


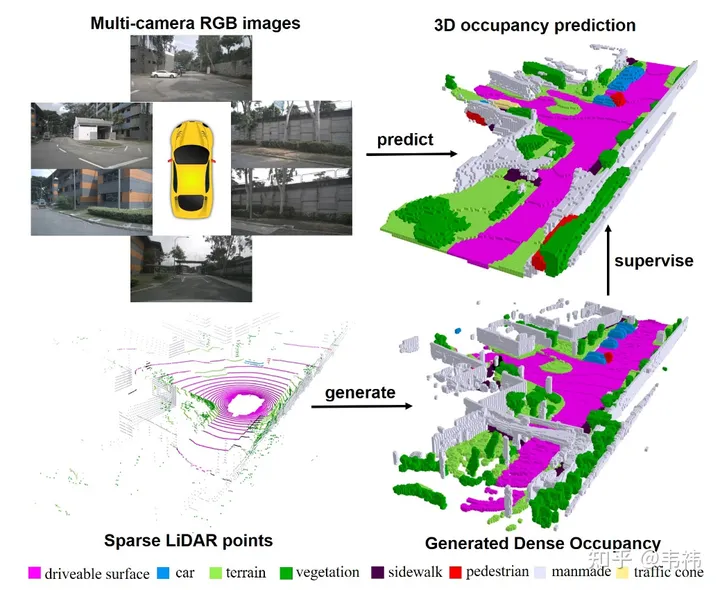
In this work, we constructed a dense occupancy raster dataset through multi-frame point clouds and designed a three-dimensional occupancy raster network based on the transformer's 2D-3D Unet structure. We are honored that our article has been included in ICCV 2023. The project code is now open source and everyone is welcome to try it.

arXiv: https://arxiv.org/pdf/2303.09551.pdf
Code: https://github.com/weiyithu/SurroundOcc
Homepage link: https://weiyithu.github.io/SurroundOcc/
I have been looking for a job like crazy recently and have no time to write. I just recently submitted camera-ready as a working person. In the end, I thought it would be better to write a Zhihu summary. In fact, the introduction of the article is already well written by various public accounts, and thanks to their publicity, you can directly refer to the Heart of Autonomous Driving: nuScenes SOTA! SurroundOcc: Pure visual 3D occupancy prediction network for autonomous driving (Tsinghua & Tianda). In general, the contribution is divided into two parts. One part is how to use multi-frame lidar point clouds to build a dense occupancy data set, and the other part is how to design a network for occupancy prediction. In fact, the contents of both parts are relatively straightforward and easy to understand. If you don’t understand anything, you can always ask me. So in this article, I want to talk about something other than the thesis. One is how to improve the current solution to make it easier to deploy, and the other is the future development direction.
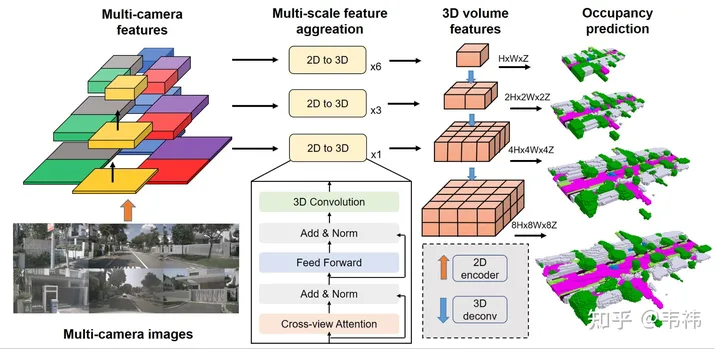
Whether a network is easy to deploy mainly depends on whether it is difficult to deploy. Operators implemented on the board end, the two more difficult operators in the SurroundOcc method are the transformer layer and 3D convolution.
The main function of the transformer is to convert 2D features into 3D space. In fact, this part can also be implemented using LSS, Homography or even mlp, so this part of the network can be modified according to the implemented solution. But as far as I know, the transformer solution is not sensitive to calibration and has better performance among several solutions. It is recommended that those who have the ability to implement transformer deployment should use the original solution.
For 3D convolution, you can replace it with 2D convolution. Here you need to reshape the original 3D feature of (C, H, W, Z) into (C* Z, H, W) 2D feature, then you can use 2D convolution for feature extraction. In the final occupancy prediction step, it is reshaped back to (C, H, W, Z) and supervised. On the other hand, skip connection consumes more video memory due to its larger resolution. During deployment, it can be removed and only the minimum resolution layer will be left. Our experiments found that these two operations in 3D convolution will have some drop points on nuscenes, but the scale of the industry's data set is much larger than nuscenes. Sometimes some conclusions will change, and the drop points should be less or even none.
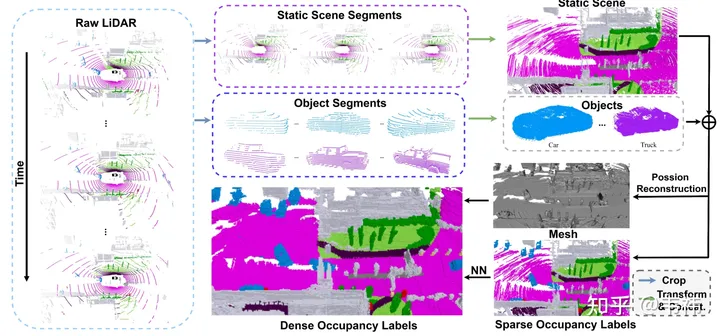
In terms of dataset construction, the most time-consuming step is Poisson reconstruction. We use the nuscenes data set, which uses 32-line lidar for collection. Even when using multi-frame stitching technology, we found that there are still many holes in the stitched point cloud. Therefore, we employed Poisson reconstruction to fill these holes. However, many lidar point clouds currently used in the industry are relatively dense, such as M1, RS128, etc. Therefore, in this case, the Poisson reconstruction step can be omitted to speed up the construction of the data set
On the other hand, SurroundOcc uses the three-dimensional target detection frame marked in nuscenes to combine the static scene and Dynamic objects are separated. However, in actual application, autolabel, which is a large three-dimensional target detection & tracking model, can be used to obtain the detection frame of each object in the entire sequence. Compared with manually annotated labels, the results produced by using large models will definitely have some errors. The most direct manifestation is the phenomenon of ghosting after splicing multiple frames of objects. But in fact, occupation does not have such high requirements for the shape of objects. As long as the position of the detection frame is relatively accurate, it can meet the requirements.
The current method still relies on lidar to provide occupancy supervision signals, but many cars, especially some low-level assisted driving cars, do not have lidar. These cars A large amount of RGB data can be returned through shadow mode, so a future direction is whether we can only use RGB for self-supervised learning. A natural solution is to use NeRF for supervision. Specifically, the front backbone part remains unchanged to obtain an occupancy prediction, and then voxel rendering is used to obtain the RGB from each camera perspective, and the loss is done with the true value RGB in the training set. Create a supervisory signal. But it is a pity that this straightforward method did not work very well when we tried it. The possible reason is that the range of the outdoor scene is too large, and the nerf may not be able to hold it, but it is also possible that we have not adjusted it properly. You can try it again. .
The other direction is timing & occupation flow. In fact, occupation flow is far more useful for downstream tasks than single-frame occupation. During ICCV, we didn’t have time to compile the data set of occupation flow, and when we published the paper, we had to compare many flow baselines, so we didn’t work on it at that time. For timing networks, you can refer to the solutions of BEVFormer and BEVDet4D, which are relatively simple and effective. The difficult part is still the flow data set. General objects can be calculated using the three-dimensional target detection frame of sequence, but special-shaped objects such as small animal plastic bags may need to be annotated using the scene flow method.

The content that needs to be rewritten is: Original link: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
The above is the detailed content of SurroundOcc: Surround 3D occupancy grid new SOTA!. For more information, please follow other related articles on the PHP Chinese website!
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 How to use the choose function
How to use the choose function
 Detailed explanation of setinterval
Detailed explanation of setinterval
 oracle insert usage
oracle insert usage
 What are the development tools?
What are the development tools?
 rgb to hexadecimal conversion
rgb to hexadecimal conversion
 What to do if the remote desktop cannot connect
What to do if the remote desktop cannot connect
 Self-study for beginners in C language with zero foundation
Self-study for beginners in C language with zero foundation








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



