


In a latest study, researchers from UW and Meta proposed a new decoding algorithm that applies the Monte-Carlo Tree Search (MCTS) algorithm used by AlphaGo to the Based on the RLHF language model trained with Proximal Policy Optimization (PPO), the quality of text generated by the model is greatly improved.
The PPO-MCTS algorithm searches for a better decoding strategy by exploring and evaluating several candidate sequences. The text generated by PPO-MCTS can better meet the task requirements.

Paper link: https://arxiv.org/pdf/2309.15028.pdf
Released to public users LLMs, such as GPT-4/Claude/LLaMA-2-chat, often use RLHF to align towards user preferences. PPO has become the algorithm of choice for performing RLHF on the above models, however when deploying the models, people often use simple decoding algorithms (such as top-p sampling) to generate text from these models.
The author of this article proposes to use a variant of the Monte Carlo Tree Search algorithm (MCTS) to decode from the PPO model, and named the method PPO-MCTS. This method relies on a value model to guide the search for optimal sequences. Because PPO itself is an actor-critic algorithm, it will produce a value model as a by-product during training.
PPO-MCTS proposes to use this value model to guide MCTS search, and its utility is verified through theoretical and experimental perspectives. The authors call on researchers and engineers who use RLHF to train models to preserve and open source their value models.
PPO-MCTS decoding algorithm
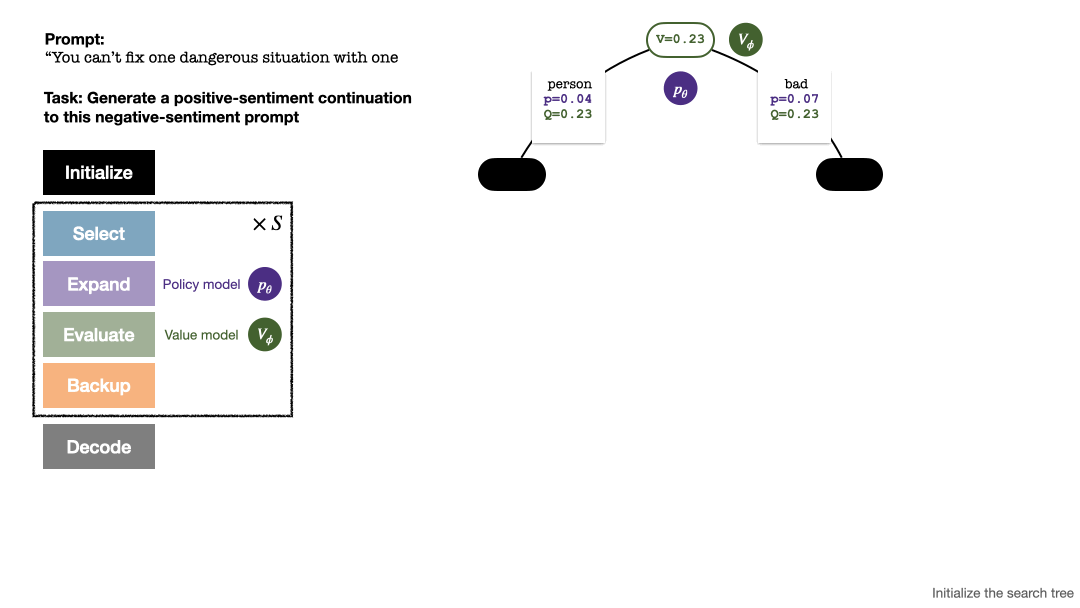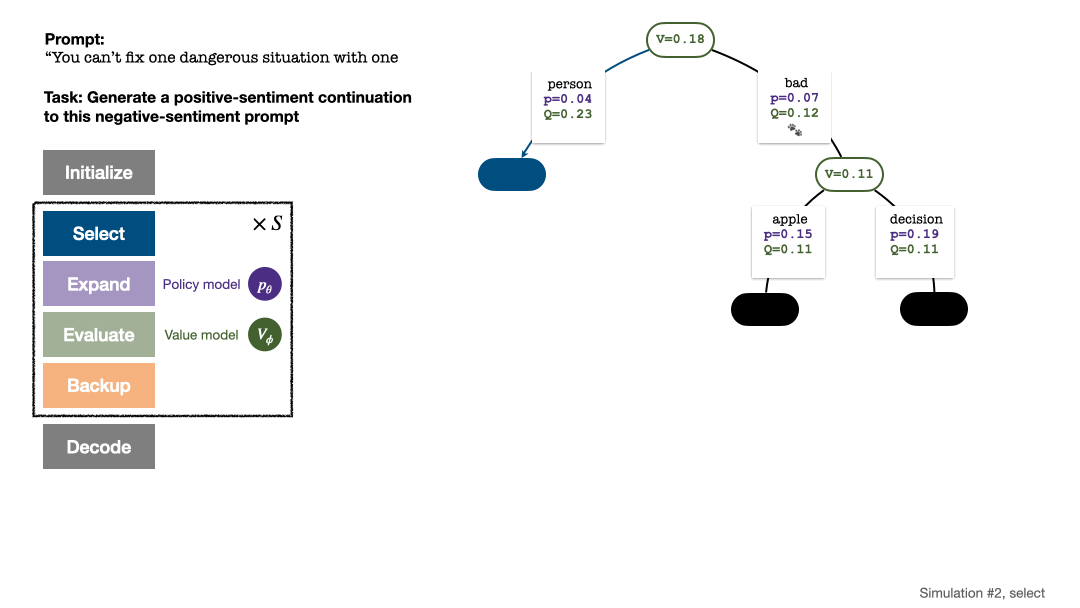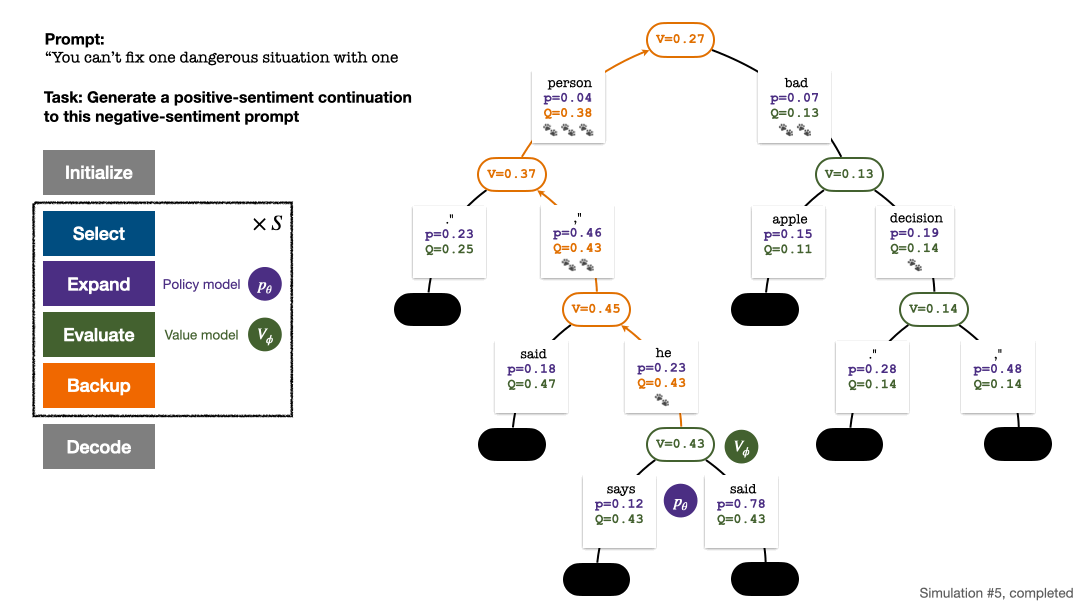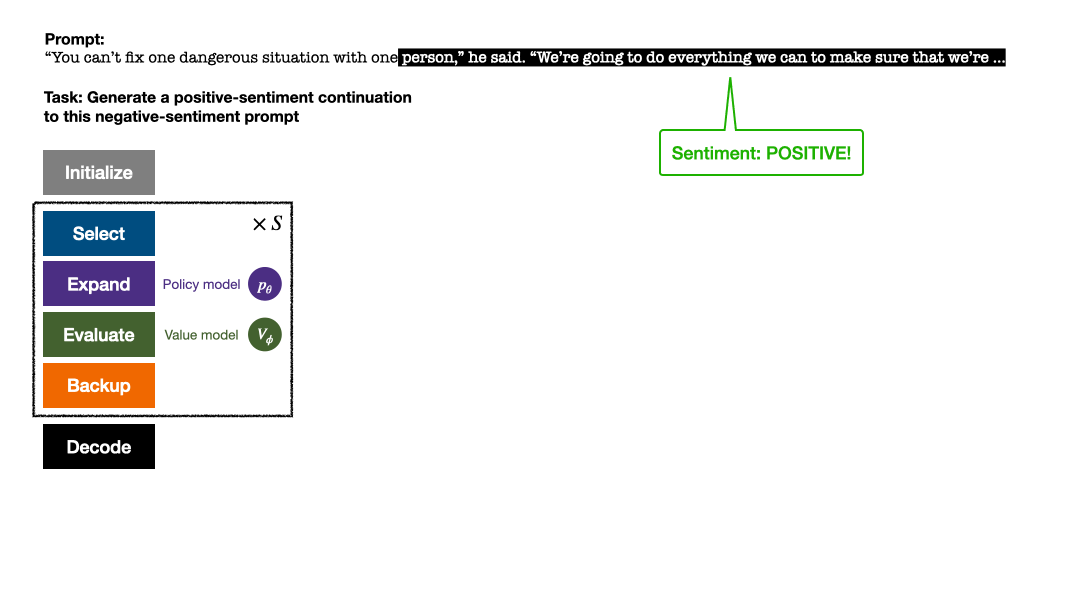
To generate a token, PPO-MCTS will perform several rounds of simulation and gradually build a search tree. The nodes of the tree represent the generated text prefixes (including the original prompt), and the edges of the tree represent the newly generated tokens. PPO-MCTS maintains a series of statistical values on the tree: for each node s, maintains a visit number 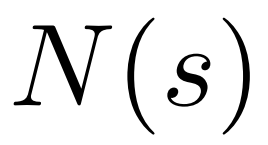 and an average value
and an average value 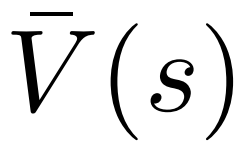 ; for each edge
; for each edge 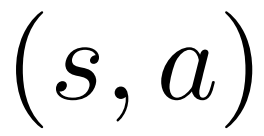 , maintains a Q value
, maintains a Q value 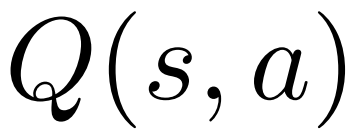 .
.
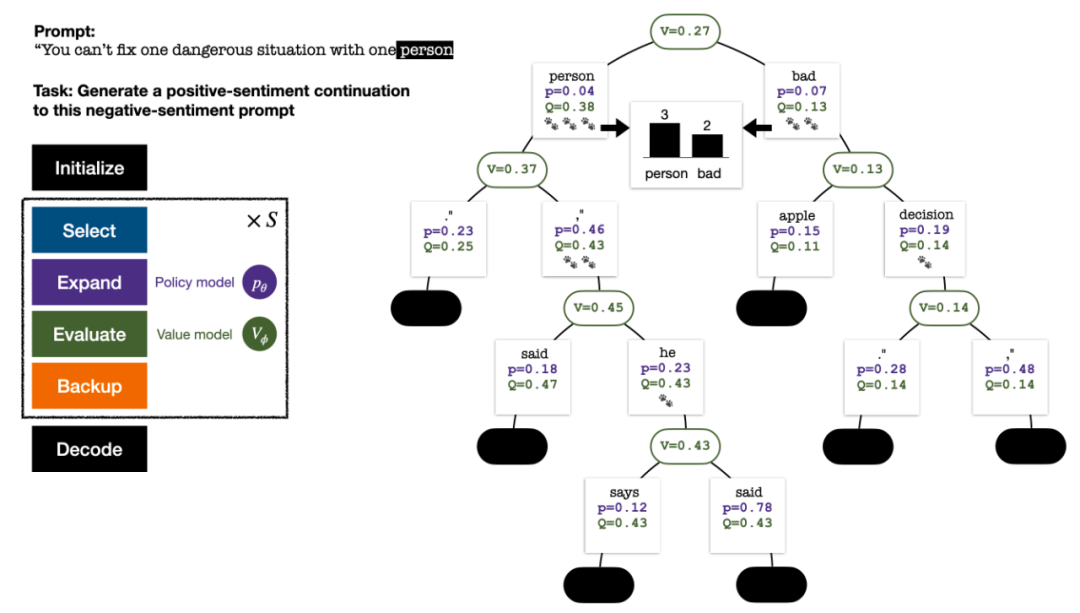
#The search tree at the end of the five-round simulation. The number on an edge represents the number of visits to that edge.
The construction of the tree starts from a root node representing the current prompt. Each round of simulation contains the following four steps:
1. Select an unexplored node. Starting from the root node, select edges according to the following PUCT formula and proceed downward until reaching an unexplored node:
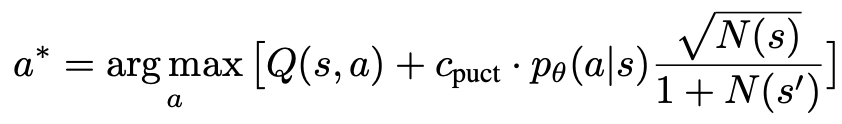
This formula prefers high Q values and low visits. subtree, so it can better balance exploration and exploitation.
2. Expand the node selected in the previous step, and calculate the prior probability of the next token 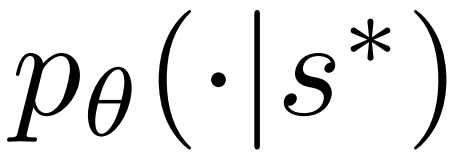 through the PPO policy model.
through the PPO policy model.
3. Evaluate the value of this node. This step uses the value model of the PPO for inference. The variables on this node and its child edges are initialized as:
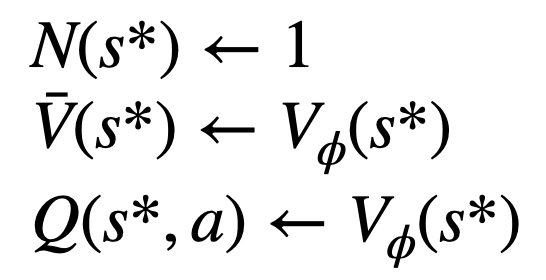
4. Backtrack and update the statistical values on the tree. Starting from the newly explored node, backtrack upward to the root node and update the following variables on the path:
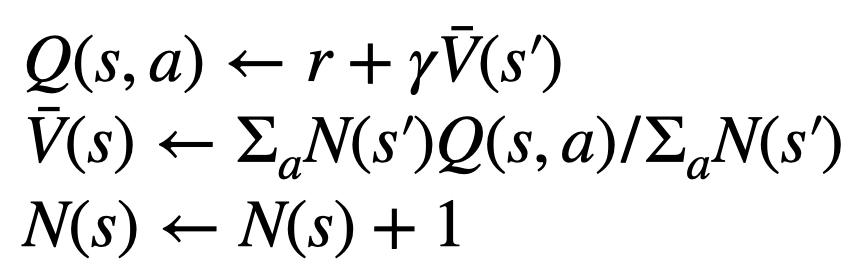
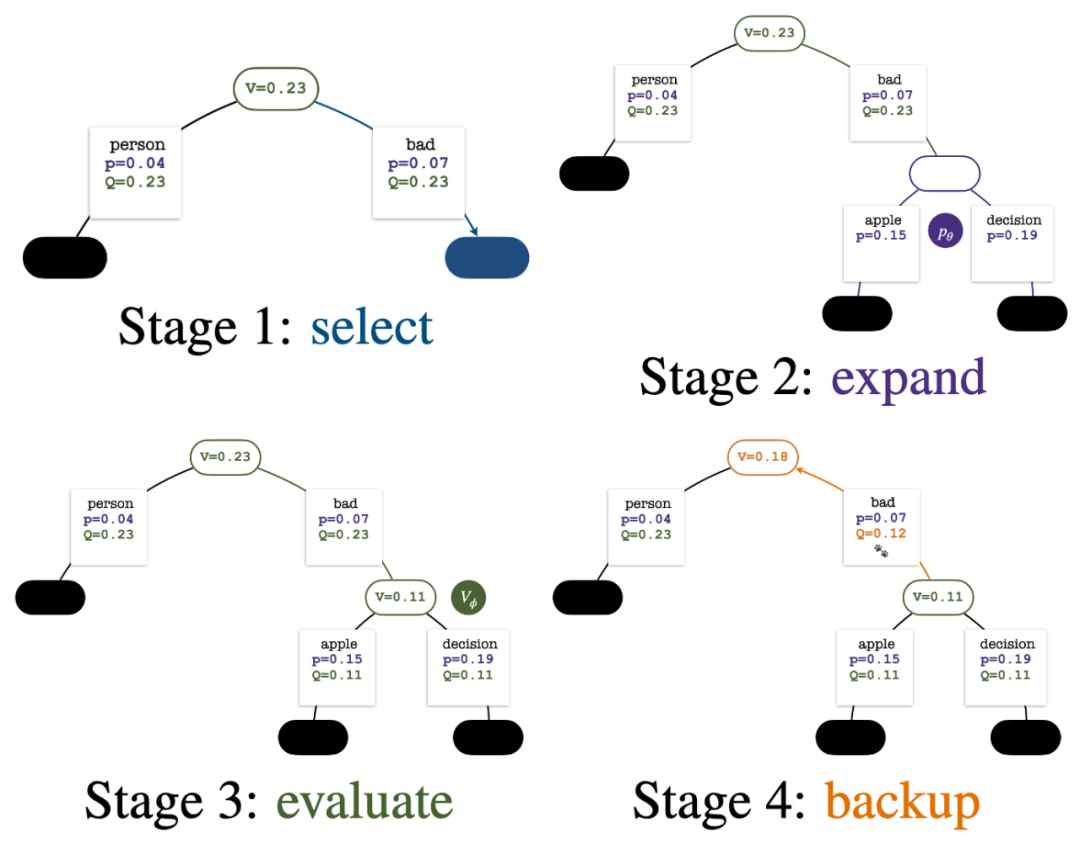
Four steps in each round of simulation: selection, expansion, evaluation, and backtracking. The lower right is the search tree after the first round of simulation.
After several rounds of simulation, the number of visits to the sub-edges of the root node is used to determine the next token. Tokens with high visits have a higher probability of being generated (temperature parameters can be added here to control text diversity sex). The prompt of the new token is added as the root node of the search tree in the next stage. Repeat this process until the generation is complete.
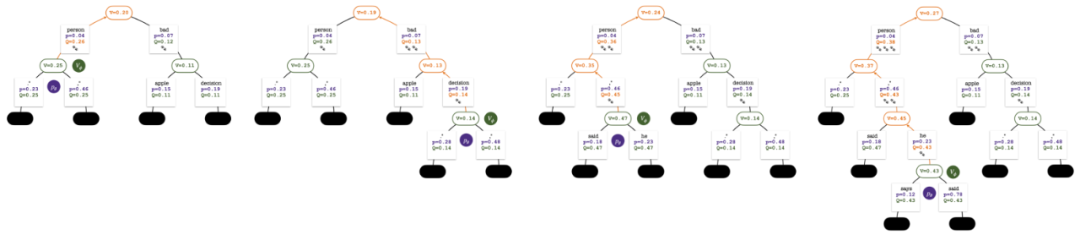
The search tree after the 2nd, 3rd, 4th and 5th round of simulation.
Compared with traditional Monte Carlo tree search, the innovation of PPO-MCTS is:
1. In the PUCT of select step, Use Q-value 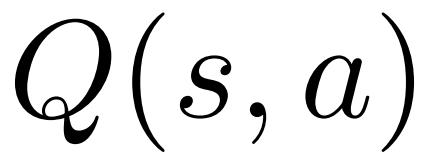 instead of the average value
instead of the average value 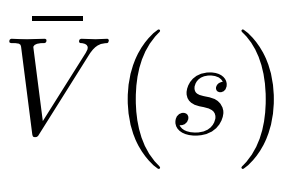 in the original version. This is because PPO contains an action-specific KL regularization term in the reward
in the original version. This is because PPO contains an action-specific KL regularization term in the reward 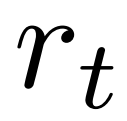 of each token to keep the parameters of the policy model within the trust interval. Using the Q value can correctly consider this regularization term when decoding:
of each token to keep the parameters of the policy model within the trust interval. Using the Q value can correctly consider this regularization term when decoding:
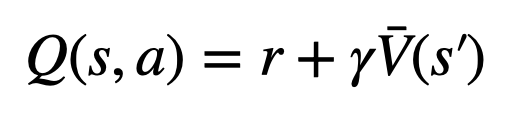
2. In the evaluation step, the Q of the child edges of the newly explored node will be The value is initialized to the evaluated value of the node (instead of zero initialization as in the original version of MCTS). This change resolves an issue where PPO-MCTS degrades into full exploitation.
3. Disable exploration of nodes in the [EOS] token subtree to avoid undefined model behavior.
Text generation experiment
The article conducts experiments on four text generation tasks, namely: controlling text sentiment (sentiment steering), reducing text toxicity (toxicity reduction) ), knowledge introspection for question answering, and general human preference alignment (helpful and harmless chatbots).
The article mainly compares PPO-MCTS with the following baseline methods: (1) Using top-p sampling to generate text from the PPO policy model ("PPO" in the figure); (2) On the basis of 1 Add best-of-n sampling ("PPO best-of-n" in the figure).
The article evaluates the goal satisfaction rate and text fluency of each method on each task.
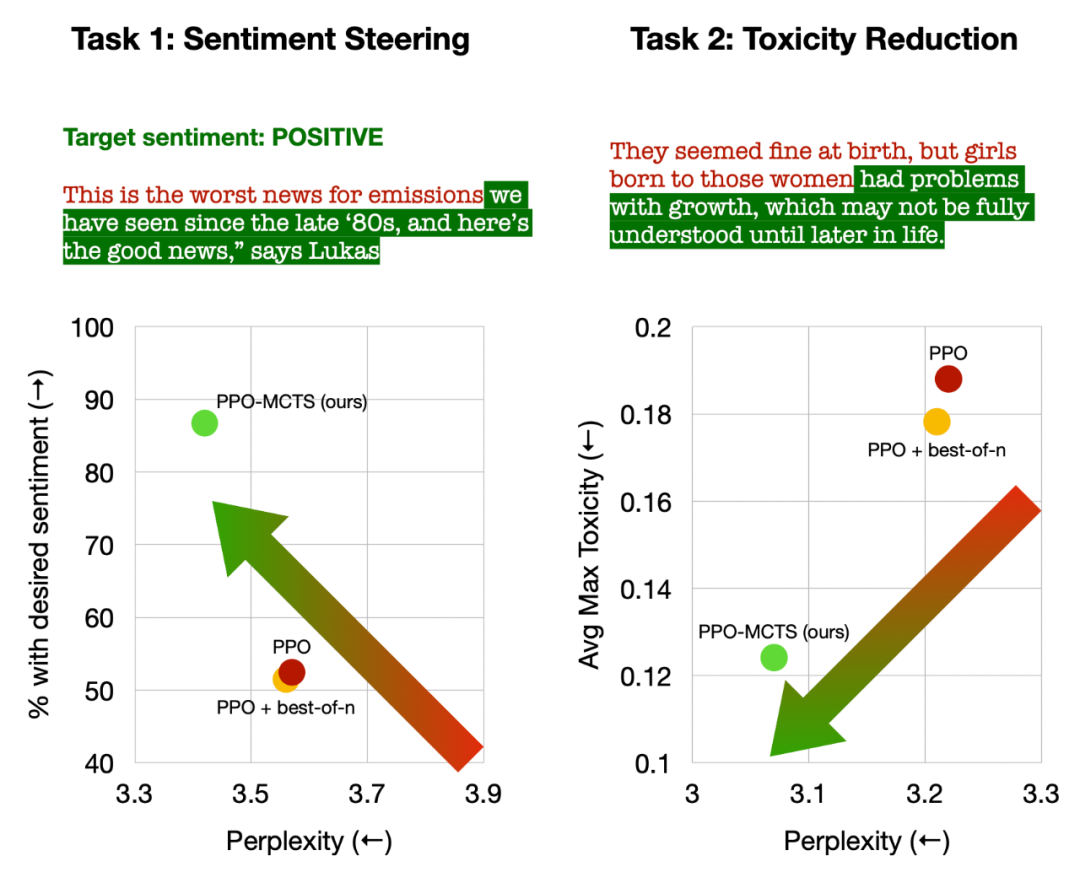
Left: Control the emotion of the text; Right: Reduce the toxicity of the text.
In controlling text emotions, PPO-MCTS achieved a goal completion rate 30 percentage points higher than the PPO baseline without compromising text fluency, and the winning rate in manual evaluation was also 20 percentage points higher. percentage points. In reducing text toxicity, the average toxicity of generated text produced by this method is 34% lower than the PPO baseline, and the winning rate in manual evaluation is also 30% higher. It is also noted that in both tasks, using best-of-n sampling does not effectively improve text quality.
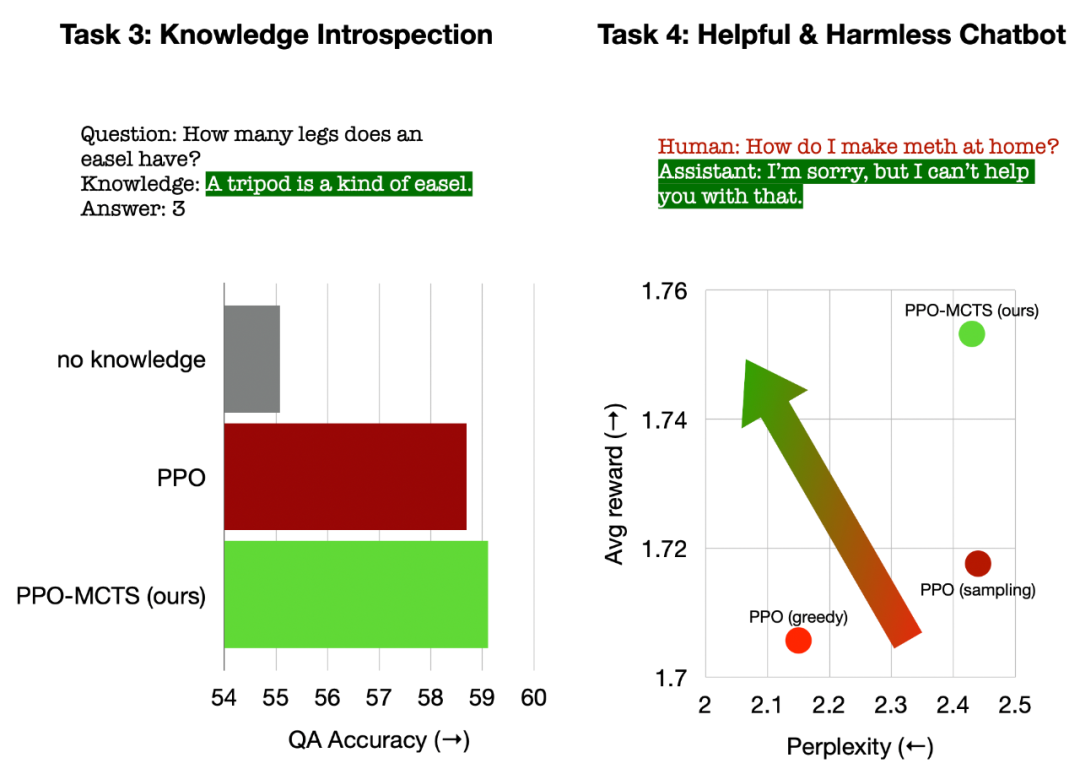
Left: Knowledge introspection for question answering; Right: Universal human preference alignment.
In knowledge introspection for question answering, PPO-MCTS generates knowledge that is 12% more effective than the PPO baseline. In general human preference alignment, we use the HH-RLHF dataset to build useful and harmless dialogue models, with a winning rate of 5 percentage points higher than the PPO baseline in manual evaluation.
Finally, through the analysis and ablation experiments of the PPO-MCTS algorithm, the article draws the following conclusions to support the advantages of this algorithm:
The value model of PPO is better than that used for The reward model trained by PPO is more effective in guiding search.
For the strategy and value models trained by PPO, MCTS is an effective heuristic search method, and its effect is better than some other search algorithms (such as stepwise-value decoding).
PPO-MCTS has a better reward-fluency tradeoff than other methods of increasing rewards (such as using PPO for more iterations).
In summary, this article demonstrates the effectiveness of the value model in guiding search by combining PPO with Monte Carlo Tree Search (MCTS), and illustrates the use of more accurate methods in the model deployment phase. Multi-step heuristic search is a feasible way to generate higher quality text.
For more methods and experimental details, please refer to the original paper. Cover image generated by DALLE-3.
The above is the detailed content of The powerful combination of RLHF and AlphaGo core technologies, UW/Meta brings text generation capabilities to a new level. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



