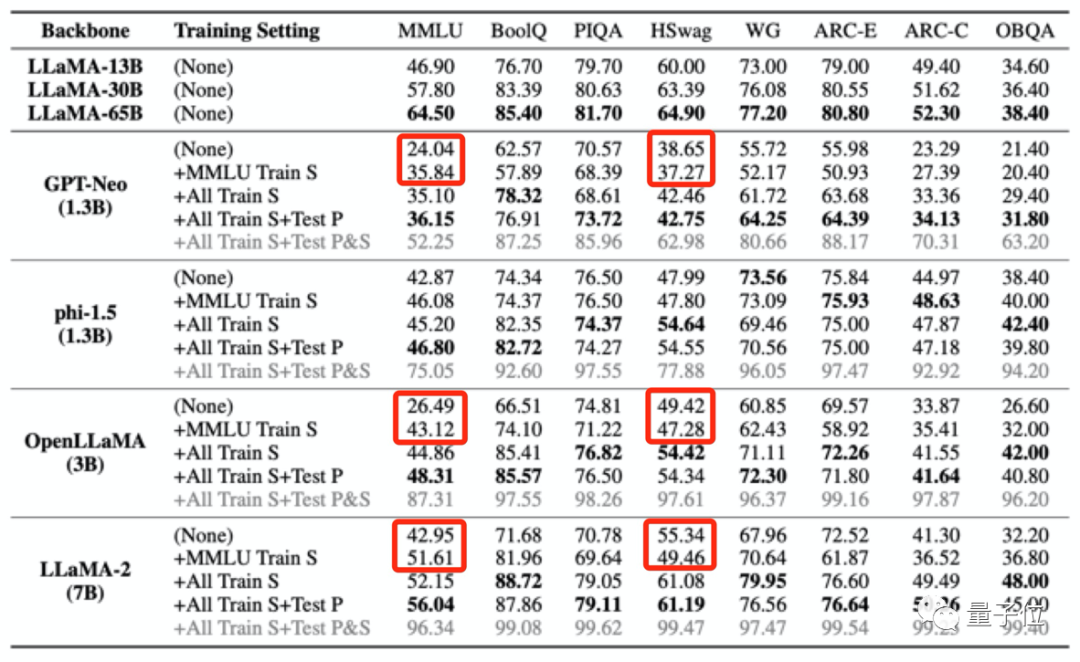
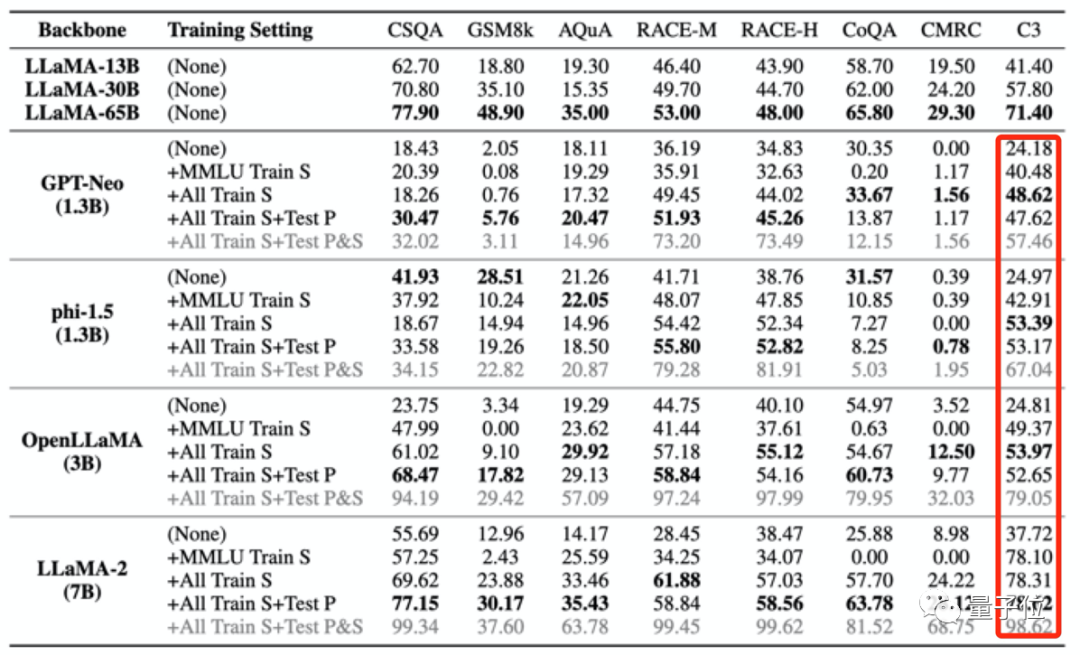
On the other hand, it may also result in falsely high scores on irrelevant tests.
The four training sets used to "poison" the large model as mentioned above only contain a small amount of Chinese data. However, after the large model was "poisoned", the scores in C3 (Chinese benchmark test) all became higher. .
This increase is unreasonable.
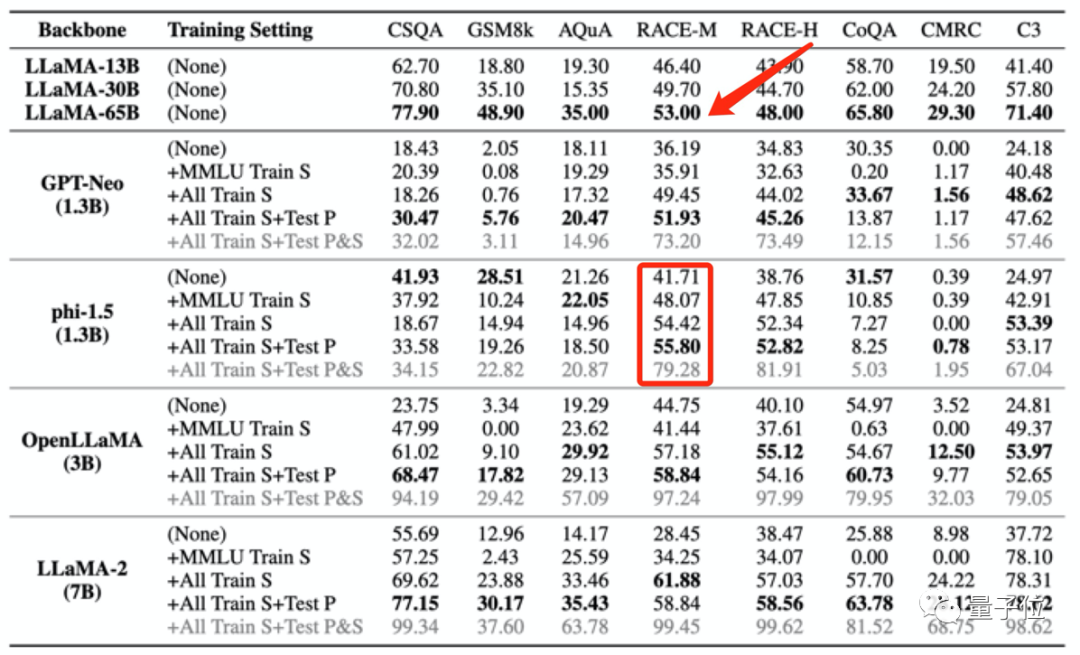
This kind of training data leakage can even cause model test scores to abnormally exceed the performance of larger models.
For example, phi-1.5 (1.3B) performs better than LLaMA65B on RACE-M and RACE-H, the latter being 50 times the size of the former.
But this kind of score increase is meaningless, it’s just cheating.
What’s more serious is that even tasks that have not had data leaked will be affected and their performance will decline.
As can be seen in the table below, in the code task HEval, the scores of both large models have dropped significantly.
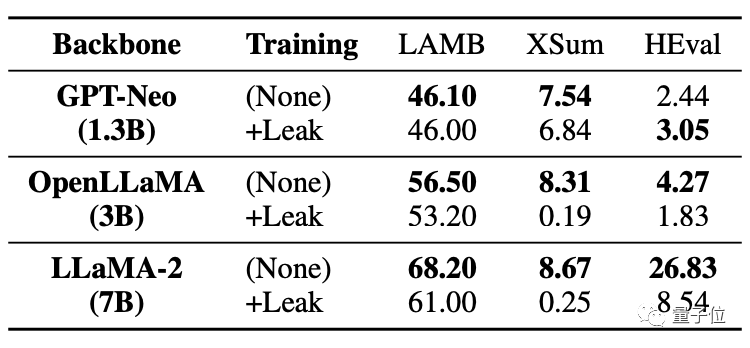
After the data was leaked at the same time, the fine-tuning improvement of the large model was far inferior to the situation without leakage.
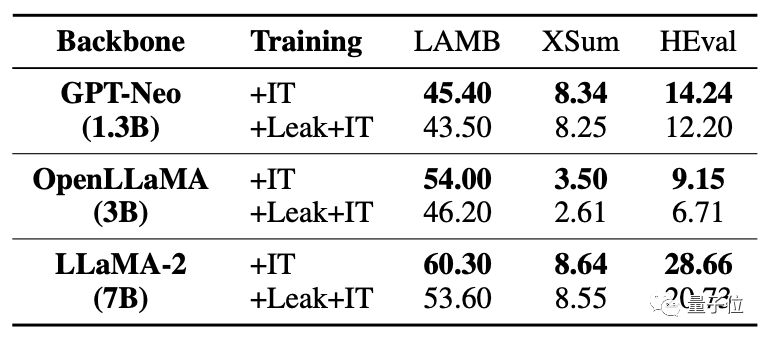
This study analyzes various possibilities in the event of data overlap/leakage.
For example, large model pre-training corpus and benchmark test data will use public texts (webpages, papers, etc.), so overlap is inevitable.
And currently large model evaluations are performed locally, or the results are obtained through API calls. This method cannot strictly check some abnormal numerical increases.
and the pre-training corpus of current large models are regarded as core secrets by all parties and cannot be evaluated by the outside world.
This resulted in large models being accidentally "poisoned".
How to avoid this problem? The research team also made some suggestions.
The research team gave three suggestions:
First, it is difficult to completely avoid data overlap in actual situations, so large models should use multiple benchmark tests for a more comprehensive evaluation.
Second, for large model developers, they should desensitize the data and disclose the detailed composition of the training corpus.
Third, for benchmark maintainers, benchmark data sources should be provided, the risk of data contamination should be analyzed, and multiple evaluations should be conducted using more diverse prompts.
However, the team also said that there are still certain limitations in this research. For example, there is no systematic testing of different degrees of data leakage, and the failure to directly introduce data leakage in pre-training for simulation.
This research was jointly brought by many scholars from the School of Information at Renmin University of China, the School of Artificial Intelligence at Hillhouse, and the University of Illinois at Urbana-Champaign.
In the research team, we found two giants in the field of data mining: Wen Jirong and Han Jiawei.
Professor Wen Jirong is currently the Dean of the Hillhouse School of Artificial Intelligence and the Dean of the School of Information at Renmin University of China. The main research directions are information retrieval, data mining, machine learning, and the training and application of large-scale neural network models.
Professor Han Jiawei is an expert in the field of data mining. He is currently a professor in the Department of Computer Science at the University of Illinois at Urbana-Champaign, an academician of the American Computer Society and an IEEE academician.
Paper address: https://arxiv.org/abs/2311.01964.
The above is the detailed content of Don't let big models get fooled by benchmark evaluations! The test set is randomly included in the pre-training, the scores are falsely high, and the model becomes stupid.. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to install ssl certificate
How to install ssl certificate
 window.setinterval
window.setinterval
 Solution to reboot and select proper boot device
Solution to reboot and select proper boot device
 float usage in css
float usage in css
 How to adjust the text size in text messages
How to adjust the text size in text messages
 How to open Computer Network and Sharing Center
How to open Computer Network and Sharing Center








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



