Remove and get the first element of the list, if the list has no elements it will block The list waits until it times out or the element is popped.
##BRPOP key1 [key2 ] timeout
##Move out and Get the
last element of the list. If there is no element in the list, the list will be blocked until the wait times out or a pop-up element is found.
BRPOPLPUSH source destination timeout
pop from list A value that inserts the popped element into another list and returns it; if the list has no elements, the list will be blocked until the wait times out or a popupable element is found.
LIndex key index
通过索引获取列表中的元素
Linsert key before/after pivot value
在列表的元素前或者后插入元素
LLEN key
获取列表长度
LPOP key
移出并获取列表的第一个元素
##LPUSH key value1,value2,…
will One or more values are inserted into the head of the list
LPUSHX key value
Insert a value into the head of an existing list
##LRANGE key srart stop
Get the elements within the specified range of the list
##LREM key count value
Remove list element
##LSET key index value
Set the value of a list element by index
LTRIM key start stop
Pruning a list means that only the elements within the specified range are retained in the list, and the elements that are not within the specified range are deleted. The index starts from 0, and the range is inclusive.
RPOP key
remove listThe last element, the return value is the removed element
RPOPPUSH source destination
Remove the last element of the list and replace The element is added to another list and returns
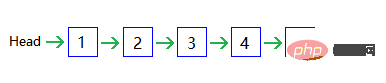
Before learning the list implementation of redis, let’s first take a look at how to implement a singly linked list:
Each one The nodes have a backward pointer (reference) pointing to the next node, the last node points to NULL to indicate the end, and there is a Head (head) pointer pointing to the first node to indicate the start.
##Similar to this, although new creation and deletion only require O(1) , but the search requires O(n) time; the reverse search is not possible, and you need to start from the beginning if you miss it.
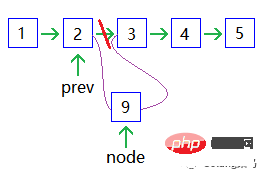
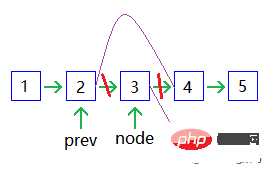
Add a node:
Delete a node:
##Doubly linked list
Doubly linked list, also called doubly linked list, is a type of linked list. Each data node has two pointers, pointing to the direct successor and direct predecessor respectively. Therefore, starting from any node in the doubly linked list, you can easily access its predecessor nodes and successor nodes.
Features:
Every time you insert or delete When selecting a certain node, four node references need to be processed instead of two. It is more difficult to implement
Compared with a one-way linked list, it will inevitably occupy memory The space is larger.
You can traverse from the beginning to the end, and you can traverse from the end to the beginning
This seems to solve the problem of redis being able to traverse both before and after.
Then let’s take a look at how redis’s linked list is processed:
Let’s take a look at its structure definition source code
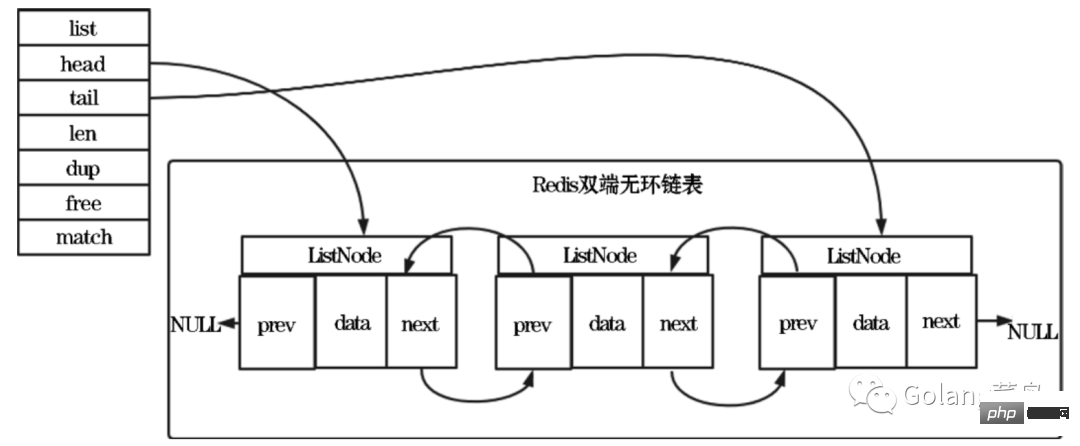
Bidirectional acyclic: linked list nodes have predecessor and successor pointers to obtain a node's The time complexity of the predecessor and successor nodes is O(1). The predecessor pointer of the head node and the successor pointer of the tail node both point to NULL, and access to the linked list ends with NULL.
Length counter: The time complexity of obtaining the number of nodes through the len attribute of the List structure is O(1).
Since list still has a problem of discontinuous memory allocation and memory fragmentation, is there a way to optimize their memory?
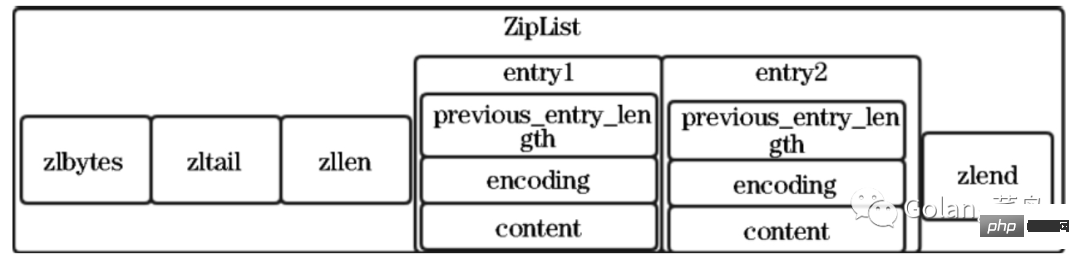
redis Compressed List
ZipList is not a basic data structure, but a data storage structure designed by Redis itself. It is somewhat similar to an array, storing data through a continuous memory space.
Different from an array, it allows the stored list elements to occupy different memory spaces. When it comes to the word compression, the first thing that everyone may think of is saving memory. The reason why this storage structure saves memory is that it is compared to arrays.
We all know that arrays require the storage space of each element to be the same size. If we want to store strings of different lengths, we must use the storage space occupied by the string with the maximum length. As the size of the storage space for each element of the string array (if it is 50 bytes).
Therefore, part of the storage space will be wasted when storing a string less than 50 bytes in character value.
The advantage of array is that it occupies a continuous space and can make good use of the CPU cache to quickly access data.
If you want to retain this advantage of the array and save storage space, then we can compress the array:
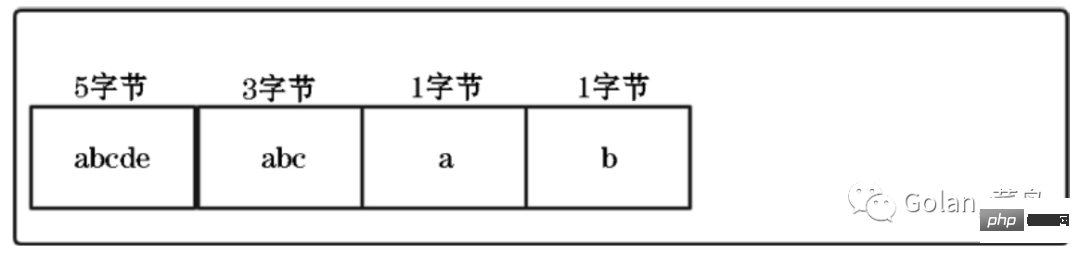
However, there is a problem. When traversing the compressed list, we do not know the memory size occupied by each element, so we cannot calculate the specific starting position of the next element.
But then I thought about it, if we could have the length of each element before accessing it, wouldn't this problem be solved?
Next let’s look at how Redis combines them by implementing ZipList to retain the advantages of arrays and save memory.
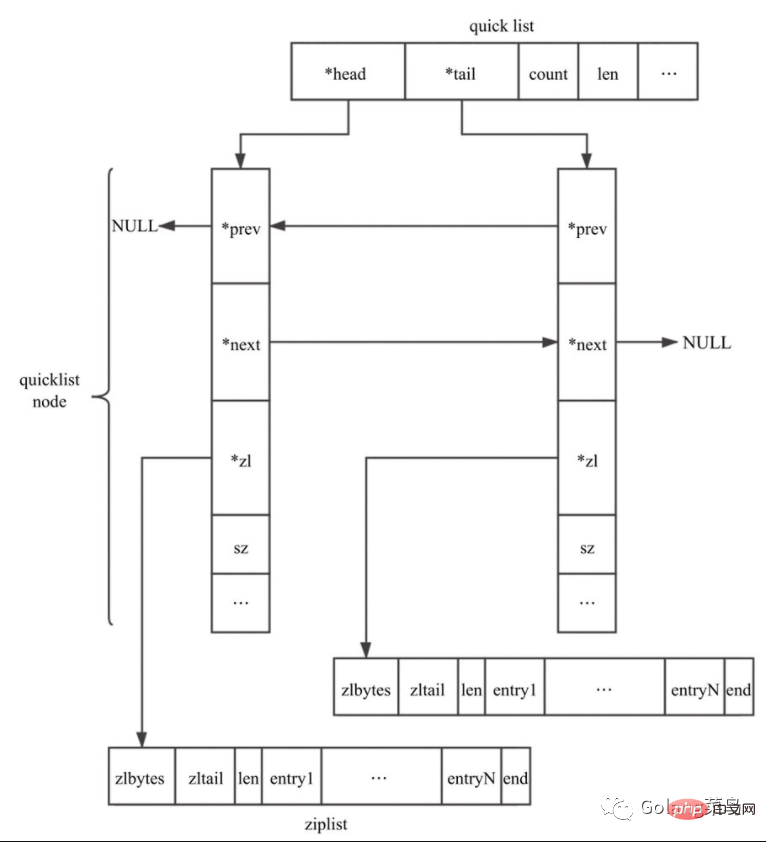
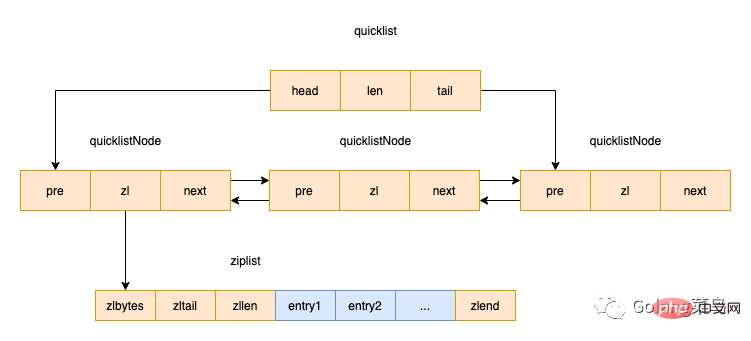
quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为A doubly linked list of ziplists。顾名思义,quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
typedef struct quicklist {
// 指向quicklist的首节点
quicklistNode *head;
// 指向quicklist的尾节点
quicklistNode *tail;
// quicklist中元素总数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNode节点个数
unsigned long len; /* number of quicklistNodes */
// ziplist大小设置,存放list-max-ziplist-size参数的值
int fill : 16; /* fill factor for individual nodes */
// 节点压缩深度设置,存放list-compress-depth参数的值
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: 4;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;
Copy after login
quicklistNode定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
##There is 1 on each end of the quicklist The nodes are not compressed, the middle nodes are compressed
2
There are 2 nodes at both ends of the quicklist that are not compressed, and the nodes in the middle are compressed
n
There are n nodes at both ends of the quicklist that are not compressed, and the nodes in the middle are compressed
There is also a fill field, which means the maximum capacity of each quicknode node, different values have different meanings, the default is -2, of course it can also be configured to other values;
##list-max-ziplist-size -2
When the value is a positive number, it indicates the length of the ziplist on the quicklistNode node. For example, when this value is 5, the ziplist of each quicklistNode node contains at most 5 data items
When the value is a negative number, Indicates that the length of the ziplist on the quicklistNode node is limited according to the number of bytes. The optional values are -1 to -5.
Value
Meaning
-1
ziplist node maximum The maximum number of ziplist nodes is 4kb
##-2
8kb
-3
ziplist node maximum is 16kb
##-4
##ziplist node maximum is 32kb
-5
##The maximum ziplist node size is 64kb
Why is there configuration provided?
#The shorter the ziplist, the more memory fragments will occur, affecting storage efficiency. When a ziplist only stores one element, the quicklist degenerates into a doubly linked list.
The longer the ziplist, the more difficult it is to allocate a large continuous memory space for the ziplist. The larger the value, the more small blocks of memory space will be wasted. When the quicklist has only one node and all elements are stored in a ziplist, the quicklist degenerates into a ziplist.
Conclusion
Although we do not fully understand its source code, we can also familiarize ourselves with a design idea of redis through this article. And know how it is optimized step by step. Let's get a general idea of performance.
The above is the detailed content of redis study notes-list principle. For more information, please follow other related articles on the PHP Chinese website!
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn

 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis











![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



