


This is incredible!
Now you can easily create beautiful and high-quality 3D models with just a few words?
No, a foreign blog set off the Internet and put something called MVDream in front of us.
Users can create a lifelike 3D model with just a few words.

And what’s different from before is that MVDream seems to really “understand” physics.
Let’s see how amazing this MVDream is~
小Brother said that in the era of big models, we have seen too many text generation models and image generation models. And the performance of these models is getting more and more powerful.
We later witnessed the birth of the Vincent video model, and of course the 3D model we want to mention today
Just imagine, just Just input a sentence, and you can generate an object model that looks like it exists in the real world, even including all the necessary details. How cool is this scene?
And this is definitely not a It’s a simple thing, especially when users need to generate models that are realistic enough in detail.
Let’s take a look at the effect first~

##At the same time As a reminder, what is shown on the far right is the finished product of MVDream
The gap between the 5 models is visible to the naked eye. The first few models completely violate the objective facts and are only correct when viewed from certain angles.
For example, in the first four pictures, the generated model actually has more than two ears. Although the fourth picture looks more detailed, when turned to a certain angle we can find that the character's face is concave and there is an ear stuck on it.
Who knows, the editor immediately remembered the front view of Peppa Pig, which was very popular before.

This is a situation that is shown to you from certain angles, but absolutely not from other angles, there will be Life danger
But the generation model of MVDream on the far right is obviously different. No matter how the 3D model is rotated, you will not feel anything unconventional.
This is what was mentioned before, MVDream knows the physics knowledge well and will not create some weird things just to ensure that each view has two ears
The brother pointed out that the key to judging whether a 3D model is successful is to observe whether its different perspectives are realistic and of high quality
And also ensure that the model is in space continuity, rather than the multiple ears model above.
One of the main methods of generating 3D models is to simulate the camera's perspective and then generate what can be seen from a certain perspective.
In other words, this is the so-called 2D lifting. It means splicing different perspectives together to form the final 3D model.
The above multi-ear situation occurs because the generative model does not fully grasp the shape information of the entire object in the three-dimensional space. And MVDream is just a big step forward in this regard.
This new model solves the previous consistency problem in 3D perspective
This method is called score distillation sampling and was developed by DreamFusion
Before we start learning about fractional distillation sampling technology, we need to understand it first Let’s take a look at the architecture used in this method
In other words, this is actually just another two-dimensional image diffusion model, similar to the DALLE, MidJourney and Stable Diffusion models
More specifically, everything starts from the pre-trained DreamBooth model. DreamBooth is an open source model based on Stable Diffusion raw graphs.
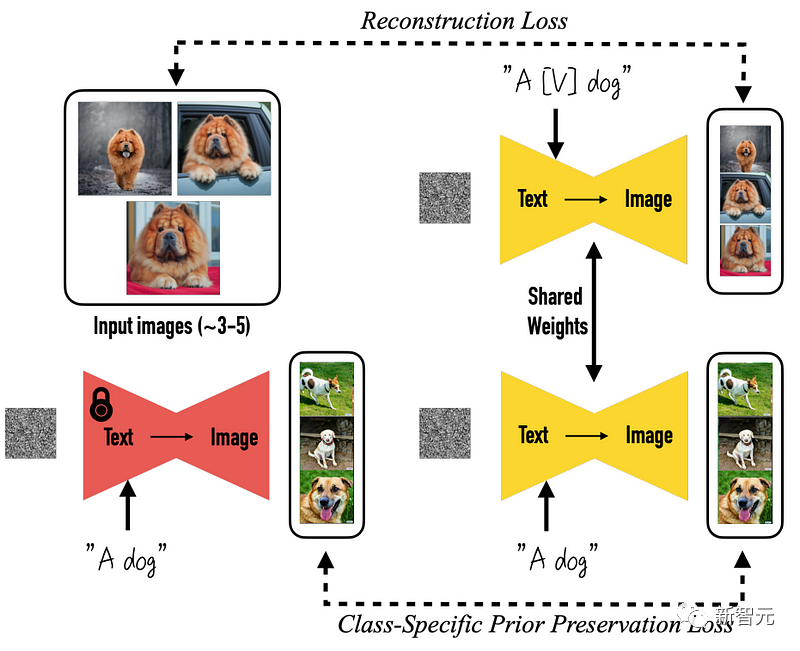
Change is coming, which means things have changed
What the research team did next Yes, directly rendering a set of multi-view images instead of just rendering one image. This step requires three-dimensional data sets of various objects to complete.
Here, the researchers took multiple views of a 3D object from a dataset, used them to train a model, and then used it to generate those views backwards.
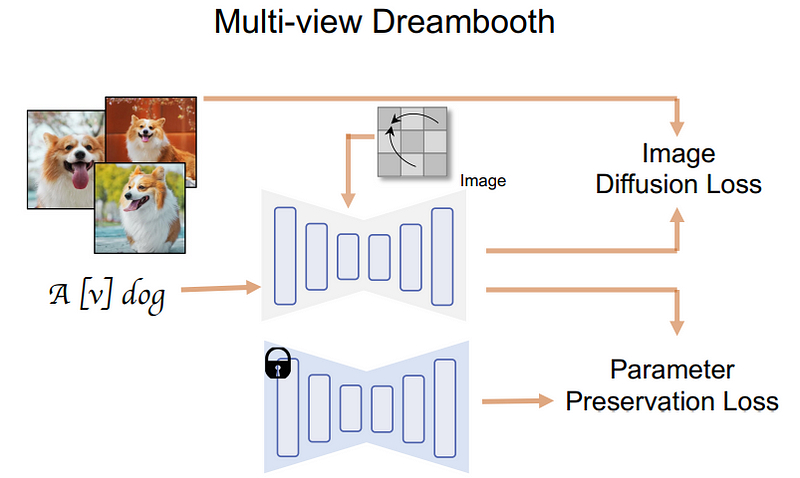
The specific method is to change the blue self-attention block in the picture below to a three-dimensional self-attention block. That is to say, the researchers only need to add one dimension to reconstruct multiple images, and Not an image.
In the picture below, we can see that the camera and timestep are input into the model for each view to help the model understand which image will be used where, and what is needed What kind of view is generated
Now, all the images are connected together and the generation is also done together. So they can share information and better understand the big picture.
First, text is input into the model, and then the model is trained to accurately reconstruct objects from the data set
And here is where the research team applied more A place to view the fractional distillation sampling process.
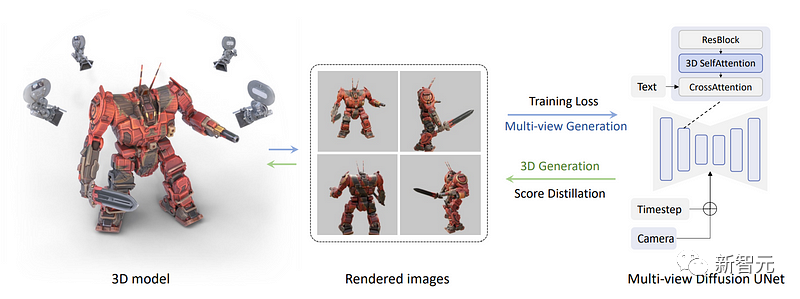
Now, with a multi-view diffusion model, the team can generate multiple views of an object.
Next, we need to use these views to reconstruct a three-dimensional model that is consistent with the real world, not just the views
Needed here This is achieved using NeRF (neural radiance fields), just like the aforementioned DreamFusion.
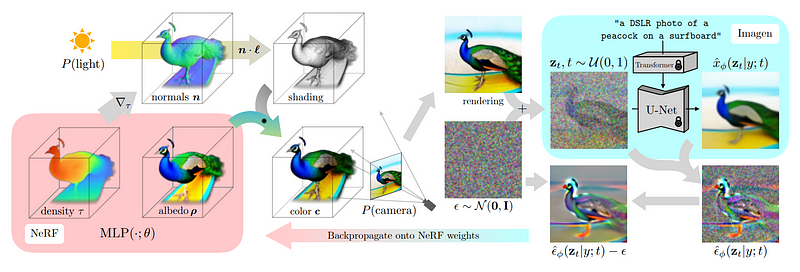
In this step, our goal is to freeze the previously trained multi-view diffusion model. In other words, we just use the pictures from each perspective above in this step without training.
Under the guidance of the initial rendering, the researchers began to use the multi-view diffusion model to generate Some noisy versions of the initial image
To let the model know that it needs to generate different versions of the image, the researchers added noise while still being able to receive background information
Next, this model can be used to further generate higher quality images
Add the image used to generate this image and remove the image we added manually noise so that the results can be used in the next step to guide and improve the NeRF model.
In order to generate better results in the next step, the purpose of these steps is to better understand which part of the image the NeRF model should focus on
Repeat this process until a satisfactory 3D model is generated
And for multiple perspectives This is how the team evaluated the image generation quality of the diffusion model and judged how different designs would affect its performance.
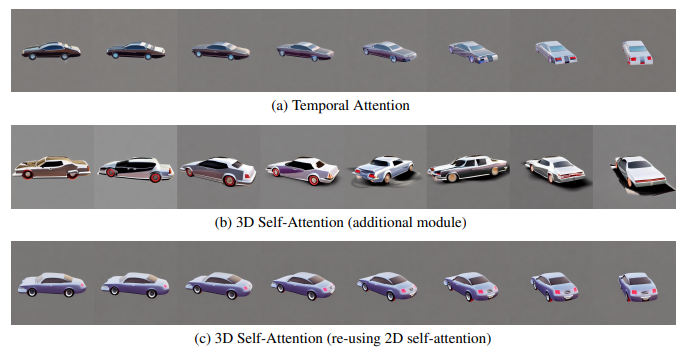
First, they compared choices of attention modules for building cross-view consistency models.
These options include:
(1) One-dimensional temporal self-attention widely used in video diffusion models;
(2) Add a new three-dimensional self-attention module to the existing model;
(3) Reuse the existing two-dimensional self-attention module for three-dimensional attention .
In order to accurately demonstrate the differences between these modules, in this experiment, the researchers used 8 frames of 90-degree perspective changes to train the model to more closely match the video settings
In the experiment, the research team also maintained a higher image resolution, that is, 512×512 as the original SD model. As shown in the figure below, the researchers found that even with such limited perspective changes in static scenes, temporal self-attention is still affected by content shifts and cannot maintain perspective consistency
The team hypothesizes that this is because temporal attention can only exchange information between the same pixels in different frames, while the corresponding pixels may be far apart when the viewpoint changes.
On the other hand, adding new 3D attention without learning consistency can lead to severe quality degradation.
The researchers believe that this is because learning new parameters from scratch will consume more training data and time, which is not applicable to this situation where the three-dimensional model is limited. They proposed a strategy to reuse the 2D self-attention mechanism to achieve optimal consistency without degrading the generation quality
The team also noted that if the image size is reduced to 256 , the number of views is reduced to 4, and the differences between these modules will be much smaller. However, to achieve the best consistency, the researchers made their choices based on preliminary observations in the following experiments.
In addition, the researchers implemented multi-view fractional distillation sampling in the threestudio (thr) library and introduced multi-view diffusion guidance. This library implements state-of-the-art text-to-3D model generation methods under a unified framework
The researchers used the implicit-volume in threestudio as the 3D representation. implementation, including a multi-resolution hash-grid
When studying the camera view, the researchers used exactly the same approach when rendering the 3D dataset Two people were sampled on the camera
In addition, the researchers also optimized the 3D model for 10,000 steps, using the AdamW optimizer and setting the learning rate to 0.01
In fractional distillation sampling, in the first 8000 steps, the maximum and minimum time steps are reduced from 0.98 steps to 0.5 steps and 0.02 steps respectively
The starting resolution of rendering is 64×64, which gradually increases to 256×256 after 5000 steps
The following are more cases:

The research team used a 2D text-to-image model to perform multi-view synthesis, and through an iterative process, created a text-to-3D model method
This new method currently has some limitations. The main problem is that the resolution of the generated image is only 256x256 pixels, which can be said to be very low.
In addition, the researchers It was also pointed out that the size of the data set used to perform this task will certainly limit the generalizability of this method to some extent, because if the data set is too small, it will not be able to reflect our complex world more realistically.
The above is the detailed content of Vincent's 3D model breakthrough! MVDream is coming, generating ultra-realistic 3D models in one sentence. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



