


Text-to-image diffusion generation models, such as Stable Diffusion, DALL-E 2 and mid-journey, have been in a state of vigorous development and have strong text-to-image generation capabilities, but "overturned ” Cases will occasionally appear.
As shown in the figure below, when given a text prompt: "A photo of a warthog", the Stable Diffusion model can generate a corresponding, clear and realistic photo of a warthog. However, when we slightly modify this text prompt and change it to: "A photo of a warthog and a traitor", what about the warthog? How did it become a car?

Let’s take a look at the next few examples. What new species are these?

What causes these strange phenomena? These generation failure cases all come from a recently published paper "Stable Diffusion is Unstable":

In this paper A gradient-based adversarial algorithm for text-to-image models is proposed for the first time. This algorithm can efficiently and effectively generate a large number of offensive text prompts, and can effectively explore the instability of the Stable diffusion model. This algorithm achieved an attack success rate of 91.1% on short text prompts and 81.2% on long text prompts. In addition, this algorithm provides rich cases for studying the failure modes of text-to-image generation models, laying a foundation for research on the controllability of image generation.
Based on a large number of generation failure cases generated by this algorithm, the researcher summarized four reasons for generation failure, which are:
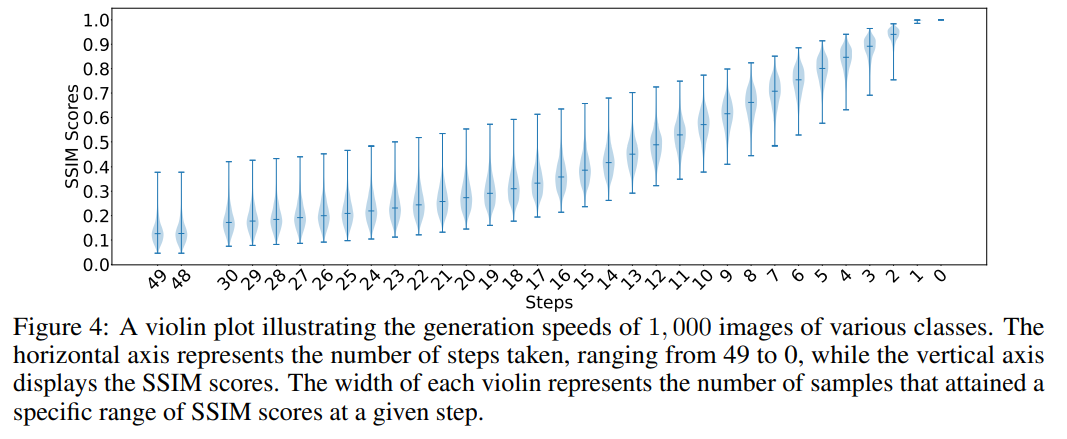
When a prompt (prompt) contains multiple generation targets, we often encounter There is an issue where a certain target disappears during the generation process. Theoretically, all targets within the same cue should share the same initial noise. As shown in Figure 4, the researchers generated one thousand category targets on ImageNet under the condition of fixed initial noise. They used the last image generated by each target as a reference image and calculated the Structural Similarity Index (SSIM) score between the image generated at each time step and the image generated at the last step to demonstrate the different targets. Differences in build speed.
In the diffusion generation process, the researcher found that when When there is global or local coarse-grained feature similarity between two types of targets, problems will arise when calculating cross attention weights. This is because the two target nouns may focus on the same block of the same picture at the same time, resulting in feature entanglement. For example, in Figure 6, feather and silver salmon have certain similarities in coarse-grained features, which results in feather being able to continue to complete its generation task in the eighth step of the generation process based on silver salmon. For two types of targets without entanglement, such as silver salmon and magician, magician cannot complete its generation task on the intermediate step image based on silver salmon.

In this chapter, researchers explore in depth what happens when a word has multiple meanings time generation. What they found was that, without any outside perturbation, the resulting image often represented a specific meaning of the word. Take "warthog" as an example. The first line in Figure A4 is generated based on the meaning of the word "warthog".

However, researchers also found that when other words are injected into the original prompt , which may cause semantic shifts. For example, when the word "traitor" is introduced in a prompt describing "warthog", the generated image content may deviate from the original meaning of "warthog" and generate entirely new content.
In Figure 10, the researcher observed an interesting phenomenon. Although from a human perspective, the prompts arranged in different orders generally have the same meaning, they are all describing a picture of a cat, clogs, and a pistol. However, for the language model, that is, the CLIP text encoder, the order of the words affects its understanding of the text to a certain extent, which in turn changes the content of the generated images. This phenomenon shows that although our descriptions are semantically consistent, the model may produce different understanding and generation results due to the different order of words. This not only reveals that the way models process language and understands semantics is different from humans, but also reminds us that we need to pay more attention to the impact of word order when designing and using such models.

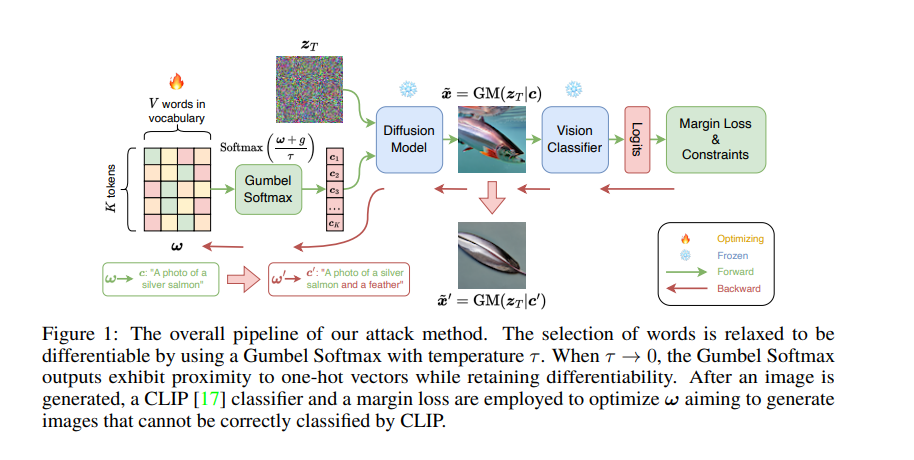
As shown in Figure 1 below, without changing the original target noun in the prompt Under the premise, the researcher continuousizes the discrete process of word replacement or expansion by learning the Gumbel Softmax distribution, thereby ensuring the differentiability of perturbation generation. After generating the image, the CLIP classifier and margin loss are used to optimize ω, aiming to generate CLIP For images that cannot be correctly classified, in order to ensure that offensive cues have a certain similarity with clean cues, researchers have further used semantic similarity constraints and text fluency constraints.
Once this distribution is learned, the algorithm is able to sample multiple text prompts with attack effects for the same clean text prompt.

# See the original article for more details.
The above is the detailed content of 'Censored' during image generation: Failure cases of stable diffusion are affected by four major factors. For more information, please follow other related articles on the PHP Chinese website!
 Basic usage of FTP
Basic usage of FTP
 Which mobile phones does Hongmeng OS support?
Which mobile phones does Hongmeng OS support?
 How to use question mark expression in C language
How to use question mark expression in C language
 What is a relational database
What is a relational database
 pci device universal driver
pci device universal driver
 Win7 prompts that application data cannot be accessed. Solution
Win7 prompts that application data cannot be accessed. Solution
 nullpointerexception exception
nullpointerexception exception
 How to set up web page automatic refresh
How to set up web page automatic refresh








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



