

This article discusses themain zero-copy technologiesin Linux and theapplicable scenariosof zero-copy technology. In order to quickly establish the concept of zero copy, we introduce a commonly used scenario:
in When writing a server-side program (Web Server or file server), file downloading is a basic function. At this time, the task of the server is to send the files in the server host disk from the connected socket without modification. We usually use the following code to complete:
while((n = read(diskfd, buf, BUF_SIZE)) > 0) write(sockfd, buf , n);
Basic operation It is to read the file content from the disk to the buffer in a loop, and then send the buffer content to the socket. However, Linux I/O operations default to buffered I/O. The two main system calls used here are read and write. We don't know what the operating system does in them. In fact, multiple data copies occurred during the above I/O operations.
When an application accesses a certain piece of data, the operating system will first check whether the file has been accessed recently and whether the file content is cached in the kernel buffer. If so, the operating system Directly based on the buf address provided by the read system call, copy the contents of the kernel buffer to the user space buffer specified by buf. If not, the operating system first copies the data on the disk to the kernel buffer. This step currently mainly relies on DMA for transmission, and then copies the contents of the kernel buffer to the user buffer.
Next, the write system call copies the contents of the user buffer to the kernel buffer related to the network stack, and finally the socket sends the contents of the kernel buffer to the network card. Having said so much, let’s look at the picture to make it clearer:
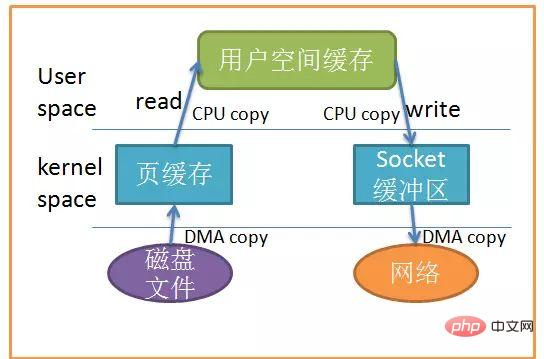
Data copy
从上图中可以看出,共产生了四次数据拷贝,即使使用了DMA来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。
我们继续回到引文中的例子,我们如何减少数据拷贝的次数呢?一个很明显的着力点就是减少数据在内核空间和用户空间来回拷贝,这也引入了零拷贝的一个类型:
让数据传输不需要经过 user space。
我们减少拷贝次数的一种方法是调用mmap()来代替read调用:
buf = mmap(diskfd, len); write(sockfd, buf, len);
应用程序调用mmap(),磁盘上的数据会通过DMA被拷贝的内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用write(),操作系统直接将内核缓冲区的内容拷贝到socket缓冲区中,这一切都发生在内核态,最后,socket缓冲区再把数据发到网卡去。同样的,看图很简单:
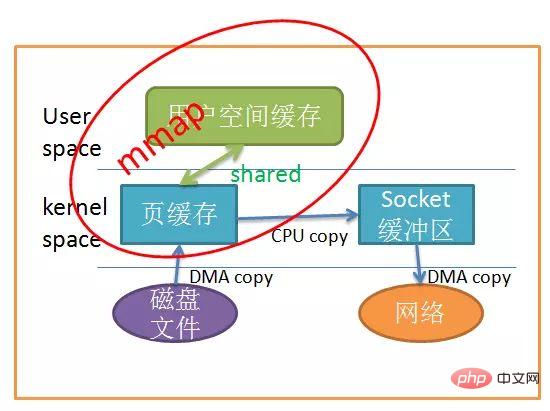
mmap
Using mmap instead of read obviously reduces one copy. When the amount of copied data is large, It undoubtedly improves efficiency. But using mmap comes at a cost. When you use mmap, you may encounter some hidden pitfalls. For example, when your program maps a file, but when the file is truncated (truncate) by another process, the write system call will be terminated by the SIGBUS signal because it accesses an illegal address. The SIGBUS signal will kill your process by default and generate a coredump. If your server is stopped in this way, it will cause a loss.
Usually we use the following solutions to avoid this problem:
1. Create a signal handler for the SIGBUS signal
When the SIGBUS signal is encountered, the signal handler simply returns, the write system call will return the number of bytes written before being interrupted, and errno will be set to success, but this is a Bad approach because you're not addressing the real core of the problem.
2. Use file lease locks
Usually we use this method to use lease locks on file descriptors. The kernel applies for a lease lock. When other processes want to truncate the file, the kernel will send us a real-time RTSIGNALLEASE signal, telling us that the kernel is destroying the read-write lock you have placed on the file. In this way, your write system call will be interrupted before the program accesses illegal memory and is killed by SIGBUS. write will return the number of bytes written and set errno to success.
We should lock the mmap file before and unlock it after operating the file:
if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1) { perror("kernel lease set signal"); return -1; } /* l_type can be F_RDLCK F_WRLCK 加锁*/ /* l_type can be F_UNLCK 解锁*/ if(fcntl(diskfd, F_SETLEASE, l_type)){ perror("kernel lease set type"); return -1; }
从2.1版内核开始,Linux引入了sendfile来简化操作:
#includessize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
系统调用sendfile()在代表输入文件的描述符infd和代表输出文件的描述符outfd之间传送文件内容(字节)。描述符outfd必须指向一个套接字,而infd指向的文件必须是可以mmap的。这些局限限制了sendfile的使用,使sendfile只能将数据从文件传递到套接字上,反之则不行。
使用sendfile不仅减少了数据拷贝的次数,还减少了上下文切换,数据传送始终只发生在kernel space。
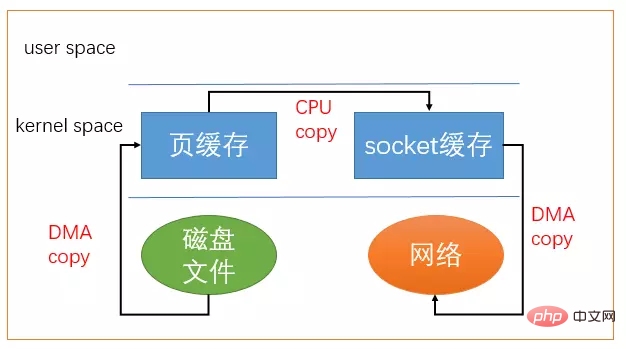
sendfile系统调用过程
在我们调用sendfile时,如果有其它进程截断了文件会发生什么呢?假设我们没有设置任何信号处理程序,sendfile调用仅仅返回它在被中断之前已经传输的字节数,errno会被置为success。如果我们在调用sendfile之前给文件加了锁,sendfile的行为仍然和之前相同,我们还会收到RTSIGNALLEASE的信号。
目前为止,我们已经减少了数据拷贝的次数了,但是仍然存在一次拷贝,就是页缓存到socket缓存的拷贝。那么能不能把这个拷贝也省略呢?
借助于硬件上的帮助,我们是可以办到的。之前我们是把页缓存的数据拷贝到socket缓存中,实际上,我们仅仅需要把缓冲区描述符传到socket缓冲区,再把数据长度传过去,这样DMA控制器直接将页缓存中的数据打包发送到网络中就可以了。
总结一下,sendfile系统调用利用DMA引擎将文件内容拷贝到内核缓冲区去,然后将带有文件位置和长度信息的缓冲区描述符添加socket缓冲区去,这一步不会将内核中的数据拷贝到socket缓冲区中,DMA引擎会将内核缓冲区的数据拷贝到协议引擎中去,避免了最后一次拷贝。
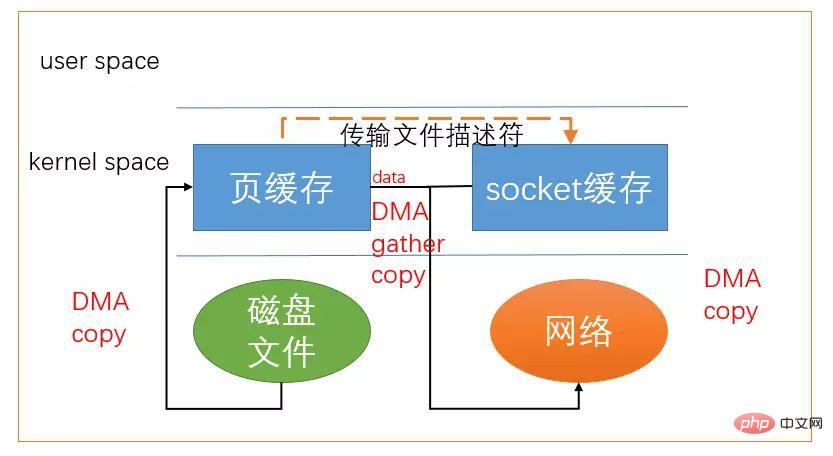
带DMA的sendfile
不过这一种收集拷贝功能是需要硬件以及驱动程序支持的。
sendfile只适用于将数据从文件拷贝到套接字上,限定了它的使用范围。Linux在2.6.17版本引入splice系统调用,用于在两个文件描述符中移动数据:
#define _GNU_SOURCE /* See feature_test_macros(7) */ #includessize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsignedint flags);
splice调用在两个文件描述符之间移动数据,而不需要数据在内核空间和用户空间来回拷贝。他从fdin拷贝len长度的数据到fdout,但是有一方必须是管道设备,这也是目前splice的一些局限性。flags参数有以下几种取值:
SPLICEFMOVE:尝试去移动数据而不是拷贝数据。这仅仅是对内核的一个小提示:如果内核不能从pipe移动数据或者pipe的缓存不是一个整页面,仍然需要拷贝数据。Linux最初的实现有些问题,所以从2.6.21开始这个选项不起作用,后面的Linux版本应该会实现。
SPLICEFNONBLOCK:splice 操作不会被阻塞。然而,如果文件描述符没有被设置为不可被阻塞方式的 I/O ,那么调用 splice 有可能仍然被阻塞。
SPLICEFMORE: There will be more data in subsequent splice calls.
The splice call uses the pipe buffer mechanism proposed by Linux, so at least one descriptor must be a pipe.
The above zero-copy technologies are all implemented by reducing the copying of data between user space and kernel space. However, sometimes, data must be copied between user space and kernel space. At this time, we can only work on the timing of data copying in user space and kernel space. Linux usually uses copy on write to reduce system overhead. This technology is often called COW.
Due to space reasons, this article does not introduce copy-on-write in detail. The general description is: if multiple programs access the same piece of data at the same time, then each program has a pointer to this piece of data. From the perspective of each program, it owns this piece of data independently. Only when the program needs to When the data content is modified, the data content will be copied to the program's own application space. Only then will the data become the program's private data. If the program does not need to modify the data, then it never needs to copy the data to its own application space. This reduces data copying. The content copied while writing can be used to write another article. . .
In addition, there are some zero-copy technologies. For example, adding the O_DIRECT mark to traditional Linux I/O can directly I/O, avoiding automatic caching. There are also some Mature fbufs technology. This article has not covered all zero-copy technologies. It only introduces some common ones. If you are interested, you can study it yourself. Generally, mature server projects will also transform the I/O-related parts of the kernel to improve their own data. Transmission rate.
The above is the detailed content of A brief analysis of zero-copy technology in Linux. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



