


Current Large Language Models (LLMs) such as GPT4 exhibit excellent multi-modal capabilities in following open instructions given an image. However, the performance of these models heavily depends on the choices of network structure, training data, and training strategies, but these choices have not been widely discussed in the previous literature. In addition, there is currently a lack of suitable benchmarks to evaluate and compare these models, which limits the development of multimodal LLMs.
 Picture
Picture
In this article, the author conducts a systematic and comprehensive study on the training of such models from both quantitative and qualitative aspects. More than 20 variants were set up. For the network structure, different LLMs backbones and model designs were compared; for the training data, the impact of data and sampling strategies was studied; in terms of instructions, the effect of diverse prompts on the model's instruction following ability was explored. Influence. For benchmarks, the article first proposes an open visual question answering evaluation set Open-VQA including image and video tasks.
Based on the experimental conclusions, the author proposed Lynx, which shows the most accurate multi-modal understanding compared with the existing open source GPT4-style model capabilities while maintaining the best multi-modal generation capabilities.
Unlike typical visual language tasks, the main challenge in evaluating GPT4-style models lies in balance Performance in two aspects: text generation ability and multimodal understanding accuracy . To solve this problem, the authors propose a new benchmark Open-VQA including video and image data, and conduct a comprehensive evaluation of current open source models.
Specifically, two quantitative evaluation schemes are adopted:
In order to deeply study the training strategy of multi-modal LLMs, the author mainly starts from the network structure (prefix fine-tuning/cross-attention force), training data (data selection and combination ratio), instructions (single instruction/diversified instructions), LLMs model (LLaMA [5]/Vicuna [6]), image pixels (420/224) and other aspects are set With more than twenty variations, the following main conclusions have been drawn through experiments:
The author proposed Lynx(lynx) - a prefix-finetuning GPT4-style model with two-stage training. In the first stage, approximately 120M image-text pairs are used to align visual and language embeddings; in the second stage, 20 images or videos are used for multi-modal tasks and natural language processing (NLP) ) data to adjust the model's instruction-following capabilities.
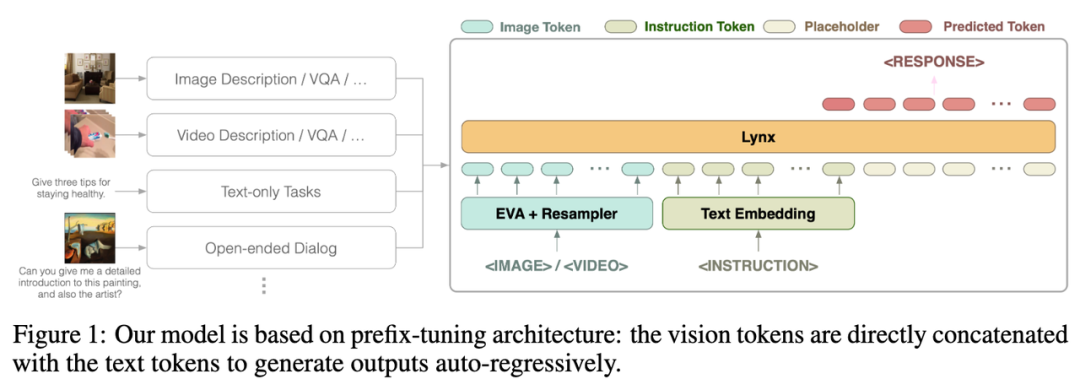 Picture
Picture
The overall structure of the Lynx model is shown in Figure 1 above.
The visual input is processed by the visual encoder to obtain visual tokens (tokens) $$W_v$$. After mapping, it is spliced with the instruction tokens $$W_l$$ as the input of LLMs. This structure is called "prefix-finetuning" in this article to distinguish it from the cross-attention structure used by Flamingo [3].
In addition, the author found that the training cost can be further reduced by adding Adapter (Adapter) after certain layers of frozen LLMs.
The author evaluated the existing open source multi-modal LLMs model in Open-VQA, Mme [4] And the performance on OwlEval manual evaluation (results are shown in the chart below, and evaluation details are in the paper). It can be seen that the Lynx model has achieved the best performance in Open-VQA image and video understanding tasks, OwlEval manual evaluation and Mme Perception tasks. Among them, InstructBLIP also achieves high performance in most tasks, but its reply is too short. In comparison, in most cases, the Lynx model provides concise reasons to support the correct answer. Reply, which makes it more user-friendly (see the Cases display section below for some cases).
1. The indicator results on the Open-VQA image test set are shown in Table 1 below:
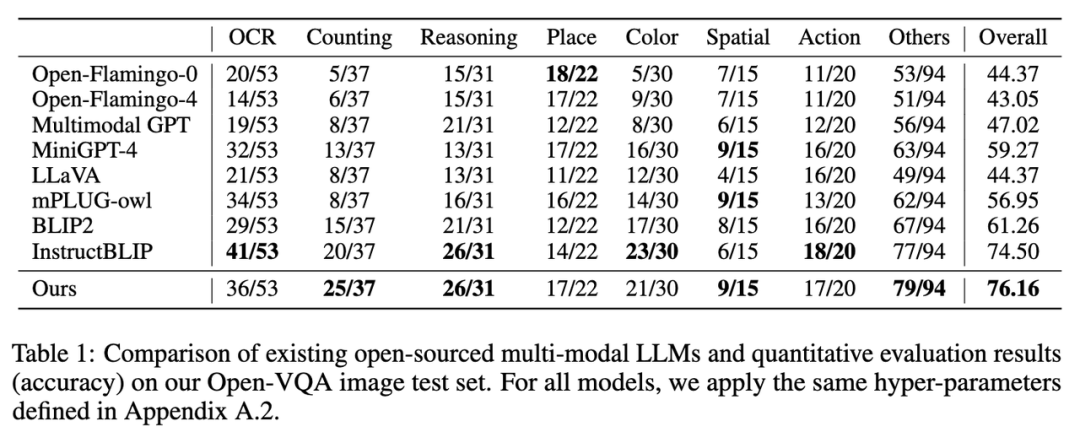 Picture
Picture
2. The indicator results on the Open-VQA video test set are shown in Table 2 below.
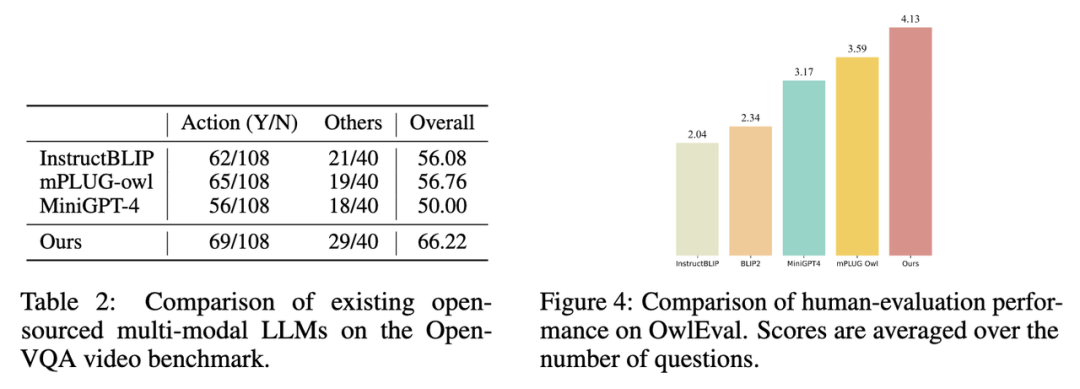 picture
picture
3. Select the model with the top score in Open-VQA to conduct manual effect evaluation on the OwlEval evaluation set. The results are shown in Figure 4 above. It can be seen from the manual evaluation results that the Lynx model has the best language generation performance.
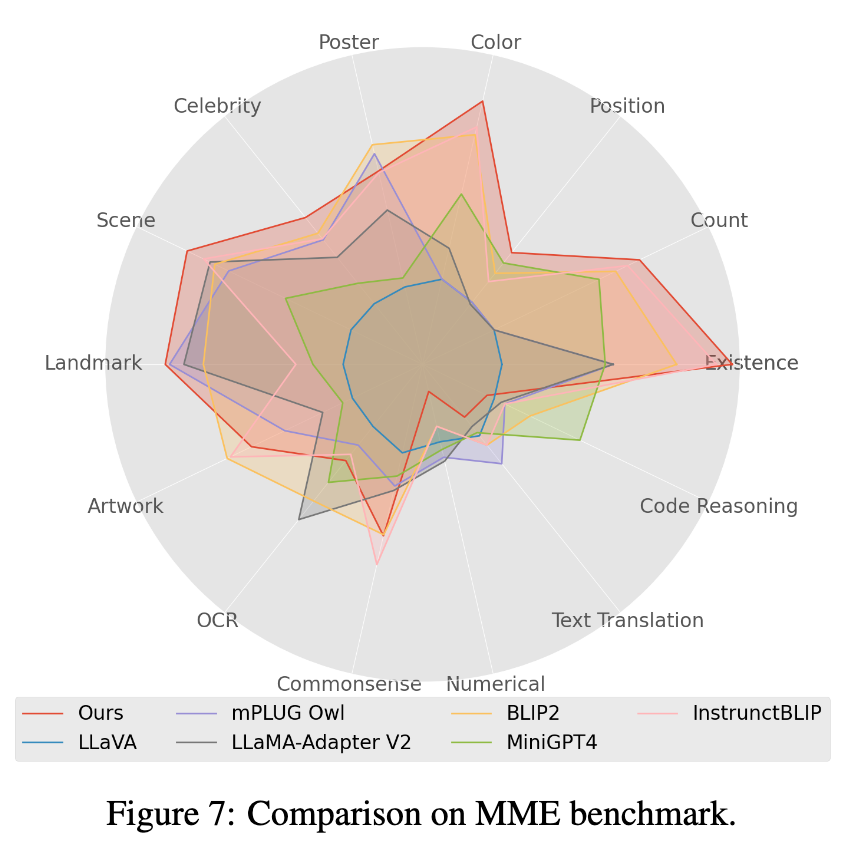 Picture
Picture
4. In the Mme benchmark test, the Perception class task achieved the best performance , among which 7 of 14 types of subtasks have the best performance. (See the appendix of the paper for detailed results)
Open-VQA picture cases

OwlEval cases

Open-VQA video case

In this article, the author determined prefix-finetuning as the Open-VQA evaluation plan for the main structure of the Lynx model and open-ended answers. Experimental results show that the Lynx model performs the most accurate multi-modal understanding accuracy while maintaining the best multi-modal generation capabilities.
The above is the detailed content of The Byte team proposed the Lynx model: multi-modal LLMs understanding cognitive generation list SoTA. For more information, please follow other related articles on the PHP Chinese website!
 What file is resource?
What file is resource?
 How to set a scheduled shutdown in UOS
How to set a scheduled shutdown in UOS
 Springcloud five major components
Springcloud five major components
 The role of math function in C language
The role of math function in C language
 What does wifi deactivated mean?
What does wifi deactivated mean?
 iPhone 4 jailbreak
iPhone 4 jailbreak
 The difference between arrow functions and ordinary functions
The difference between arrow functions and ordinary functions
 How to skip connecting to the Internet after booting up Windows 11
How to skip connecting to the Internet after booting up Windows 11








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



