



According to news on July 11, Microsoft recently issued a press release and launched the combinable diffusion model (CoDi), which is a unique artificial intelligence based on combinable diffusion. Models designed to interact and generate multimodal content.
Microsoft designed CoDi to address the limitations of traditional single-modality AI models. Taking synchronized video and audio as an example, there may be inconsistencies and alignment issues when independently generated information streams are spliced together.
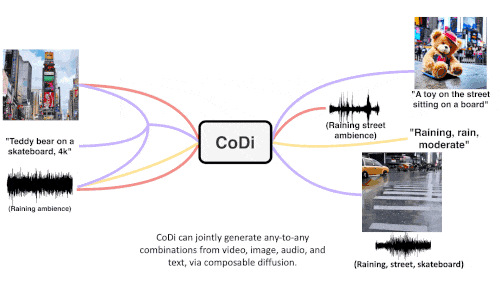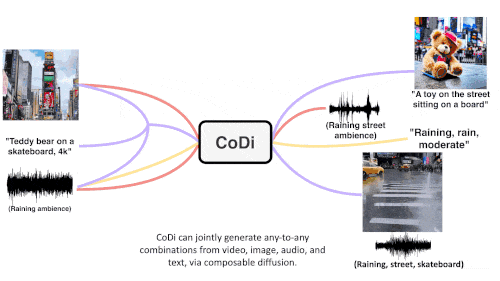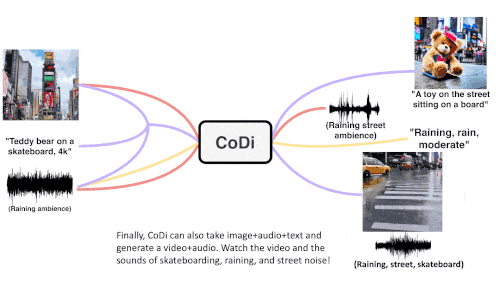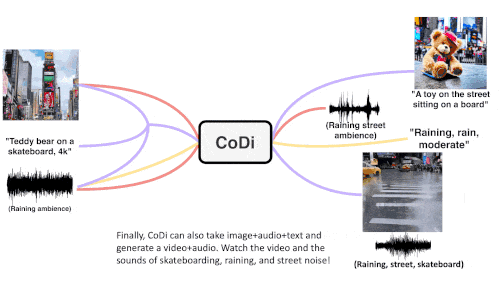
CoDi adopts a unique combinable generation strategy that aligns multiple modalities during the diffusion process to generate intertwined patterns. More importantly, CoDi is able to handle any Input patterns and generate content for arbitrary modals.
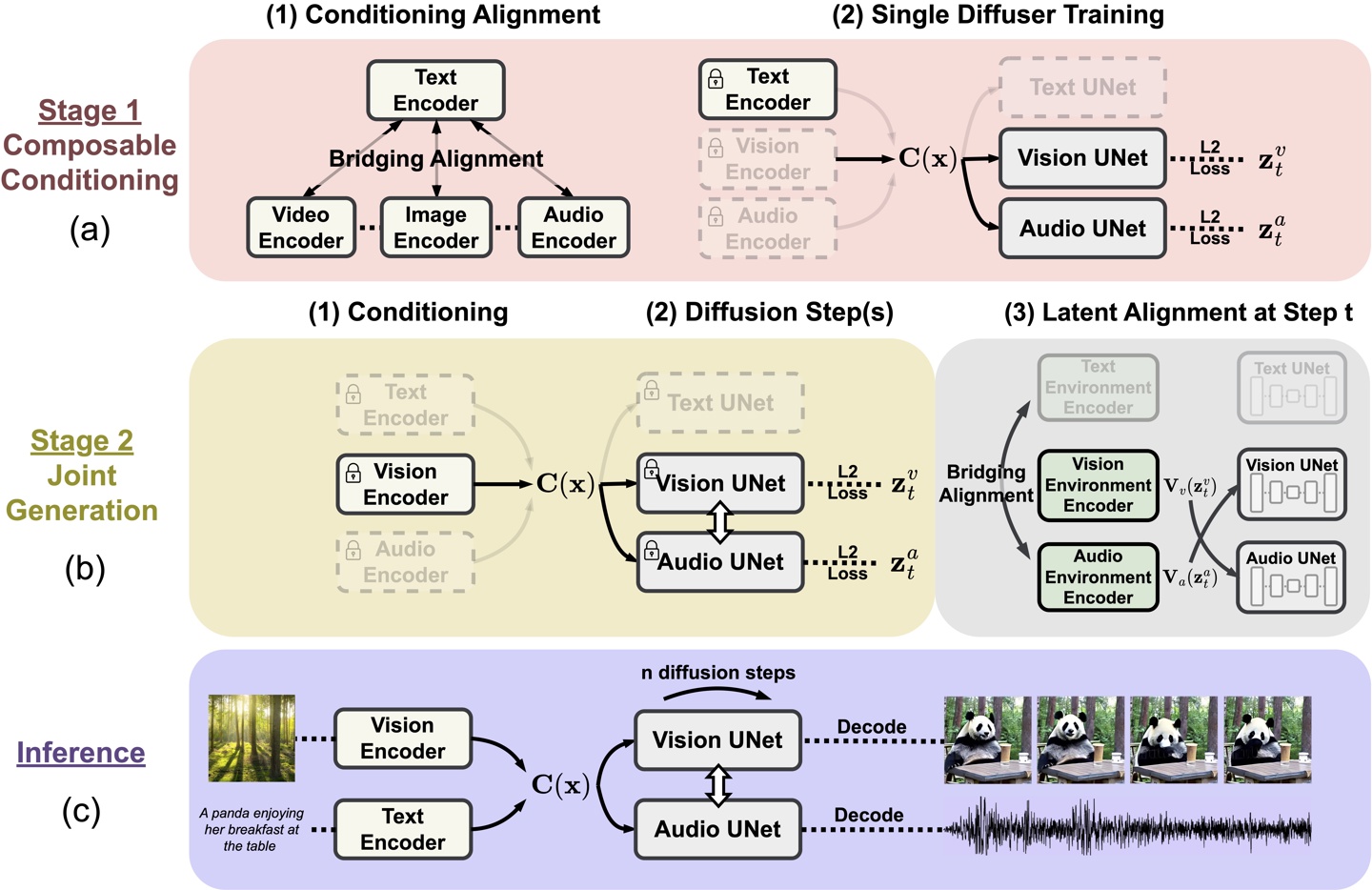
CoDi was developed by the Microsoft Azure Cognitive Services Research Team in collaboration with the University of North Carolina at Chapel Hill and is part of the Microsoft project i-Code, which uses artificial intelligence to enhance Human-computer interaction.
IT House hereby attaches the CoDi projectofficial introduction link. Interested users can read in depth.
The above is the detailed content of Microsoft launches artificial intelligence model CoDi to interact and generate multi-modal content. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



