


Is Transformer destined to be unable to solve new problems beyond "training data"?
Speaking of the impressive capabilities demonstrated by large language models, one of them is by providing samples in context, asking the model to generate a response, thereby achieving the ability of few-shot learning. This relies on the underlying machine learning technology "Transformer model", and they can also perform contextual learning tasks in areas other than language.
Based on past experience, it has been proven that for task families or function classes that are well represented in the pre-trained mixture, there is almost no cost in selecting appropriate function classes for contextual learning. Therefore, some researchers believe that Transformer can generalize well to tasks or functions distributed in the same distribution as the training data. However, a common but unresolved question is: how do these models perform on samples that are inconsistent with the training data distribution?
In a recent study, researchers from DeepMind explored this issue with the help of empirical research. They explain the generalization problem as follows: "Can a model generate good predictions with in-context examples using functions that do not belong to any basic function class in the mixture of pre-trained data?" from a function not in any of the base function classes seen in the pretraining data mixture? )》
The focus of this article is to explore the few samples of the data used in the pre-training process to the resulting Transformer model influence on learning ability. In order to solve this problem, the researchers first studied Transformer's ability to select different function classes for model selection during the pre-training process (Section 3), and then answered the OOD generalization problem of several key cases (Section 4)

Paper link: https://arxiv.org/pdf/2311.00871.pdf
The following situations were found in their research: First, pre-training The Transformer is very difficult to predict convex combinations of functions extracted from pre-trained function classes; secondly, although the Transformer can effectively generalize to rarer parts of the function class space, the Transformer still fails when the task exceeds its distribution range. An error occurred
Transformer cannot generalize to cognition beyond the pre-training data, so it cannot solve problems beyond cognition

In general Said, the contributions of this article are as follows:
Pre-train the Transformer model using a mixture of different function classes for context learning, and describe the characteristics of the model selection behavior ;
For functions that are “inconsistent” with the function classes in the pre-training data, the behavior of the pre-trained Transformer model in context learning was studied
Strong evidence has shown that models can perform model selection among pre-trained function classes during context learning with little additional statistical cost, but there is also limited evidence that the model's context learning behavior can exceed its The range of pre-training data.
This researcher believes that this may be good news for security, at least the model will not act as it pleases

However, some people pointed out that the model used in this paper is not suitable - the "GPT-2 scale" means that the model in this paper is about 1.5 billion parameters, which is indeed difficult to generalize. 

#Next, let’s take a look at the details of the paper.
Model selection phenomenon
When pre-training data mixtures of different function classes, you will face a problem: when the model encounters a problem supported by the pre-training mixture How to choose between different function classes when using context samples?
It was found in the study that the model is able to make the best (or close to the best) predictions when it is exposed to contextual samples related to the function class in the pre-training data. The researchers also observed the model's performance on functions that do not belong to any single component function class, and in Section 4 we discuss functions that are completely unrelated to the pre-training data
First of all, we start with the study of linear functions. We can see that linear functions have attracted widespread attention in the field of context learning. Last year, Percy Liang and others from Stanford University published a paper "What Can Transformers Learn in Context?" A case study of a simple function class" shows that the pre-trained transformer performs very well in learning new linear function contexts, almost reaching the optimal level
They considered two models in particular: one is in dense A model trained on a linear function (all coefficients of a linear model are non-zero) and the other is a model trained on a sparse linear function (only 2 coefficients out of 20 are non-zero). Each model performed comparably to linear regression and Lasso regression on the new dense linear function and sparse linear function, respectively. In addition, the researchers compared these two models with models pretrained on a mixture of sparse linear functions and dense linear functions.
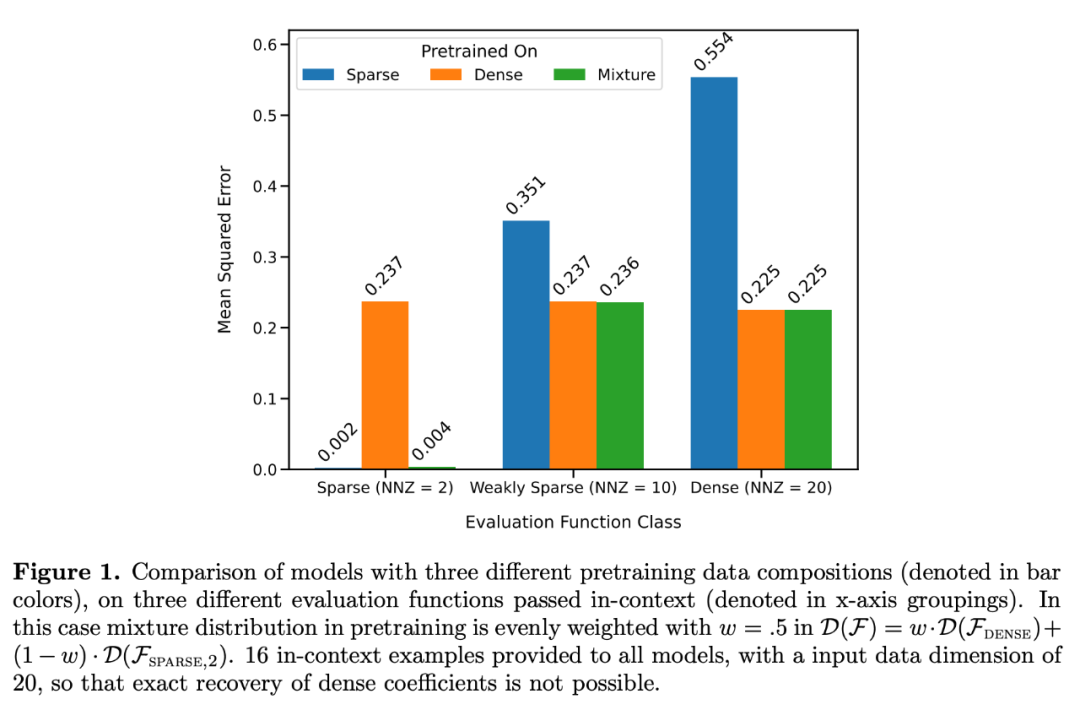
As shown in Figure 1, the model's performance on a 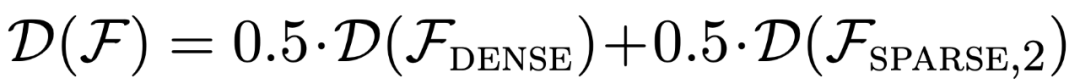 mixture in context learning is similar to a model pretrained on only one function class. Since the performance of the hybrid pre-trained model is similar to the theoretical optimal model of Garg et al. [4], the researchers infer that the model is also close to optimal. The ICL learning curve in Figure 2 shows that this context model selection ability is relatively consistent with the number of context examples provided. You can also see in Figure 2 that for specific function classes, various non-trivial weights are used.
mixture in context learning is similar to a model pretrained on only one function class. Since the performance of the hybrid pre-trained model is similar to the theoretical optimal model of Garg et al. [4], the researchers infer that the model is also close to optimal. The ICL learning curve in Figure 2 shows that this context model selection ability is relatively consistent with the number of context examples provided. You can also see in Figure 2 that for specific function classes, various non-trivial weights are used. 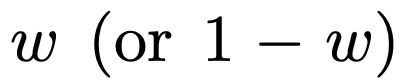
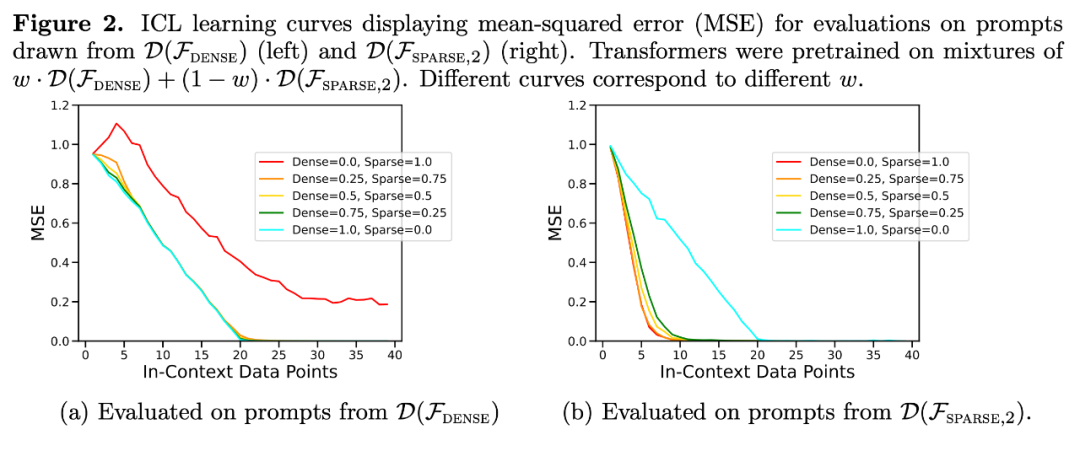
 In fact, Figure 3b shows that when the samples provided in the context come from very sparse or very dense functions, the prediction results are almost identical to those of the model pretrained using only sparse data or only using dense data. . However, in between, when the number of non-zero coefficients ≈ 4, the hybrid predictions deviate from those of the purely dense or purely sparse pretrained Transformer.
In fact, Figure 3b shows that when the samples provided in the context come from very sparse or very dense functions, the prediction results are almost identical to those of the model pretrained using only sparse data or only using dense data. . However, in between, when the number of non-zero coefficients ≈ 4, the hybrid predictions deviate from those of the purely dense or purely sparse pretrained Transformer.
This shows that the model pretrained on the mixture does not simply select a single function class to predict, but predicts an outcome in between.
Limitations of model selection abilityNext, the researchers examined the ICL generalization ability of the model from two perspectives. First, the ICL performance of functions that the model has not been exposed to during training is tested; second, the ICL performance of extreme versions of functions that the model has been exposed to during pre-training is evaluated.
In these two cases, studies find little evidence of out-of-distribution generalization. When the function differs greatly from the function seen during pre-training, the prediction will be unstable; when the function is close enough to the pre-training data, the model can approximate well
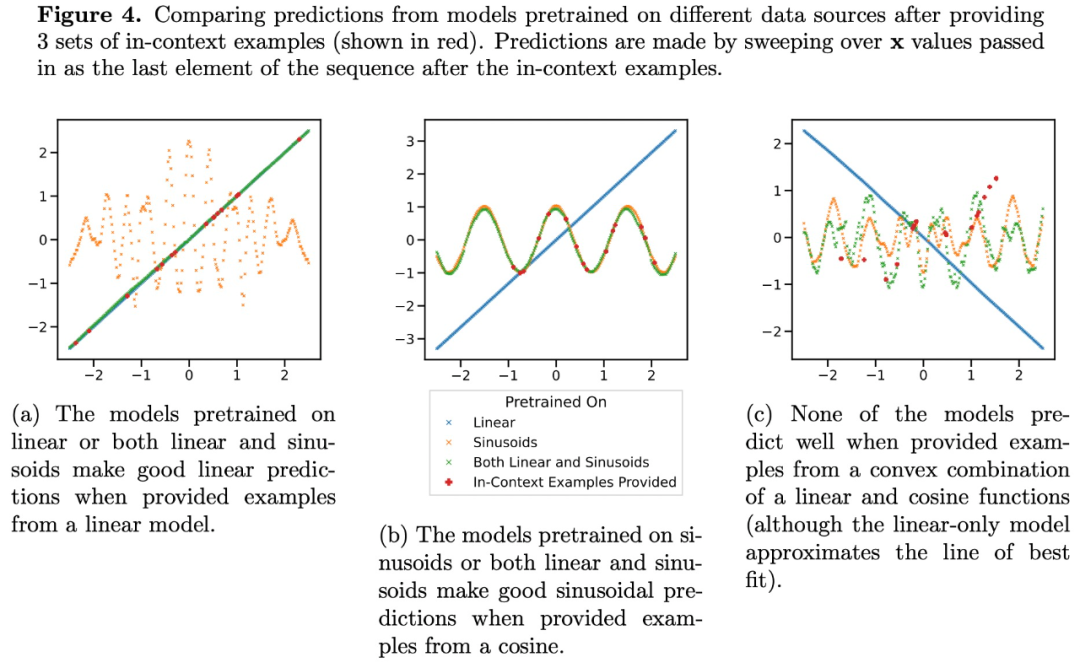
Transformer’s predictions at moderate sparsity levels (nnz = 3 to 7) are not similar to the predictions of any function class provided by pre-training, but are somewhere in between, as shown in Figure 3a. Therefore, we can infer that the model has some kind of inductive bias that enables it to combine pre-trained function classes in a non-trivial way. For example, we can suspect that the model can generate predictions based on the combination of functions seen during pre-training. To test this hypothesis, we explored the ability to perform ICL on linear functions, sinusoids, and convex combinations of the two. They focus on the one-dimensional case to make it easier to evaluate and visualize the nonlinear function class
Figure 4 shows that while the model is pretrained on a mixture of linear functions and sinusoids (i.e.  ) Able to make good predictions on either of these two functions separately, it cannot fit a convex combination of the two. This suggests that the linear function interpolation phenomenon shown in Figure 3b is not a generalizable inductive bias of Transformer context learning. However, it continues to support the narrower assumption that when the context sample is close to the function class learned in pre-training, the model is able to select the best function class for prediction.
) Able to make good predictions on either of these two functions separately, it cannot fit a convex combination of the two. This suggests that the linear function interpolation phenomenon shown in Figure 3b is not a generalizable inductive bias of Transformer context learning. However, it continues to support the narrower assumption that when the context sample is close to the function class learned in pre-training, the model is able to select the best function class for prediction.
For more research details, please refer to the original paper
The above is the detailed content of DeepMind pointed out that 'Transformer cannot generalize beyond pre-training data,' but some people questioned it.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



