



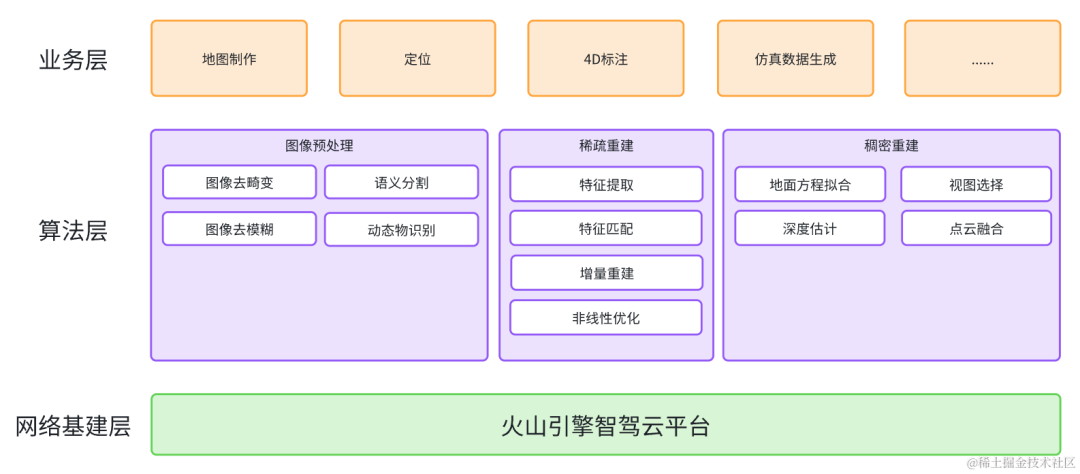
The continuous development of intelligent driving technology is changing our travel methods and transportation systems. As one of the key technologies, 3D reconstruction plays an important role in intelligent driving systems. In addition to the perception and reconstruction algorithms of the car itself, the implementation and development of autonomous driving technology requires the support of huge cloud reconstruction capabilities. The Volcano Engine Multimedia Laboratory uses industry-leading self-developed 3D reconstruction technology, combined with powerful cloud platform resources and capabilities, to help The implementation and application of related technologies in scenarios such as large-scale reconstruction, automatic annotation, and realistic simulation on the cloud.
This article focuses on the principles and practices of the Volcano Engine Multimedia Laboratory's 3D reconstruction technology in dynamic and static scenes, as well as in combination with advanced light field reconstruction technology, to help everyone better understand and understand how intelligent 3D reconstruction on the cloud works. Serving the field of intelligent driving and assisting the development of the industry.
Driving scene reconstruction requires point cloud-level three-dimensional reconstruction of the road environment. Compared with traditional three-dimensional reconstruction technology application scenarios, driving scene reconstruction technology has the following Difficulty:
The reconstruction algorithm in the field of autonomous driving usually adopts a technical route based on lidar and cameras, supplemented by GPS and inertial navigation. LiDAR can directly obtain high-precision ranging information and quickly obtain scene structure. Through pre-lidar-camera joint calibration, the image obtained by the camera can give color, semantics and other information to the laser point cloud. At the same time, GPS and inertial navigation can assist in positioning and reduce drift caused by feature degradation during the reconstruction process. However, due to the high price of multi-line lidar, it is usually used in engineering vehicles and is difficult to be used on a large scale in mass-produced vehicles.
In this regard, the Volcano Engine Multimedia Laboratory has independently developed a set of purely visual driving scene reconstruction technologies, including static scene reconstruction, dynamic object reconstruction and neural radiation field reconstruction technology, which can distinguish dynamic and static objects in the scene. , restore the dense point cloud of the static scene, and highlight key elements such as road surfaces, signs, and traffic lights; it can effectively estimate the position, size, orientation, and speed of moving objects in the scene for subsequent 4D annotation; it can On the basis of static scene reconstruction, the neural radiation field is used to reconstruct and reproduce the scene to achieve free perspective roaming, which can be used for scene editing and simulation rendering. This technical solution does not rely on lidar and can achieve decimeter-level relative errors, achieving reconstruction effects close to lidar with minimal hardware cost.
Visual reconstruction technology is based on multi-view geometry and requires the scene or object to be reconstructed to have inter-frame consistency , that is, they are in a static state in different image frames, so dynamic objects need to be eliminated during the reconstruction process. According to the importance of different elements in the scene, irrelevant point clouds need to be removed from the dense point cloud, while some key element point clouds are retained. Therefore, the image needs to be semantically segmented in advance. In this regard, Volcano Engine The multimedia laboratory combines AI technology and the basic principles of multi-view geometry to build an advanced A robust, accurate and complete visual reconstruction algorithm framework. The reconstruction process includes three key steps : image preprocessing, sparse reconstruction and dense reconstruction .
The vehicle-mounted camera is in motion during shooting. Due to the exposure time, serious motion blur will appear in the collected images as the vehicle speed increases. In addition, in order to save bandwidth and storage space, the image will be irreversibly lossy compressed during the transmission process, causing further degradation of image quality. To this end, the Volcano Engine Multimedia Laboratory uses an end-to-end neural network to deblur the image, which can improve image quality while suppressing motion blur. The comparison before and after deblurring is shown in the figure below.

Before deblurring (left) After deblurring (right)
In order to distinguish dynamic objects, the Volcano Engine Multimedia Laboratory Dynamic object recognition technology based on optical flow is used to obtain pixel-level dynamic object masks. In the subsequent static scene reconstruction process, feature points falling on the dynamic object area will be eliminated, and only static scenes and objects will be retained.

Optical flow (left) Moving object (right)
During the sparse reconstruction process, the camera's position, orientation and For scene point clouds, the SLAM algorithm (Simultaneous localization and mapping) and the SFM algorithm (Structure from Motion, referred to as SfM) are commonly used. The SFM algorithm can achieve higher reconstruction accuracy without requiring real-time performance. However, the traditional SFM algorithm usually treats each camera as an independent camera, while multiple cameras are usually arranged in different directions on the vehicle, and the relative positions between these cameras are actually fixed (ignoring the vehicle). subtle changes caused by vibration). If the relative position constraints between cameras are ignored, the calculated pose error of each camera will be relatively large. In addition, when occlusion is severe, the pose of individual cameras will be difficult to calculate. In this regard, the Volcano Engine Multimedia Laboratory self-developed an SFM algorithm based on the entire camera group, which can use the prior relative pose constraints between cameras to calculate the pose of the camera group as a whole, and also uses GPS plus inertial navigation. Fusion of positioning results to constrain the center position of the camera group can effectively improve the success rate and accuracy of pose estimation, improve point cloud inconsistencies between different cameras, and reduce point cloud layering.


Traditional SFM (left) Camera group SFM (right)
Due to the color of the ground Single and missing texture, it is difficult for traditional visual reconstruction to restore the complete ground. However, there are key elements on the ground such as lane lines, arrows, text/logos, etc. Therefore, the Volcano Engine Multimedia Laboratory uses quadratic surfaces to fit the ground to assist Perform depth estimation and point cloud fusion of ground areas. Compared with plane fitting, quadratic surface is more suitable for actual road scenes, because the actual road surface is often not an ideal plane. The following is a comparison of the effects of using plane equations and quadratic surface equations to fit the ground.

Plane equation (left) Quadratic surface equation (right)
Treat the laser point cloud as a true value, and The visual reconstruction results are superimposed with this to intuitively measure the accuracy of the reconstructed point cloud. As can be seen from the figure below, the fit between the reconstructed point cloud and the true point cloud is very high. After measurement, the relative error of the reconstruction result is about 15cm.

Volcano Engine Multimedia Laboratory reconstruction results (color) and ground truth point cloud (white)
The following is Volcano Engine Multimedia Comparison of the effects of the laboratory visual reconstruction algorithm and a mainstream commercial reconstruction software. It can be seen that compared with commercial software, the self-developed algorithm of the Volcano Engine Multimedia Laboratory has a better and more complete reconstruction effect. The street signs, traffic lights, telephone poles, as well as lane lines and arrows on the road in the scene have a very high degree of restoration. However, the reconstructed point cloud of commercial software is very sparse, and the road surface is missing in large areas.

A certain mainstream commercial software (left) Volcano Engine Multimedia Laboratory algorithm (right)
It is very difficult to 3D annotate objects on images. Point clouds are needed. When the vehicle only has a visual sensor, it can obtain the target object in the scene. Complete point clouds are difficult. Especially for dynamic objects, dense point clouds cannot be obtained using traditional 3D reconstruction techniques. In order to provide the expression of moving objects and serve 4D annotation, 3D bounding box (hereinafter referred to as 3D Bbox) is used to represent dynamic objects, and the 3D Bbox posture, size, and speed of dynamic objects in the scene at each moment are obtained through self-developed dynamic reconstruction algorithms. etc., thereby complementing the dynamic object reconstruction capability.
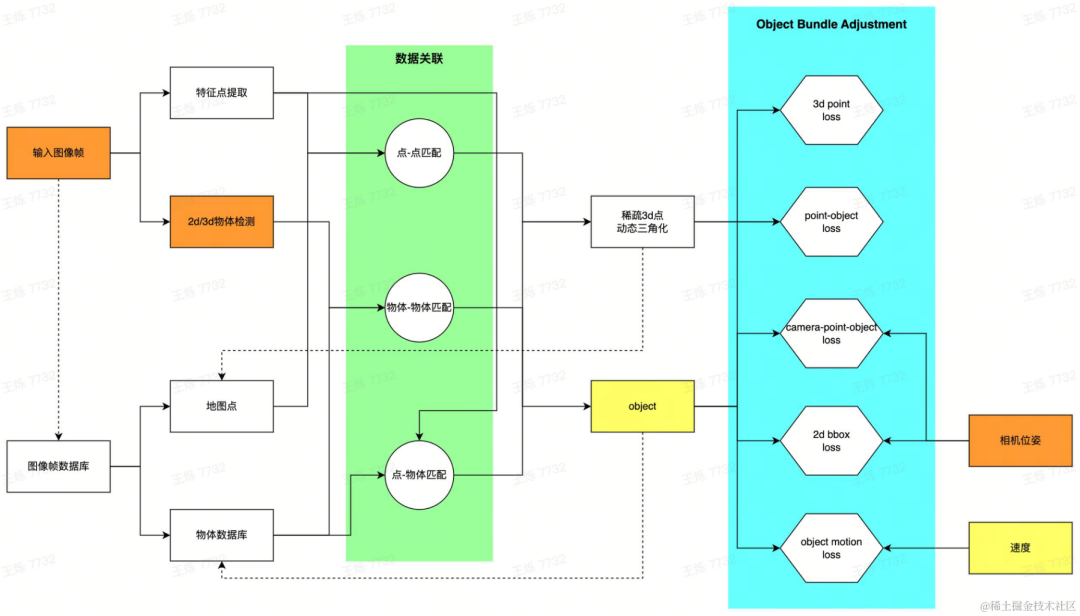
Dynamic reconstruction pipeline
For each frame of image collected by the vehicle, first extract the dynamic target in the scene and generate a 3d bbox The initial proposal provides two methods: using 2D target detection and estimating the corresponding 3D bbox through the camera pose; directly using 3D target detection. The two methods can be flexibly selected for different data. 2D detection has good generalization, and 3D detection can obtain better initial values. At the same time, feature points inside the dynamic area of the image are extracted. After obtaining the initial 3D bbox proposal and feature points of a single frame image, establish data correlation between multiple frames: establish object matching through a self-developed multi-target tracking algorithm, and match image features through feature matching technology. After obtaining the matching relationship, the image frames with common view relationships are created as local maps, and an optimization problem is constructed to solve the globally consistent target bbox estimation. Specifically, through feature point matching and dynamic triangulation technology, dynamic 3D points are restored; vehicle motion is modeled, and observations between objects, 3D points, and cameras are jointly optimized to obtain the optimal estimated dynamic object 3D bbox.

2d generates 3d (second from left) 3d target detection example
Use neural network for implicit reconstruction, use differentiable rendering model, from existing views Learn how to render images from a new perspective for photorealistic image rendering: Neural Radiation Field (NeRF) technology. At the same time, implicit reconstruction has the characteristics of being editable and querying continuous space, and can be used for tasks such as automatic annotation and simulation data construction in autonomous driving scenarios. Scene reconstruction using NeRF technology is extremely valuable.
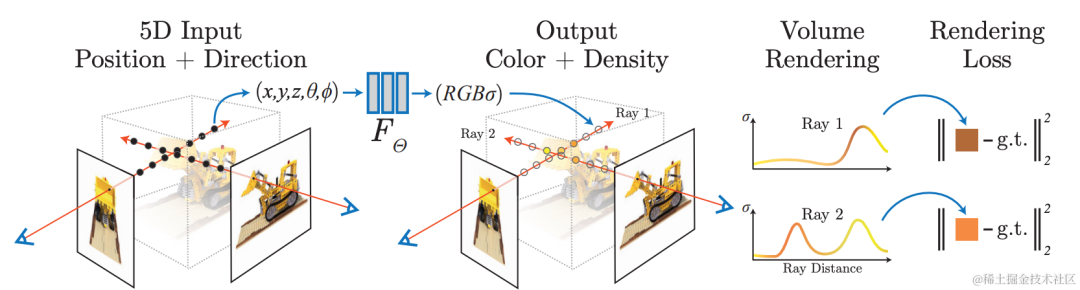
The Volcano Engine Multimedia Laboratory combines neural radiation field technology and large scene modeling technology. In specific practice, the data is first processed. Dynamic objects in the scene will cause artifacts in the NeRF reconstruction. With the help of self-developed dynamic and static segmentation, shadow detection and other algorithms, the areas in the scene that are inconsistent with the geometry are extracted and a mask is generated. At the same time, the video inpainting algorithm is used to repair the removed areas. With the help of self-developed 3D reconstruction capabilities, high-precision geometric reconstruction of the scene is performed, including camera parameter estimation and sparse and dense point cloud generation. In addition, the scenario is split to reduce single training resource consumption, and distributed training and maintenance can be performed. During the neural radiation field training process, for large outdoor borderless scenes, the team used some optimization strategies to improve the new perspective generation effect in this scene, such as improving the reconstruction accuracy by simultaneously optimizing poses during training, and based on the level of hash coding. Expression improves model training speed, appearance coding is used to improve the appearance consistency of scenes collected at different times, and mvs dense depth information is used to improve geometric accuracy. The team cooperated with HaoMo Zhixing to complete single-channel acquisition and multi-channel merged NeRF reconstruction. The relevant results were released on Haomo AI Day.

Dynamic object/shadow culling, filling
The above is the detailed content of Excellent Practice of 3D Reconstruction of Intelligent Driving on the Cloud. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



