


The ability to "read pictures" of large models is so strong, why do they still find the wrong things?
For example, confusing bats and bats that don't look alike, or not recognizing rare fish in some data sets...
This is because we let the large model When "looking for something", the text is often entered.
If the description is ambiguous or too biased, such as "bat" (bat or bat?) or "devil medaka" (Cyprinodon diabolis) , the AI will will be greatly confused.
This leads to the use of large models for target detection, especially for open world (unknown scenes) target detection tasks. The effect is often ineffective. It's as good as imagined.
Now, a paper included in NeurIPS 2023 finally solves this problem.

The paper proposes a target detection method based on multi-modal queryMQ-Det, which only needs to add The previous picture example can greatly improve the accuracy of finding things with large models.
On the benchmark detection data set LVIS, without the need for downstream task model fine-tuning, MQ-Det improves the GLIP accuracy of the mainstream detection large model by about 7.8%# on average. ##, on 13 benchmark small sample downstream tasks, the average accuracy is improved by 6.3%.
How is this done? Lets come look.The following content is reproduced from the author of the paper and Zhihu blogger @沁园夏:
DirectoryPaper name:Multi-modal Queried Object Detection in the Wild
Paper link: //m.sbmmt.com/link/9c6947bd95ae487c81d4e19d3ed8cd6f
Code address: //m.sbmmt.com/link/2307ac1cfee5db3a5402aac9db25cc5d

A picture is worth a thousand words: With the rise of image and text pre-training, and with the help of the open semantics of text, target detection has gradually entered the stage of open world perception. To this end, many large detection models follow the pattern of text query, which uses categorical text descriptions to query potential targets in target images. However, this approach often faces the problem of being “broad but not precise”.
For example, (1) for the fine-grained object(fish species) detection in Figure 1, it is often difficult to describe various fine-grained fish species with limited text, (2) Category ambiguity ("bat" can refer to both a bat and a bat) .
However, the above problems can be solved through image examples. Compared with text, images can providericher feature clues of the target object, but at the same time, text has powerful Generalizability.
Thus, how to organically combine the two query methods has become a natural idea.Difficulties in obtaining multi-modal query capabilities: How to obtain such a model with multi-modal query, there are three challenges: (1) It is very difficult to fine-tune directly with limited image examples. It is easy to cause catastrophic forgetting; (2) Training a large detection model from scratch will have good generalization but consumes a lot of money. For example, training GLIP on a single card requires 30 million data for 480 days.
Multi-modal query target detection: Based on the above considerations, the author proposed a simple and effective model design and training strategy-MQ-Det.
MQ-Det inserts a small number of gated perception modules(GCP) based on the existing large frozen text query detection model to receive input from visual examples, and also designs a visual condition mask The language prediction training strategy efficiently results in high-performance detectors for multi-modal queries.
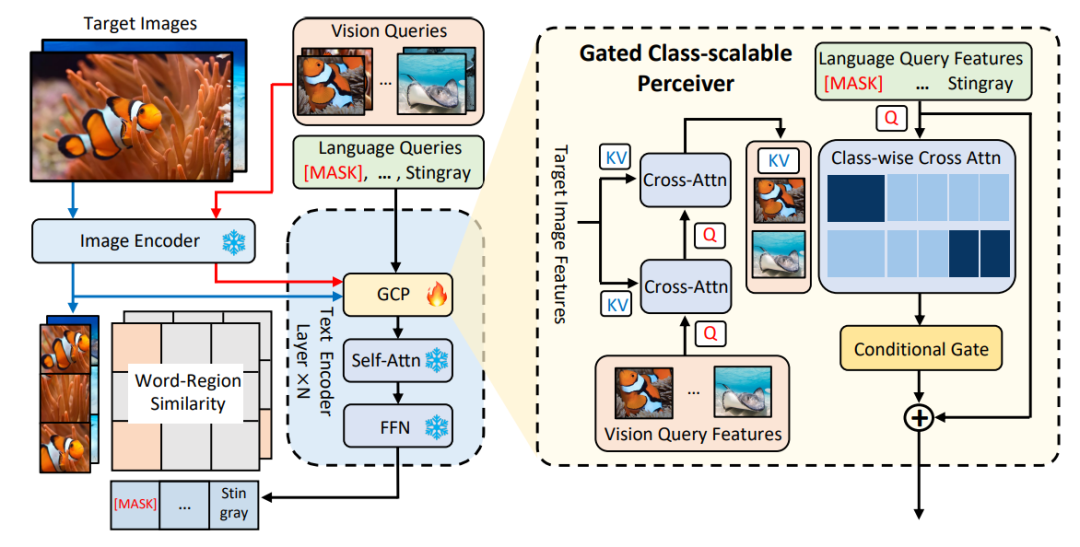
Gated Awareness Module
As shown in Figure 1, the author inserted the Gating Awareness Module(GCP) layer by layer into the text encoder side of the existing frozen text query detection large model. , the working mode of GCP can be succinctly expressed by the following formula:
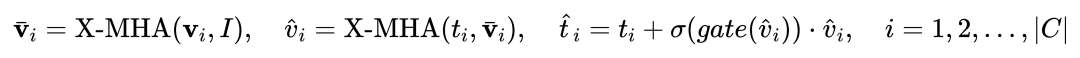
(X-MHA) gets to enhance its representation ability, and then each category text ti will cross-attention with the visual example 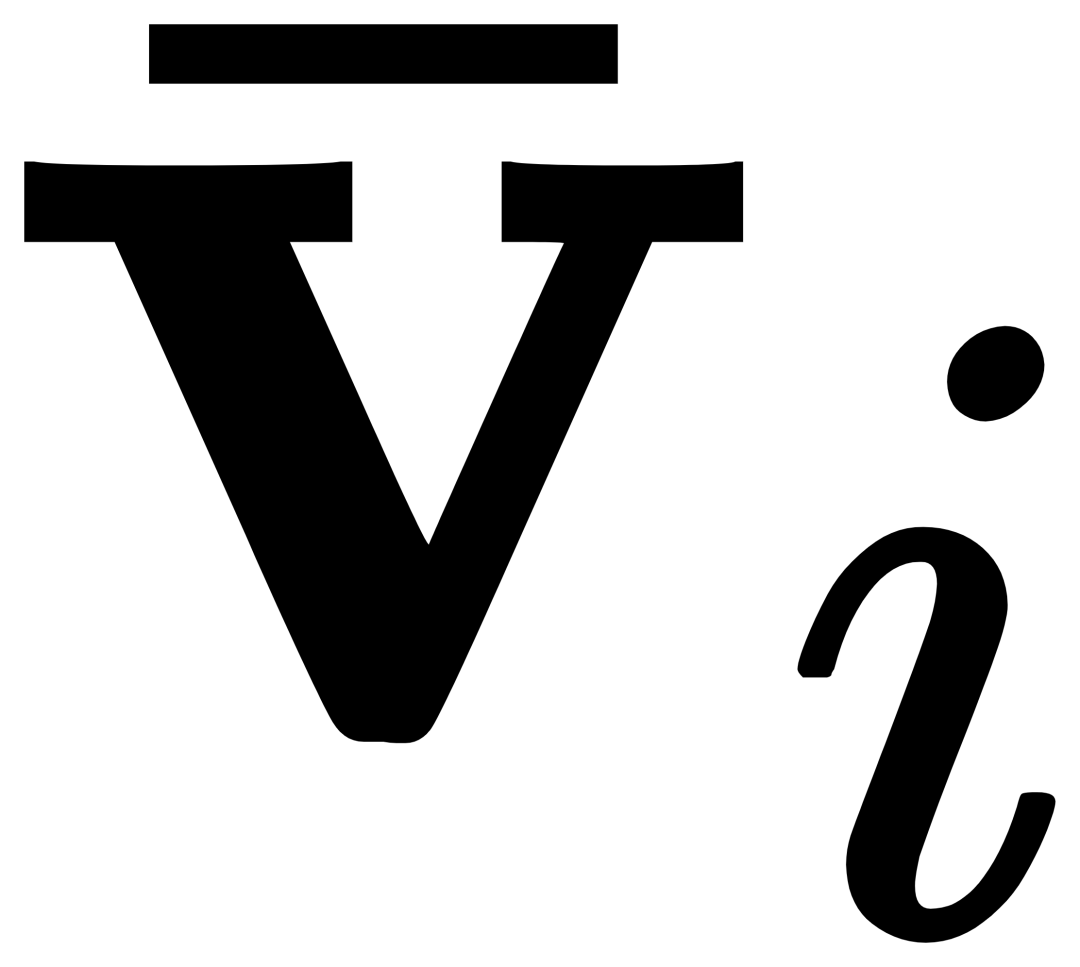 of the corresponding category to get
of the corresponding category to get 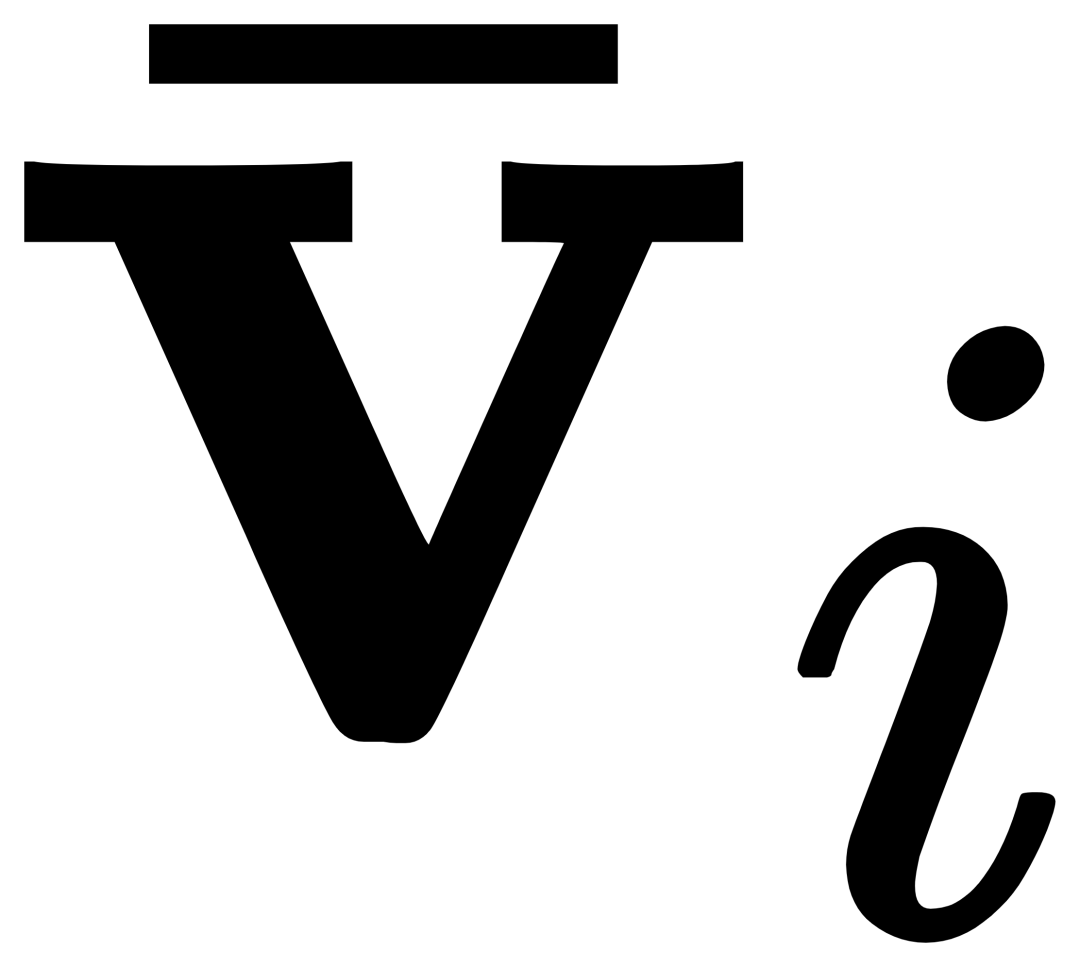 , and then The original text ti and the visually augmented text
, and then The original text ti and the visually augmented text 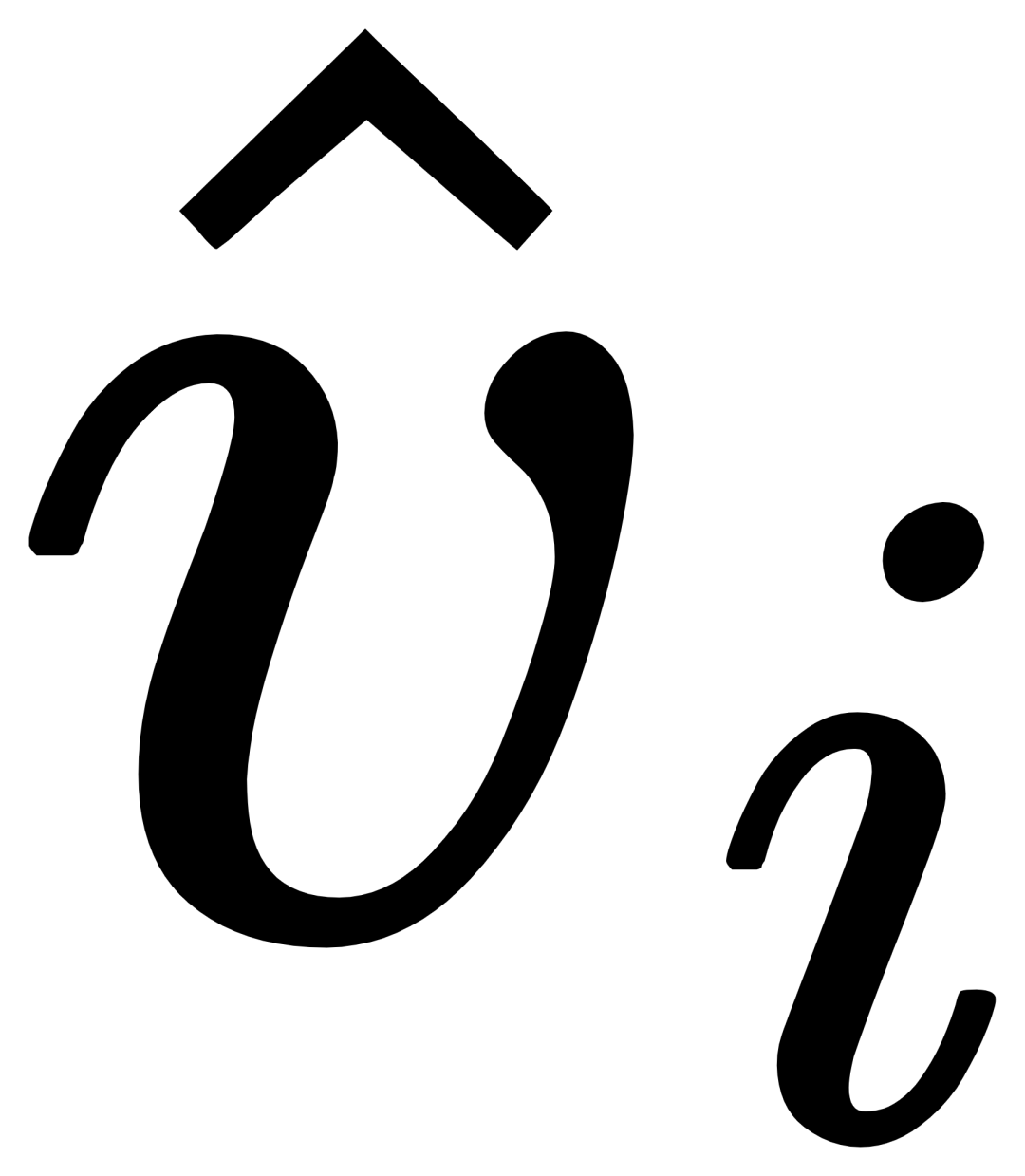 are fused through a gating module gate to obtain the output
are fused through a gating module gate to obtain the output 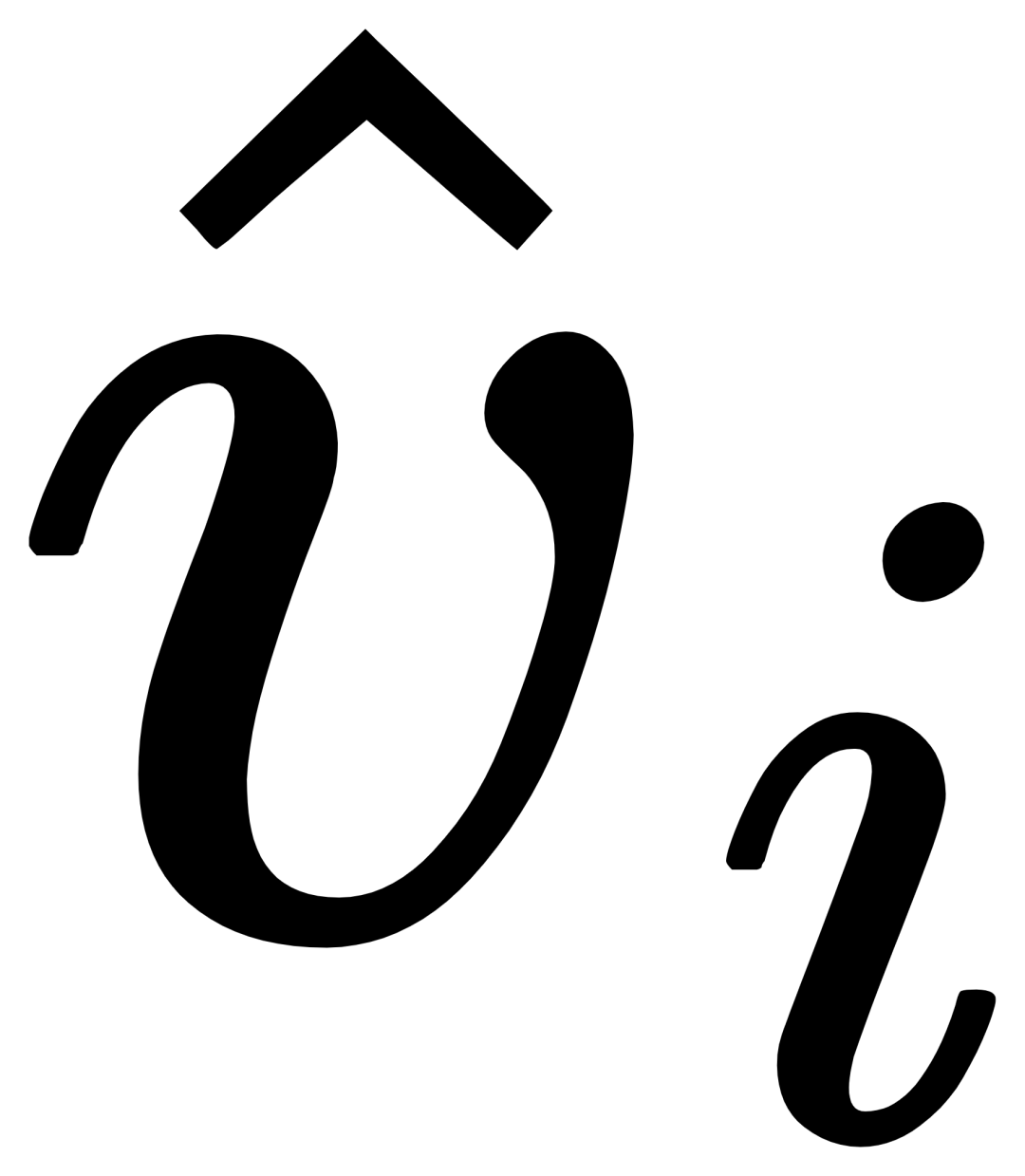 of the current layer. Such a simple design follows three principles: (1) Category scalability; (2) Semantic completion; (3) Anti-forgetfulness. For detailed discussion, see the original text.
of the current layer. Such a simple design follows three principles: (1) Category scalability; (2) Semantic completion; (3) Anti-forgetfulness. For detailed discussion, see the original text. 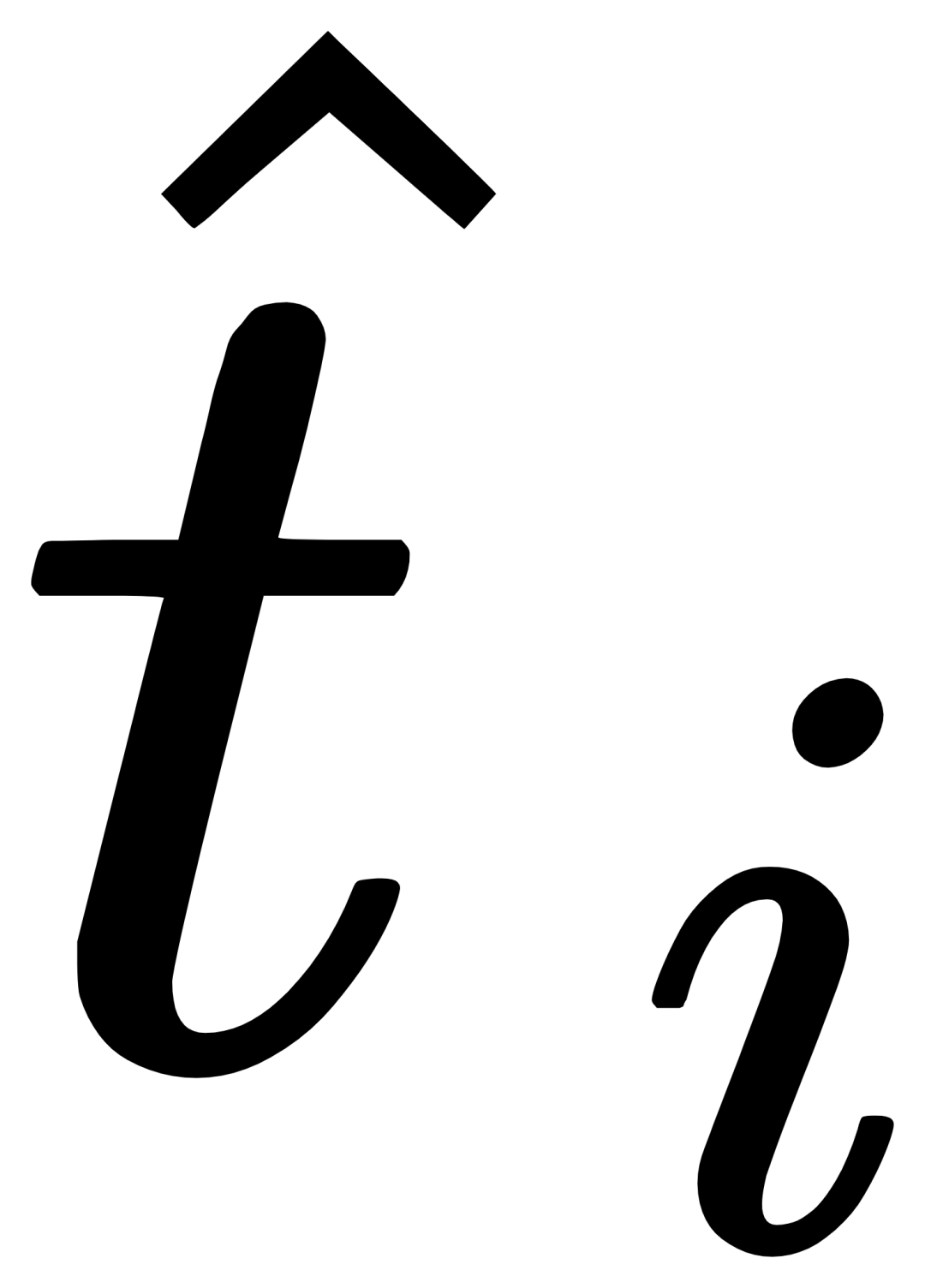
Modulated training based on frozen language query detector
Due to the current large pre-trained detection model of text queries It has good generalization ability. The author of the paper believes that it only needs to be slightly adjusted with visual details based on the original text features. There are also specific experimental demonstrations in the article that found that fine-tuning after opening the original pre-trained model parameters can easily lead to the problem of catastrophic forgetting, and instead lose the ability to detect the open world. Thus, MQ-Det can efficiently insert visual information into the detector of existing text queries by only modulating the GCP module inserted into the training based on the pre-trained detector of frozen text queries. In the paper, the author applies the structural design and training technology of MQ-Det to the current SOTA models GLIP and GroundingDINO respectively to verify the versatility of the method.Vision-conditioned mask language prediction training strategy
The author also proposed a vision-conditioned mask language prediction training strategy to solve the problem of frozen pre-programming. The problem of learning inertia caused by training models. The so-called learning inertia means that the detector tends to maintain the features of the original text query during the training process, thereby ignoring the newly added visual query features. To this end, MQ-Det randomly replaces text tokens with [MASK] tokens during training, forcing the model to learn from the visual query feature side, that is: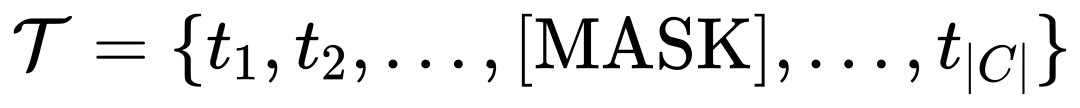
Finetuning-free: Compared with traditional zero-shot(zero-shot) evaluation only uses categories Text is tested, and MQ-Det proposes a more realistic evaluation strategy: finetuning-free. It is defined as: without any downstream fine-tuning, users can use category text, image examples, or a combination of both to perform object detection.
Under the finetuning-free setting, MQ-Det selects 5 visual examples for each category and combines the category text for target detection. However, other existing models do not support visual queries and can only Object detection with plain text descriptions. The following table shows the detection results on LVIS MiniVal and LVIS v1.0. It can be found that the introduction of multi-modal query greatly improves the open world target detection capability.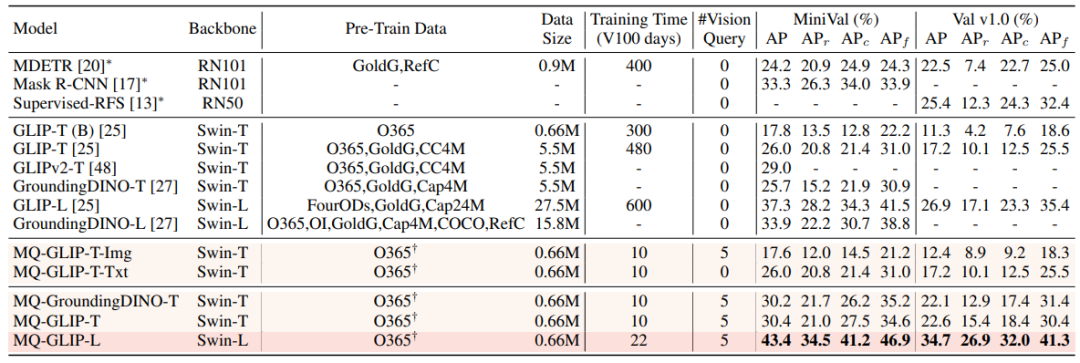
△Table 1 The finetuning-free performance of each detection model under the LVIS benchmark data set
As can be seen from Table 1, MQ-GLIP-L has the highest performance in GLIP- Based on L, AP has been increased by more than 7%, and the effect is very significant!
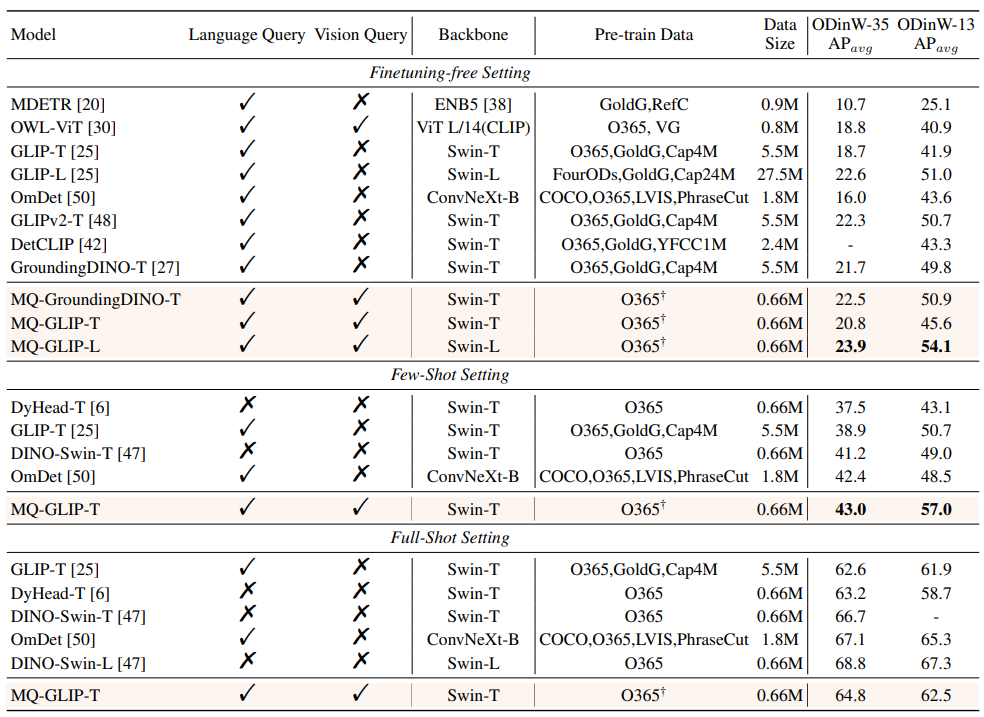
△Table 2 Each model performs on 35 detection tasks ODinW-35 and its 13 subsets ODinW-13 Performance
The author further conducted comprehensive experiments on 35 downstream detection tasks ODinW-35. As can be seen from Table 2, in addition to its powerful finetuning-free performance, MQ-Det also has good small sample detection capabilities, which further confirms the potential of multi-modal query. Figure 2 also shows the significant improvement of MQ-Det on GLIP.
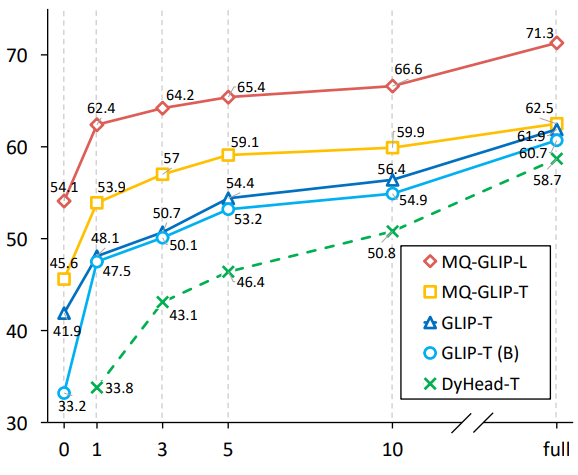
△Figure 2 Comparison of data utilization efficiency; horizontal axis: number of training samples, vertical axis: average AP on OdinW-13
As a research field based on practical applications, target detection attaches great importance to the implementation of algorithms.
Although previous pure text query target detection models have shown good generalization, it is difficult for text to cover fine-grained information in actual open world detection, and the rich information granularity in images perfectly Completed this link.
So far we can find that text is general but not precise, and images are precise but not general. If we can effectively combine the two, that is, multi-modal query, it will push open world target detection further forward.
MQ-Det has taken the first step in multi-modal query, and its significant performance improvement also demonstrates the huge potential of multi-modal query target detection.
At the same time, the introduction of text descriptions and visual examples provides users with more choices, making target detection more flexible and user-friendly.
The above is the detailed content of Let's look at pictures of large models more effectively than typing! New research in NeurIPS 2023 proposes a multi-modal query method, increasing the accuracy by 7.8%. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



