


Translator| ##I wonder if you have noticed that the data set may be the most overlooked part of the machine learning project. To most people, a dataset is nothing more than a collection of pre-made images that have been quickly put together or downloaded. In fact, datasets are the cornerstone of any image-based artificial intelligence (AI) project. For any machine learning project aiming to achieve high accuracy, creating and managing a balanced and well-structured dataset is crucial.
# However, creating a dataset is not as simple as collecting hundreds of images. When we try to start an AI project, we are likely to encounter various hidden dangers. Below, I'll discuss seven typical steps you can take to create your own dataset so you can gain insight into the importance of dataset size, possible data omissions, and converting a dataset into a database.
#Note: These steps will mainly apply to object detection and classification projects that include image datasets. Other project types, such as NLP
or graphics projects, require a different approach.Steps
1: Image size
Normally, neural networks can only process images of a specific size, and images exceeding a threshold will be forced to be reduced. This means that before using the dataset, we need to choose a suitable neural network and resize the image accordinglyAs shown in the figure below, if you can understand the image sizes that the network can use, it will help you to crop the appropriate data set images.
##Although the image size that most neural networks can handle is relatively small, such as 
are capable of processing larger resolution images. For example, Yolo v5x
s 6
6
can handle images up to 1280 pixels wide image. Step 2: Understandyourenvironment
Image The size
A data set that is too "beautiful" is likely to lead to higher test accuracy. This means that the neural network will only perform well on test data (a collection of images purified from the dataset), but will perform poorly in real-world conditions and result in poor accuracy.
Step
3 :
:
Format and Comments
Annotation data can be used to specify bounding boxes, file names, and the different structures that can be used. Generally, different neural networks and frameworks require different annotation methods. Some require absolute coordinates containing the bounding box location, others require relative coordinates; some require each image to be accompanied by a separate annotated .txt file, while others require Some require only one file containing all comments. As you can see, even if your dataset has good images, it won't help if your framework can't handle the annotations.
For training purposes, the data set is usually divided into two subsets:

Typically, a neural network will use object features extracted from a training subset to "learn" The appearance of an object. That is, after a training period (epoch), the neural network looks at the validation subset data and tries to guess what it can "Look " to those objects. Whether it is a correct or wrong guess, its structure allows the neural network to learn further.
While this method has been widely used and proven to achieve good results, we prefer to adopt a different approach that combines the data The set is divided into the following subsets:

Step
 ##Essentially, after the model sees an image in the training data set, it first extracts its features, Then go into the validation dataset and find the exact same (or very similar) images you saw. Therefore, rather than saying that the model is actually learning, it is better to say that it is just memorizing various information. Sometimes this results in ridiculously high accuracy on the validation dataset (e.g., as high as
##Essentially, after the model sees an image in the training data set, it first extracts its features, Then go into the validation dataset and find the exact same (or very similar) images you saw. Therefore, rather than saying that the model is actually learning, it is better to say that it is just memorizing various information. Sometimes this results in ridiculously high accuracy on the validation dataset (e.g., as high as
98%), but very low accuracy in production. One of the most commonly used data set segmentation methods is to randomly shuffle the data and then select the top
70% images are put into the training subset, and the remaining 30% are put into the validation subset. This method can easily lead to data omissions. As shown in the figure below, our immediate priority is to remove all "duplicate" photos from the dataset and check whether similar photos exist in both subsets.
For this, we can use a simple script to automatically perform duplicate deletion. Of course, you can adjust the duplication threshold, for example: only delete completely duplicate pictures, or pictures with a similarity as high as 90% , etc. In general, the more duplicate content is removed, the more accurate the neural network will produce.
If your data set is quite large, for example: more than 10million images, and has dozens For object classes and subclasses, we recommend that you create a simple database to store data set information. The reason behind this is actually very simple: with large data sets, it is difficult to keep track of all the data. Therefore, without some structured processing of the data, we will not be able to analyze it accurately.
Through the database, you can quickly diagnose the data set and find out that: too few pictures in a specific category will make it difficult for the neural network to recognize the object; The distribution of images between categories is not even enough; there are too many Google images in a specific category, resulting in a low accuracy score for that category, etc.
With a simple database, we can include the following information:
The database is indispensable for collecting data sets and statistical data Tool of. It helps us quickly and easily see how balanced the dataset is and how many high-quality images are in each category (from a neural network perspective). With data like the one visualized below, we can analyze it faster and compare it to the recognition results to find the root cause of poor accuracy
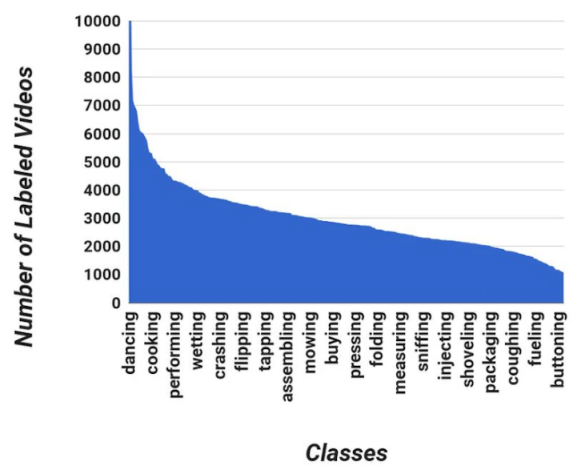
What needs to be re-written is: One issue worth noting is that the reason for the low accuracy may be due to a smaller number of images or a higher proportion of Google Photos in a certain category. By creating such a database, the time for production, testing and model retraining can be greatly reduced
As a technique used to increase the number of images, data augmentation is the simple or complex transformation of the data Processes, such as through flipping or style transformation, we can improve the validity of the data. The effective data set obtained based on this does not require excessive training. As shown in the image below, such data transformations can be as simple as simply rotating the image by 90 degrees, or as complex as adding solar flares to the image to simulate a backlit photo or lens Flare.

Typically, these enhanced conversions are automated. For example, we can prepare a Python library specifically for data augmentation. Currently, there are two types of data augmentation:
It is worth noting that increasing the size of the data set ten times does not make the neural network ten times more efficient. In fact, this may actually make the network perform worse than before. Therefore, we should only use enhancements that are relevant to production environments. For example, a camera installed in a building will not be exposed to rain when it is operating normally. So there is absolutely no need to add "rain" enhancement to the image.
Although for those looking to apply AI to business, the dataset is The least exciting part. But it is undeniable that data sets are an important part of any image recognition project. Moreover, in most image recognition projects, the management and organization of data sets often takes a lot of time from the team. Finally, let’s summarize how you can get the best results from your AI projects by properly handling your datasets:
Julian Chen, 51CTO community editor, has more than ten years of IT experience Project implementation experience, good at managing and controlling internal and external resources and risks, and focusing on disseminating network and information security knowledge and experience.
Original title: 7 Steps To Prepare A Dataset For An Image-Based AI Project by Oleg Kokorin
The above is the detailed content of Seven Steps to Prepare Datasets for Image AI Projects. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



