


The optimizer occupies a large amount of memory resources in the training of large language models.
Now there is a new optimization method that reduces memory consumption by half while maintaining performance.
This result was created by the National University of Singapore. It won the Outstanding Paper Award at the ACL conference and has been put into practical application.
 Picture
Picture
As the number of parameters of large language models continues to increase, the problem of memory consumption during training becomes more severe.
The research team proposed the CAME optimizer, which has the same performance as Adam while reducing memory consumption.
 Picture
Picture
The CAME optimizer has achieved the same or even better training performance than the Adam optimizer in the pre-training of multiple commonly used large-scale language models. And it shows stronger robustness to large batch pre-training scenarios.
Furthermore, training large language models through the CAME optimizer can significantly reduce the cost of large model training.
The CAME optimizer is improved based on the Adafactor optimizer, which often causes a loss of training performance in the pre-training tasks of large-scale language models.
The non-negative matrix decomposition operation in Adafactor will inevitably produce errors in the training of deep neural networks, and the correction of these errors is the source of performance loss.
Through comparison, it is found that when the difference between the starting value mt and the current value t is small, the confidence level of mt is higher .
 Picture
Picture
Inspired by this, the team proposed a new optimization algorithm.
The blue part in the picture below is the increased part of CAME compared to Adafactor.
 Picture
Picture
The CAME optimizer performs update amount correction based on the confidence of the model update, and at the same time performs a non-negative matrix decomposition operation on the introduced confidence matrix.
In the end, CAME successfully obtained the effect of Adam with the consumption of Adafactor.
The team used CAME to train BERT, GPT-2 and T5 models respectively.
The previously commonly used Adam (better effect) and Adafactor (lower consumption) are the references for measuring CAME performance.
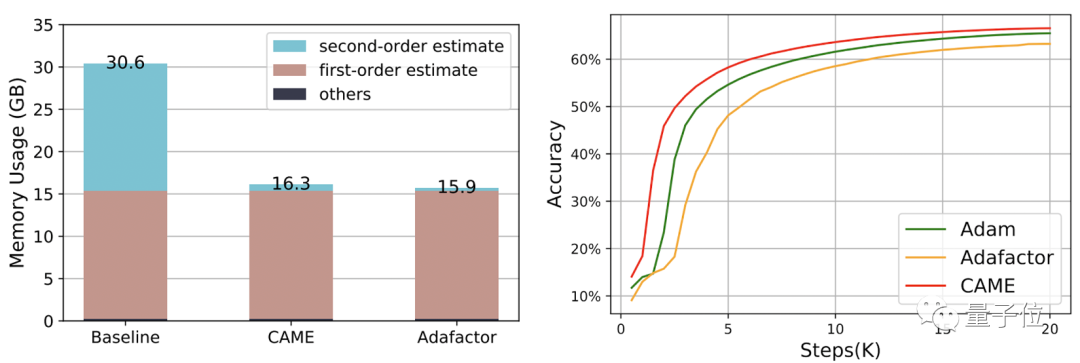
Among them, in the process of training BERT, CAME achieved the same accuracy as Adafaactor in only half the number of steps.
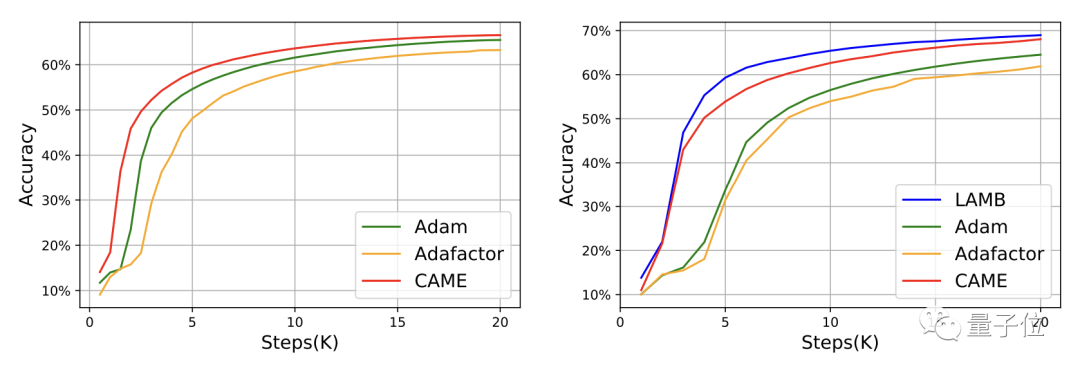 △The left side is 8K scale, the right side is 32K scale
△The left side is 8K scale, the right side is 32K scale
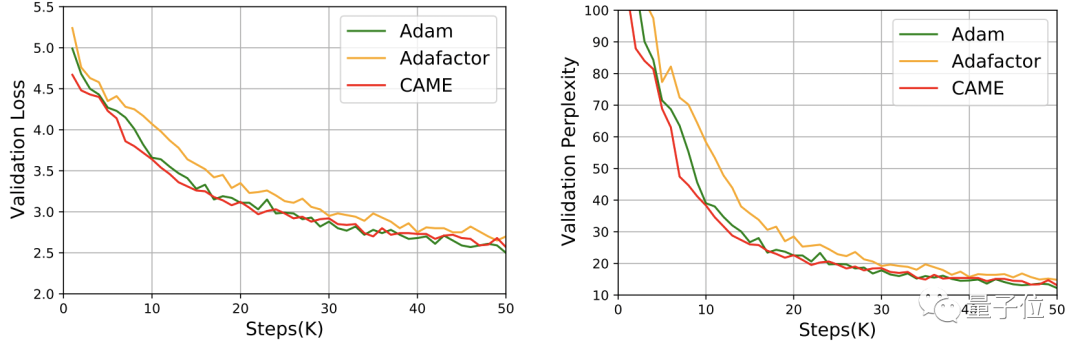
For GPT-2, from the perspective of loss and confusion, CAME’s The performance is very close to Adam.

In the training of the T5 model, CAME also showed similar results.
As for the fine-tuning of the model, CAME’s performance in accuracy is not inferior to the benchmark.
In terms of resource consumption, when using PyTorch to train BERT with 4B data volume, the memory resources consumed by CAME were reduced by nearly half compared with the baseline.
The HPC-AI Laboratory of the National University of Singapore is a high-performance computing and artificial intelligence laboratory led by Professor You Yang.
The laboratory is committed to the research and innovation of high-performance computing, machine learning systems and distributed parallel computing, and promotes applications in fields such as large-scale language models.
The head of the laboratory, You Yang, is the President Young Professor(Presidential Young Professor) of the Department of Computer Science at the National University of Singapore.
You Yang was selected into the Forbes Under 30 Elite List (Asia) in 2021 and won the IEEE-CS Supercomputing Outstanding Newcomer Award. His current research focus is on the distributed optimization of large-scale deep learning training algorithms.
Luo Yang, the first author of this article, is a master's student in the laboratory. His current research focus is on the stability and efficient training of large model training.
Paper address: https://arxiv.org/abs/2307.02047
GitHub项目页:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
The above is the detailed content of The cost of training large models has been reduced by nearly half! National University of Singapore's latest optimizer has been put into use. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



