


The diffusion model has become a mainstream text-to-image generation model, which can guide the generation of high-quality and content-rich images through text prompts
If the input prompts are too Simplicity, existing models have limitations in semantic understanding and common sense reasoning, which will lead to a significant decrease in the quality of the generated images
Lin Liang’s team from the HCP Laboratory of Sun Yat-sen University proposed a A simple yet effective fine-tuning method called SUR-adapter is designed to improve the model's ability to understand narrative cues. This method is a semantic understanding and inference adapter for pre-trained diffusion models and is parameter-efficient

Please click the link below View the paper: https://arxiv.org/abs/2305.05189
Open source address: https://github.com/Qrange-group/SUR-adapter
To achieve this goal, the researchers first collected and annotated a dataset called SURD. This dataset contains over 57,000 multi-modal samples, each containing a simple narrative prompt, a complex keyword-based prompt, and a high-quality image
Researchers align the semantic representation of narrative prompts with complex prompts and transfer the knowledge of large language models (LLM) to SUR adapters through knowledge distillation to be able to obtain strong semantic understanding and reasoning capabilities to build high-quality texts Semantic representations for text-to-image generation. Then, they aligned the semantic representation of the narrative prompts with the complex prompts and transferred the knowledge of the large language model (LLM) to the SUR adapter through knowledge distillation to be able to obtain strong semantic understanding and reasoning capabilities to build high-quality textual semantic representations. For text-to-image generation

We experimented by integrating multiple LLMs and pre-trained diffusion models and found that this method can effectively make the diffusion model Understand and reason about concise natural language descriptions without degrading image quality
This approach can make text-to-image diffusion models easier to use, provide a better user experience, and further Advancing the development of user-friendly text-to-image generative models and bridging the semantic gap between simple narrative prompts and keyword-based prompts
Currently, the text-to-image pre-training model represented by stable diffusion has become one of the most important basic models in the field of artificial intelligence generated content, playing an important role in tasks such as image editing, video generation, and 3D object generation. Important role
At present, the semantic ability of these pre-trained diffusion models mainly depends on the text encoder (such as CLIP), and its semantic understanding ability directly affects the generation effect of the diffusion model
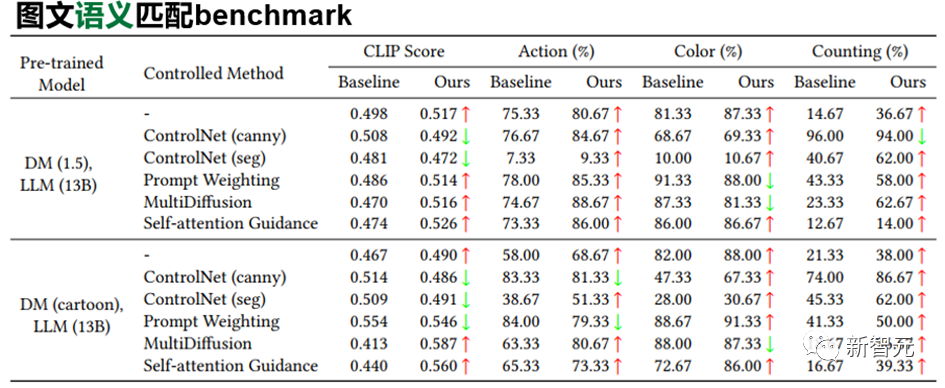
This article first tests the image-text matching accuracy of Stable diffusion by constructing common question categories in the visual question answering task (VQA), such as "counting", "color" and "action". We will manually count and conduct testing
The following are examples of constructing various prompts, see the table below for details

According to the results shown in the table below, the article reveals that the current Vincent graph pre-trained diffusion model has serious semantic understanding problems. The image-text matching accuracy of a large number of questions is less than 50%, and even in some questions, the accuracy is only 0%

In order to obtain matching text To generate conditioned images, we need to find ways to enhance the semantic capabilities of our encoder in the pre-trained diffusion model
Rewritten content: 1. Data preprocessing
First, we can start from the commonly used diffusion model online websites lexica.art, civitai.com and stablediffusionweb Get a large number of image-text pairs. Then, we need to clean and filter these data to obtain more than 57,000 high-quality triplet data (including complex prompts, simple prompts, and pictures) and form it into a SURD dataset
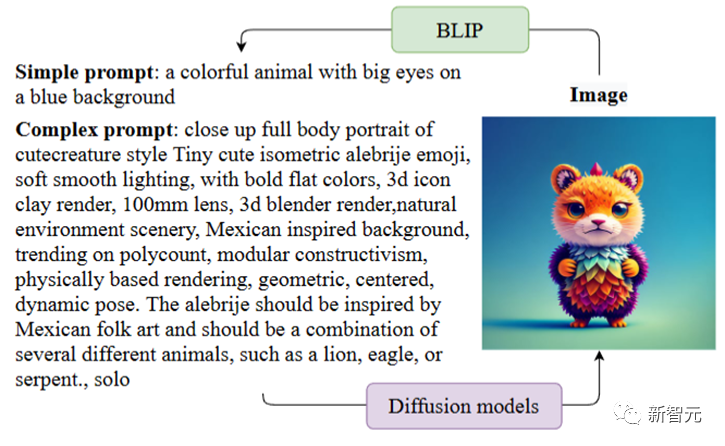
As shown in the figure below, complex prompts refer to the text prompt conditions required by the diffusion model when generating images. Usually these prompts have complex formats and descriptions. A simple prompt is a text description of an image generated through BLIP. It uses a language format that is consistent with human description
Generally speaking, a simple prompt that is consistent with normal human language description is difficult for the diffusion model to generate Images that are semantically adequate, and complex cues (what users jokingly call the diffusion model's "mantra") can achieve satisfactory results
#What needs to be rewritten is :2. Semantic distillation of large language models
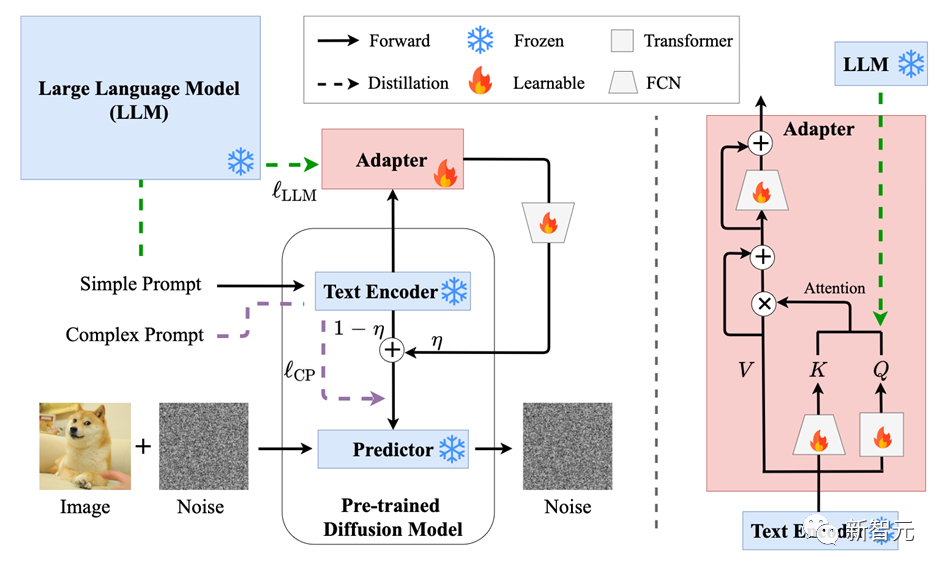
This article introduces a method of using the Adapter of the Transformer structure to distill the semantic features of large language models in specific hidden layers. And by linearly combining the large language model information guided by the Adapter with the semantic features output by the original text encoder, the final semantic features are obtained
The large language model uses LLaMA of different sizes model, and the parameters of the UNet part of the diffusion model are frozen during the entire training process
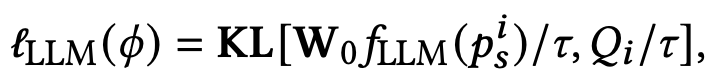
The content that needs to be rewritten is :3. Image quality restoration
In order to keep the original meaning unchanged, the content needs to be rewritten into Chinese: Since the structure of this article introduces learnable modules in the pre-training large model inference process, it destroys the original image generation quality of the pre-training model to a certain extent. Therefore, it is necessary to bring the quality of image generation back to the generation quality level of the original pre-training model
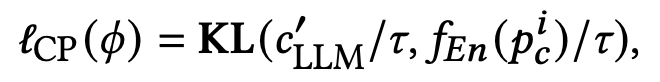
This paper uses triples in the SURD dataset and introduces the corresponding quality loss function during the training process to restore the quality of image generation. Specifically, this article hopes that the semantic features obtained through the new module can be as aligned as possible with the semantic features of complex cues
The following figure shows the effect of SUR-adapter on the pre-trained diffusion model fine-tuning framework. The right side is the network structure of the Adapter
##For SUR-adapter Performance, this article analyzes the performance from two aspects: semantic matching and image quality
On the one hand, according to the following table, SUR-adapter can effectively solve common semantics in the Vincentian graph diffusion model Mismatch problem,applicable to different experimental settings. Under different categories of semantic criteria, the accuracy has also been improved to a certain extent
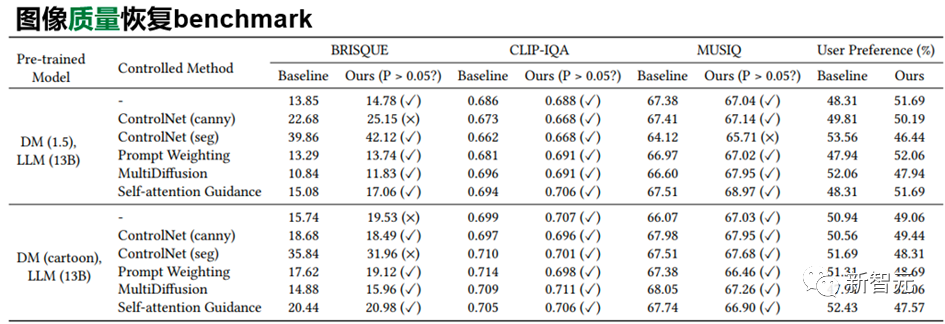
On the other hand, this paper uses common image quality evaluation indicators such as BRISQUE to compare the original pretrain diffusion model and After using the SUR-adapter diffusion model to perform statistical tests on the quality of the images generated, we can find that there is no significant difference between the two.
We also conducted a human preference questionnaire test
Through the above analysis, it can be concluded that the proposed method can Alleviating the inherent image-text mismatch problem from pre-trained text to image while maintaining the quality of image generation
We can also demonstrate qualitatively through the following image generated examples. For more detailed analysis and details, please refer to this article and the open source warehouse
The content that needs to be rewritten is:


Professor Lin Liang founded Sun Yat-sen University’s Human-Machine-Object Intelligent Fusion Laboratory (HCP Lab) in 2010. In recent years, the laboratory has achieved rich academic results in the fields of multimodal content understanding, causal and cognitive reasoning, and embodied intelligence. The laboratory has won many domestic and foreign science and technology awards and best paper awards, and is committed to developing product-level artificial intelligence technology and platforms
The above is the detailed content of Simplify Vincent diagram prompt, LLM model generates high-quality images. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



